영상링크: https://youtu.be/EcxpbhDeuZw
Why should we worry about learning rewards?
- Imitation Learning 관점: 로봇과 다르게 사람은 모방하는 과정에서는 행동(action)을 모방하지 않고, 의도(intent)를 모방하려고 함. 이는 다양한 다른 행동을 만들어 낼 수 있음.
Inverse Reinforcement Learning
- IRL은 demonstrations으로부터 reward function을 학습하는 것을 목표로 함.

Feature matching IRL
- Linear reward function: rψ(s,a)=∑iψifi(s,a)=ψTf(s,a)
- 중요한 feature의 expectation을 매칭하는 과정
- πrψ 를 optimal policy 라고하면 원하는 것은 Eπrψ[f(s,a)]=Eπ∗[f(s,a)] 를 만족하는 ψ 를 찾는 것.
“maximum margin priciple”
ψ,mmax ms.t.ψTEπ∗[f(s,a)]≥πinΠmax ψTEπ[f(s,a)+m]
* 휴리스틱함
* 그래서 SVM으로 해결해보려고 함

Learning the Reward Function

- The optimality variable를 학습하여 reward function을 추정하자
- p(Ot∣st,at,ψ)=exp(rψ(st,at))
- demonstations from π∗(τ): {τi}
- p(τ∣O1:T,ψ)∝p(τ)exp(∑trψ(st,at)), 여기서 p(τ)는 ψ과 독립이기 때문에 생략 가능
- Maximum likelihood learning: ψmax N1∑i=1Nlogp(τi∣O1:T,ψ)=ψmax N1∑i=1Nrψ(τi)−logZ
- Z가 학습을 힘들게함
The IRL Particion function
- Z=∫p(τ)exp(∑trψ(st,at)), ψmax N1∑i=1Nrψ(τi)−logZ
- gradient: ▽ψL=N1∑i=1N▽ψrψ(τi)−Z1∫p(τ)exp(∑trψ(st,at))▽ψrψ(τ)dτ
- Z1∫p(τ)exp(∑trψ(st,at))=p(τ∣O1:T,ψ) 이기 때문에
- ▽ψL=Eτ∼π∗(τ)[▽ψrψ(τi)]−Eτ∼π∗(τ∣O1:T,ψ)[▽ψrψ(τ)]
- 앞의 항은 expert samples의 추정치이고, 뒤의 항은 현재 reward 하에서 soft optimal policy 다.
- 이를 풀어쓰면 backward message(β)와 forward message(α)와 연관시킬 수 있음
Estimating the expectation
The MaxEnt IRL algorithm1

-
필요:
- Solving for (soft) optimal policy in the inner loop
- Enumerating all state-action tuples for visitation frequency and gradient
-
단점 및 한계점:
- Large and continuous state and action spaces
- States obtained via sampling only
- Unknown dynamics
Approximations in High Dimensions
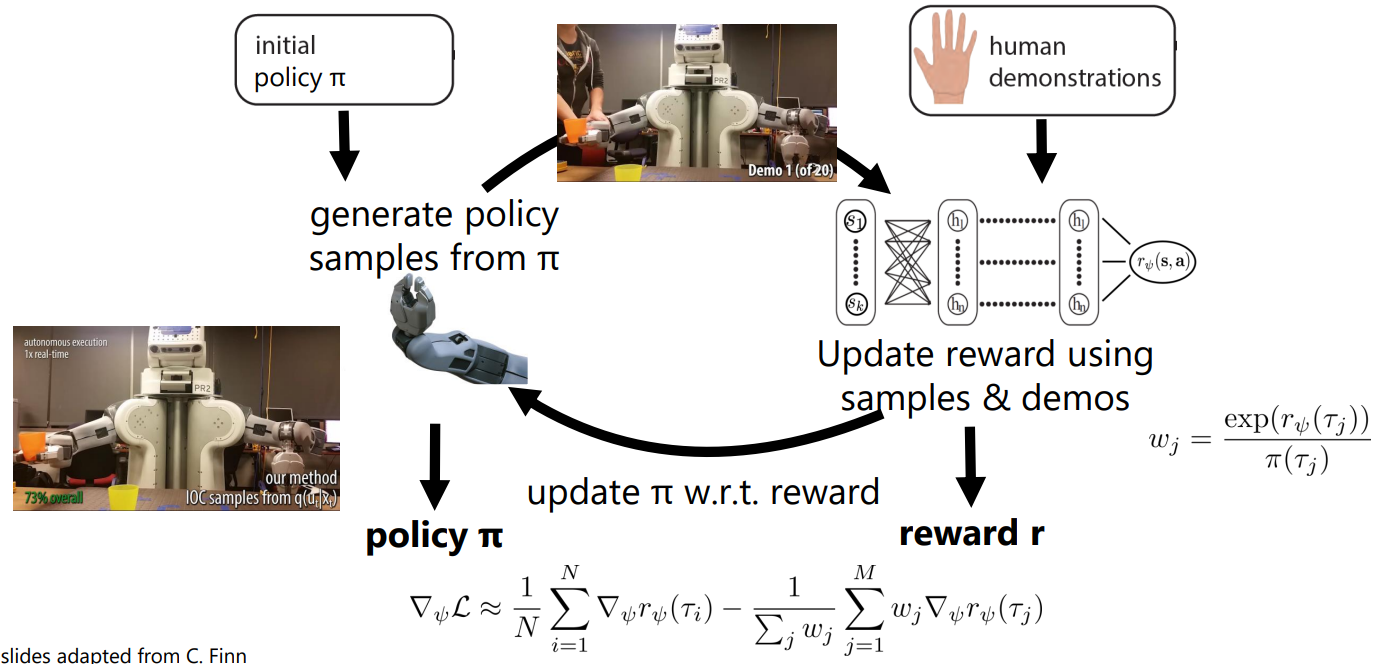
Guided cost learning algorithm2
“More efficient sample-based updates”
“Importance sampling”
- policy samples를 먼저 생성 → 사람 demonstrations과 같이 reward function을 추정 → policy를 업데이트