Locality Sensitive Hashing
Locality Sensitive Hashing(LSH)는 유사한 데이터를 빠르게 찾는 방법론이다. LSH는 데이터를 해시(hash) 함수를 통해서 해시 테이블에 저장하고, 유사한 데이터는 동일한 해시 테이블에 저장되도록 한다. 이렇게 해서 유사한 데이터를 빠르게 찾을 수 있다. LSH는 유사도 검색(Similarity Search)에서 많이 사용되며, 최근에는 벡터 데이터베이스(Vector Database)에서도 많이 사용되고 있다.
Preliminaries: MinHash & MaxHash¶
해시 함수(hash function)1는 데이터를 고정된 길이의 해시 값으로 변환하는 함수이다. 이를 활용하여 만든 것이 해시 테이블(hash table)이며, key와 value를 가진 자료구조가 된다. 해시 함수는 주로 인덱싱등에 활용이 되는데, 예를 들어 "Simon" 이라는 사람을 "01" 로 매핑하였다면 앞으로 "Simon" 이라는 사람을 찾을 때 "01"만 찾으면 된다.
만약에 비슷한 이름인데 같은 공간에 매핑이 되면, 이러한 상황을 collision이라고 한다. 보통은 collision을 최소화 하도록 해시 함수를 설계한다. 그러나 LSH는 collision을 적절하게 활용하여 비슷한 데이터를 찾는데 활용한다.
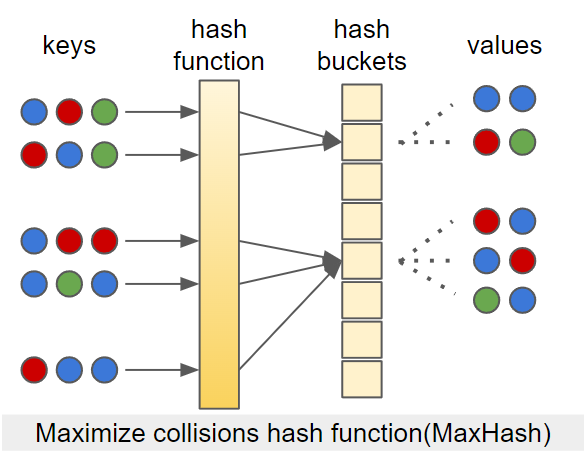
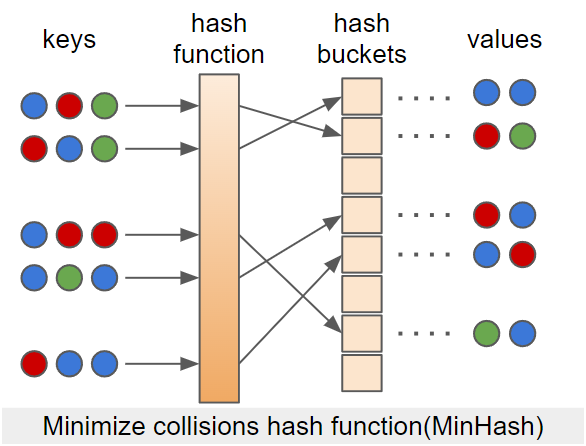
매핑된 값들이 최대한 다른 공간에 분포하도록 하는 것이 MinHash 다. 반대로 매핑된 값들이 최대한 비슷한 공간에 분포하도록 하는 것이 MaxHash 다. 이를 활용해서 비슷한 문서는 비슷한 공간에 매핑되도록 하는 것이 LSH의 핵심이다.
LSH for Similarity Search¶
아래와 같이 문서들이 있다고 하자. 우리의 목표는 각 문서별로 유사함의 정도를 측정하는 것이다.
docs = [
"flying fish flew by the space station",
"the fish was caught by the fisherman",
"soaring fish soared past the orbital station",
"cooked fish was in the space",
]
전체 프로세스는 다음과 같다(그림에는 첫 두개의 문서를 예시로 들었다).
Process

- 문장을 Shingling2(혹은 N-Gram)으로 나눈다. 고전적인 자연어 데이터 전처리 방법으로 주어진 \(K\)에 따라 문자열을 나누는 방법이다.
- 각 고유한 shingle을 단어장(Vocabulary)로 만든다.
- 각 shingle를 원-핫 인코딩(one-hot encoding)으로 변환한다.
- MinHash 함수를 적용하여 Signature를 생성한다.
- Banding method를 이용하여, LSH를 적용한다.
1. Shingling¶
Shingling은 문자열을 \(k\) 길이의 shingle set로 나누는 과정이다. 예를 들어 \(k=2\)이라면 다음과 같이 나눌 수 있다. 이 방법은 단어의 빈도수와 순서를 고려하지 않는 방법임을 유의해야 한다.
def shingling(s: str, k: int):
s = "_" + s
s = s.replace(" ", "_")
shingles = list()
for i in range(len(s) - k + 1):
shingles.append(s[i:i+k])
return shingles
두 문장의 유사도는 어떻게 될까? 이때 우리는 Jaccard 유사도를 사용할 수 있다. Jaccard 유사도는 두 집합의 교집합을 합집합으로 나눈 값으로 정의된다. 자세한 내용은 Jaccard 유사도를 참고하자.
import numpy as np
def formatting(x):
if isinstance(x, set):
x = list(x)
if not isinstance(x[0], str):
x = list(map(str, x))
return ", ".join(x[:3] + ["..."] + x[-3:])
def jaccard(x: set, y: set):
shared = x.intersection(y)
union = x.union(y)
return len(shared) / len(union)
def get_docs_similarity(docs_set: list[set]):
if not isinstance(docs_set[0], set):
docs_set = [set(x) for x in docs_set]
n_docs = len(docs_set)
docs_similarity = np.zeros((n_docs, n_docs))
for i in range(n_docs):
for j in range(i+1, n_docs):
docs_similarity[i, j] = jaccard(docs_set[i], docs_set[j])
docs_similarity[j, i] = docs_similarity[i, j]
return docs_similarity
k = 2
docs_shingling = [shingling(s, k) for s in docs]
for i, shingles in enumerate(docs_shingling):
print("doc{} = {{{}}}".format(i+1, formatting(shingles)))
# matrix jaccard similarity
docs_similarity = get_docs_similarity(docs_shingling)
print("Jaccard similarity matrix:")
print(docs_similarity.round(4))
# doc1 = {pac, fle, w_b, ..., sh_, _th, by_}
# doc2 = {_ca, ht_, erm, ..., _th, h_w, by_}
# doc3 = {e_o, tio, tal, ..., ast, sh_, _th}
# doc4 = {pac, oke, in_, ..., as_, _th, h_w}
# Jaccard similarity matrix:
# [[0. 0.1923 0.2759 0.2449]
# [0.1923 0. 0.1148 0.25 ]
# [0.2759 0.1148 0. 0.1356]
# [0.2449 0.25 0.1356 0. ]]
문서가 많아지거나 커지면, 각 문서의 크기(차원) 또한 커진다. 그래서 각 문서를 조금더 컴팩트하게 작은 차원으로 표현하고 싶다. 그러면 어떤 방법으로 유사한 문서를 유사한 공간에 매핑할 수 있을까? 다음 일련의 과정에서 이를 설명한다.
2. Vocabulary¶
Shingling을 통해서 나눈 shingle들을 단어장(Vocabulary)으로 만든다. 이때 단어장은 고유한 shingle들의 집합이며, 전체 데이터를 사용하여 만든다. 단어장은 순서가 있어야 함으로 set이 아닌 list로 만든다.
3. One-Hot Encoding¶
Shingling을 통해서 나눈 shingle들을 하나씩 대조하여 단어장에 존재하는 경우 해당 단어장 인덱스에 1을 부여한다. 이를 원-핫 인코딩(one-hot encoding)(1) 이라고 한다. 이를 통해서 단어장의 크기 \(V\) 만큼의 sparse vector를를 얻을 수 있다.
 one-hot encoding은 보통 자연어 처리에서 전체 시퀀스의 길이(=토큰의 개수 \(N\))를 단어장의 크기 \(V\) 길이 만큼 변환 하여 \(N \times V\) 의 Matrix 형태로 표현하지만, 여기서는 단어장의 크기 만큼의 벡터로 표현하는 방식이다.
one-hot encoding은 보통 자연어 처리에서 전체 시퀀스의 길이(=토큰의 개수 \(N\))를 단어장의 크기 \(V\) 길이 만큼 변환 하여 \(N \times V\) 의 Matrix 형태로 표현하지만, 여기서는 단어장의 크기 만큼의 벡터로 표현하는 방식이다.
def one_hot_encode(shingles: set, vocabulary: list[str]):
vector = [1 if token in shingles else 0 for token in vocabulary]
return vector
docs_vectors = [one_hot_encode(shingles, vocabulary) for shingles in docs_shingling]
print("The shape of doc vectors =", docs_vectors.shape)
# The shape of doc vectors = (4, 86)
4. Signature¶
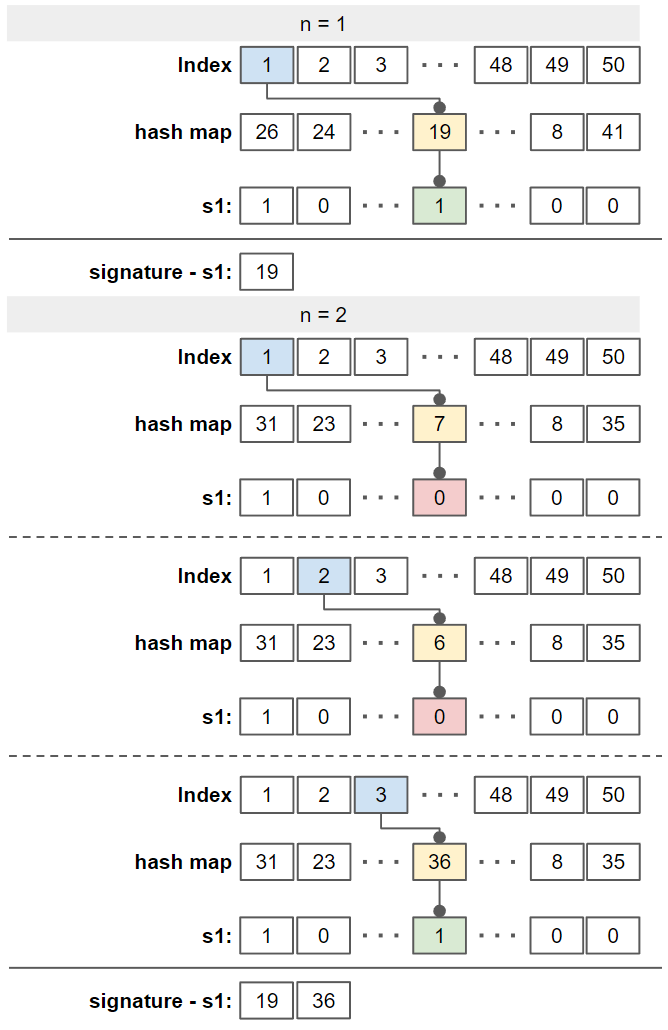
시그니처(Signature)는 sparse vector를 dense vector로 변환하는 과정이며, MinHash 함수를 적용한 결과다. 각 데이터의 특징을 표현하는 방법이기 때문에 feature vector라고 할 수도 있다. 여기서 해시 테이블(맵)은 단어장 길이의 만큼의 숫자 매번 셔플로 하여 생성한다. 이러한 과정을 permutation이라고 한다. 총 \(N\) 길이 만큼의 signature를 만들고 싶다면 \(N\)번의 loop을 통해 signature를 찾아내며, 우리는 \(V\) 크기의 sparse vector를 \(N\) 크기의 dense vector로 변환할 수 있다.
def create_hashes(N: int, V: int) -> np.ndarray:
hashes = np.zeros((N, V), dtype=int)
for i in range(N):
permutation = np.random.permutation(V) + 1
hashes[i, :] = permutation.copy()
return hashes # N x V
아래 그림은 signature를 만드는 과정 중 첫 번째와 두 번째 iteration을 보여준다.
순수 파이썬으로 구현시 다음과 같이 구현 가능하다.
def create_signature(
vector: np.ndarray,
hashses: np.ndarray,
vocabulary: list[str]
):
signature = []
for k, func in enumerate(hashses):
for i in range(1, len(vocabulary)+1):
idx = list(func).index(i) # search hash value index in hash map
signature_val = vector[idx]
if signature_val == 1:
signature.append(idx)
break
return signature
def create_signatures_plain(hashes: np.ndarray, docs_vectors: np.ndarray) -> np.ndarray:
signatures = []
for vector in docs_vectors:
signature = create_signature(vector, hashes, vocabulary)
signatures.append(signature)
return np.array(signatures)
여러 문서를 한번에 처리하기 위해 NumPy를 활용하면 다음과 같이 구현 가능하다.
def create_signatures(hashes, docs_vectors):
argsorted_hashes_index = np.argsort(hashes) # N x V
check_is_one = docs_vectors[:, argsorted_hashes_index] # num_docs x N x V
first_nonzero_idx = np.argmax(check_is_one, axis=2, keepdims=True) # num_docs x N x 1
signatures = np.take_along_axis(
np.tile(argsorted_hashes_index, (len(docs_vectors), 1, 1)),
first_nonzero_idx, axis=2
).squeeze(-1) # num_docs x N
signatures
return signatures
비슷한 의미를 가진 문서는 비슷한 signature를 가진다. 그렇다면 적절한 \(N\)은 어떻게 정해야할까? 같은 Hash Function 내에서 \(N\)이 커질수록, 각 문서가 가지고 있는 원래의 단어장 인덱스 집합에 가까워지기 때문에, 점점 원래 문서의 유사도에 가까워진다. 아래 실험은 \(N\)이 커질수록 원래 문서의 유사도에 가까워지는 것을 보여준다.
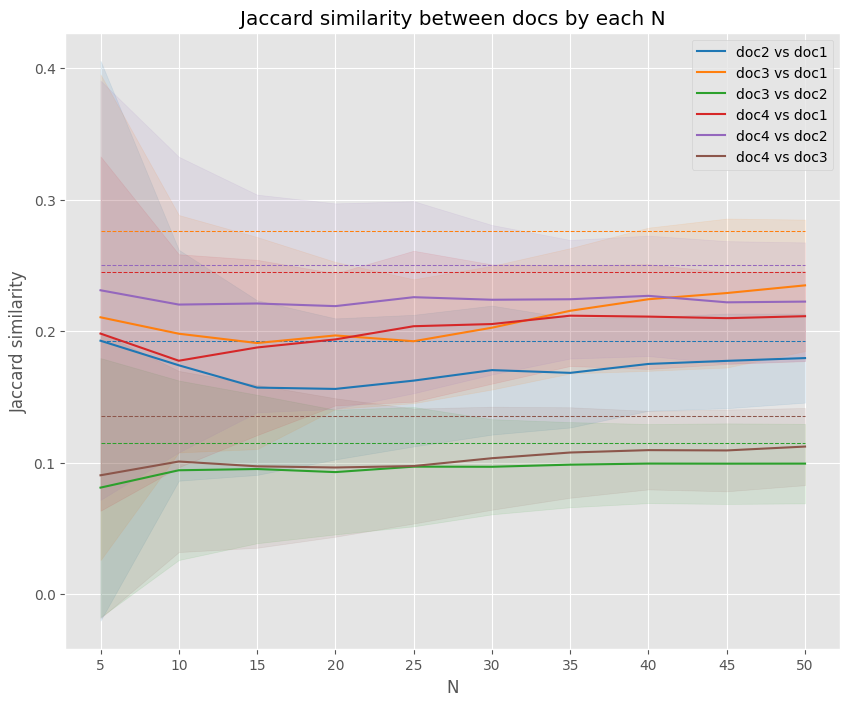
import matplotlib.pyplot as plt
import seaborn as sns
def run_exp(n_exp, candidates_of_N, vocab_length, docs_vectors, rows, cols):
max_N = candidates_of_N[-1]
print(max_N)
exp_res = [] # n_exp x len(candidates_of_N) x len(combination of (rows and cols))
for _ in range(n_exp):
hashes = create_hashes(max_N, V=vocab_length)
current_exp = []
for N in candidates_of_N:
# create signatures
signatures = create_signatures(hashes[:N], docs_vectors)
docs_similarity_lsh = get_docs_similarity(signatures)
current_exp.append(docs_similarity_lsh[rows, cols])
exp_res.append(np.array(current_exp))
exp_res = np.array(exp_res)
mean_exp_res = np.mean(exp_res, axis=0)
std_exp_res = np.std(exp_res, axis=0)
return mean_exp_res, std_exp_res
def draw(rows, cols, candidates_of_N, mean_exp_res, std_exp_res, docs_similarity):
palette = sns.color_palette("tab10", len(rows)).as_hex()
plt.style.use("ggplot")
fig, ax = plt.subplots(1, 1, figsize=(10, 8))
for i_rc, (row, col) in enumerate(zip(rows, cols)):
sns.lineplot(x=candidates_of_N, y=mean_exp_res[:, i_rc], c=palette[i_rc],
linewidth=1.5, label=f"doc{row+1} vs doc{col+1}", ax=ax)
ax.fill_between(candidates_of_N, mean_exp_res[:, i_rc]-std_exp_res[:, i_rc], mean_exp_res[:, i_rc]+std_exp_res[:, i_rc],
color=palette[i_rc], alpha=0.1)
y = [docs_similarity[row, col]]*len(candidates_of_N)
ax.plot(candidates_of_N, y, color=palette[i_rc], linewidth=0.75, linestyle='--')
ax.set_xticks(candidates_of_N)
ax.set_xticklabels(candidates_of_N)
ax.set_title("Jaccard similarity between docs by each N")
ax.set_xlabel("N")
ax.set_ylabel("Jaccard similarity")
ax.legend()
plt.show()
def main(docs_shingling, docs_vectors, vocabulary, n_exp=30, interval=5):
candidates_of_N = np.arange(interval, 50+interval, interval)
docs_similarity = get_docs_similarity(docs_shingling)
rows, cols = np.tril_indices(docs_similarity.shape[0], k=-1) # lower triangle index
vocab_length = len(vocabulary)
mean_exp_res, std_exp_res = run_exp(
n_exp, candidates_of_N, vocab_length, docs_vectors, rows, cols
)
draw(rows, cols, candidates_of_N, mean_exp_res, std_exp_res, docs_similarity)
main(docs_shingling, docs_vectors, vocabulary, n_exp=30, interval=5)
5. LSH Process¶
지금까지 원-핫 인코딩된 shingling들을 작은 크기의 정수 벡터로 변환하는 과정을 통해 signature를 얻었다. 그런데 우연의 일치로 의미가 다른 문서가 signature들이 완전히 일치한 경우가 발생할 수도 있다. 이를 해결하고자 banding method를 적용한다.
Banding method는 signature를 여러개의 밴드(band)로 나누어서 한번 더 해시함수를 통해 비교하는 방법이다. 하나의 밴드 안에 몇개의 원소를 담을지를 \(r\)로 정한다. 따라서, 자동적으로 signature의 길이에 따라 밴드의 갯수 \(b\)도 정해진다. 예를 들어 \(N=20\)이고, \(r=2\)이면, \(b=10\) 개의 밴드로 나누어서 비교한다. 이때 각 밴드는 2개의 signature를 가지게 된다. 이렇게 나누어진 밴드 안에서 signature가 일치하는 경우를 찾는다. 이때 일치하는 signature의 갯수가 일정 이상인 경우 유사한 문서로 판단한다.
def get_bands(signatures, r):
_, n_hashes = signatures.shape
assert n_hashes % r == 0
b = n_hashes // r # number of bands
bands = np.array(np.split(signatures, b, axis=1))
return np.transpose(bands, (1, 0, 2))
r = 2 # length of each sub-vector(signature)
b = len(signatures[0]) // r # number of bands
bands = get_bands(signatures, r)
n_docs = len(bands)
similar_docs = np.zeros((n_docs, n_docs), dtype=int)
for i in range(n_docs): # row
for j in range(n_docs): # column
if i == j:
similar_docs[i,j] = 0
continue
# 단순 일치하는 signature 갯수를 세는 방법
n_equal = (np.equal(bands[i], bands[j]).sum(1) == r).sum()
if n_equal > 0:
similar_docs[i,j] = n_equal
print("Similarity matrix:")
print(similar_docs)
# Similarity matrix:
# [[0 0 0 1]
# [0 0 0 0]
# [0 0 0 0]
# [1 0 0 0]]
지금까지 이야기한 LSH 과정을 하나의 클래스로 만들었다. 다만 큰 문서에는 적합하지 않는다(create_signatures 함수 최적화 필요)
from itertools import combinations
class LSH:
def __init__(self, b):
self.b = b # number of bands
self.buckets = [{} for _ in range(self.b)]
self.counter = 0
def get_bands(self, signatures):
self.n_docs, self.n_sig = signatures.shape
assert self.n_sig % self.b == 0, f"band size(={self.b}) should have 0 remainder. shape of signatures (n_docs, n_sig)= {signatures.shape}"
self.r = self.n_sig // self.b # length of each sub-vector(signature)
bands = np.array(np.split(signatures, self.b, axis=1))
return np.transpose(bands, (1, 0, 2))
def create_hashes(self, signatures):
bands = self.get_bands(signatures)
n_docs = len(bands)
for k in range(n_docs):
for i, subvec in enumerate(bands[k]):
subvec = tuple(subvec)
if subvec not in self.buckets[i]:
self.buckets[i][subvec] = set()
self.buckets[i][subvec].add(self.counter)
self.counter += 1
def get_candidates(self):
candidates = []
for bucket_band in self.buckets:
keys = bucket_band.keys()
for bucket in keys:
hits = bucket_band[bucket]
if len(hits) > 1:
candidates.extend(combinations(hits, 2))
return set(candidates)
lsh = LSH(b=10)
lsh.create_hashes(signatures)
candidates = lsh.get_candidates()
print("Candidates =", candidates)
# Candidates = {(0, 3)}
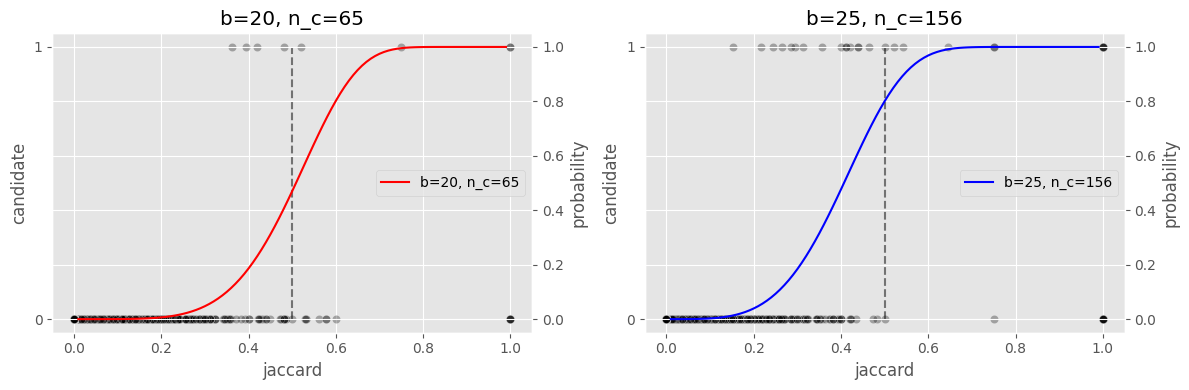
큰 \(b\)를 가지면 당연히, 밴드 하나에 들어가는 원소 \(r\)이 작아지기 때문에 유사한 candidates를 찾을 확률은 더 상승하게 된다. 같은 bucket을 공유할 확률을 다음과 같이 계산할 수 있다.
여기서 \(s\)는 signature의 유사도다. Jaccard, Cosine 등 방법을 사용할 수가 있다. \(s^r\)은 하나의 밴드 내에서 모든 원소가 일치할 확률이다. \((1-s^r)^b\)는 두 문서가 모든 밴드에서 일치하지 않을 확률이며. 따라서 \(1 - (1 - s^r)^b\)는 두 문서가 하나 이상의 밴드에서 일치할 확률이다. 즉, \(P\)는 적어도 하나의 candidate를 찾을 확률로 볼 수 있다.
아래 그림은 500개의 문서를 각각 20, 25개의 밴드를 나누어서 비교한 결과다. 검은 점은 약 50,000개의 두 문서를 샘플링 하였을 때, 두 문서의 유사도를 찍은 것이다. 그림에서 볼 수 있듯이, \(b\)가 커질 수록 후보문서 \(n_c\)가 커지는 것을 확인 할 수 있으나. 그만큼 False Positive(유사하지 않은 문서를 유사하다고 판단하는 경우)도 커지는 것을 확인 할 수 있다. 적절한 \(b\)를 조절하여 similarity의 threshold를 조정함으로써 우리가 찾은 candidates의 정밀도 혹은 재현율을 조정할 수 있다.