Big Query

구글 빅쿼리(BigQuery)는 머신러닝, 지리정보 분석, 비즈니스 인텔리전스와 같은 기본 제공 기능으로 데이터를 관리하고 분석할 수 있게 해주는 완전 관리형 엔터프라이즈 데이터 웨어하우스입니다. 1
즉, 데이터 웨어하우스에서 SQL 쿼리를 이용해 다양한 질문들을 하고 분석하는 도구이자 공간이다. 빅쿼리는 스토리지와 컴퓨팅을 분리한 아키텍쳐로 필요에 따라서 스토리지와 컴퓨팅을 모두 독립적으로 확장이 가능하다. 게다가 서버를 따로 구축할 필요없이 실행이 가능하다.
이번 튜토리얼에서는 Titanic2 데이터 세트를 이용해 BigQuery와 BigQuery ML의 사용 방법에 대해 주로 다룬다.
BigQuery 시작하기¶
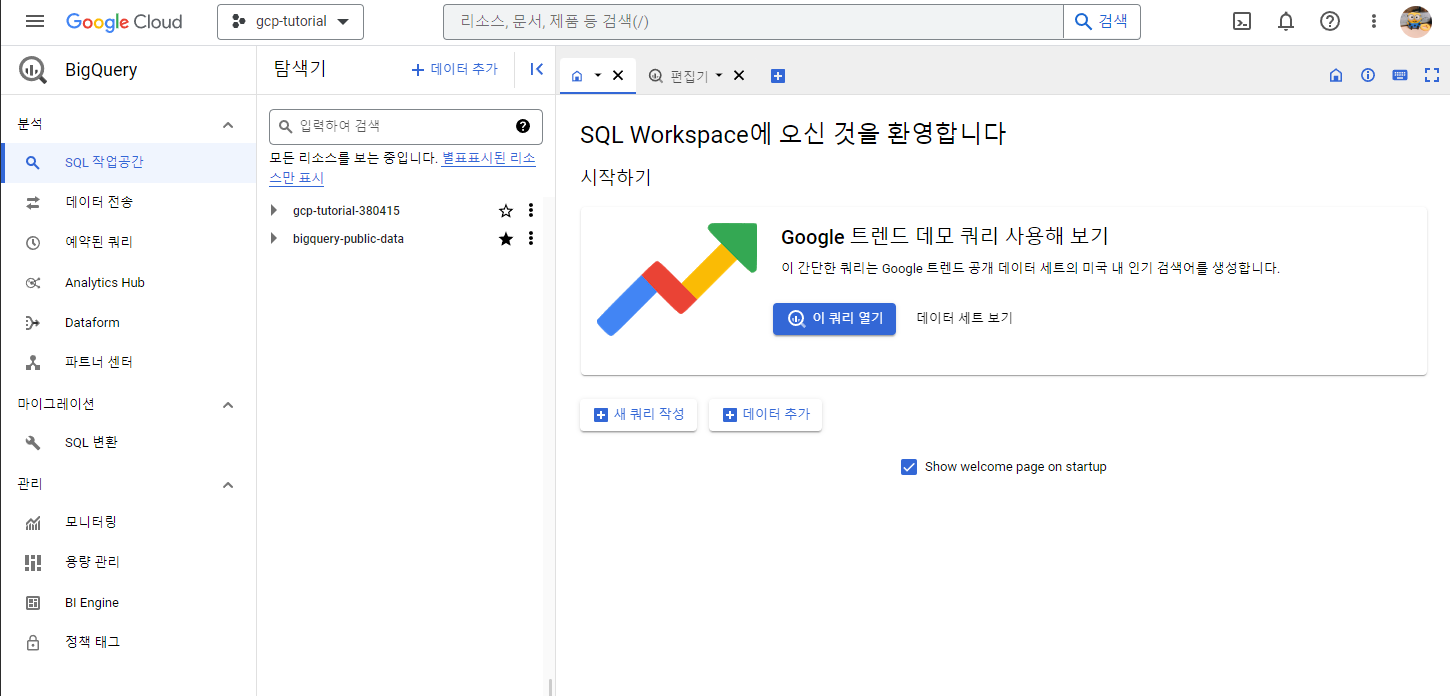
빅쿼리를 시작하면 다음과 같은 화면이 뜬다. 여기서 데이터를 불러오고, 쿼리를 질의할 수 있는 작업환경까지 마련되어 있다. 이제 데이터 세트 에셋을 생성해보자. Titanic 데이터 세트를 작업 공간에 불러서 작업해본다.
프로젝트 ID에서 데이터 세트를 만든다.
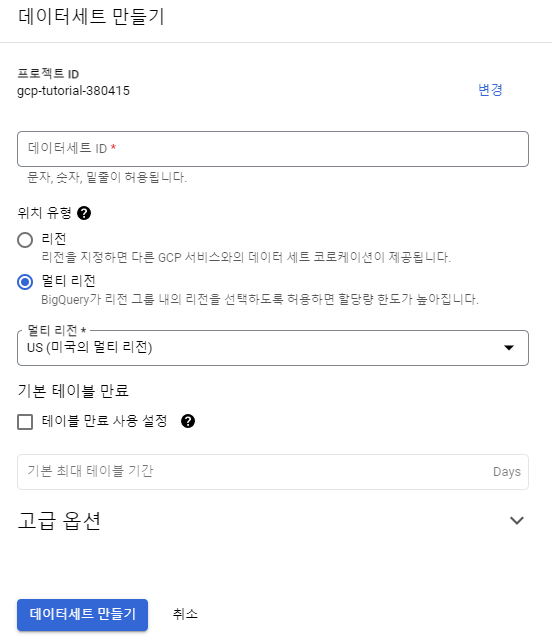
데이터 세트 ID titanic를 입력한다. 데이터 세트가 생성되고나면 에셋이 생성 되었다는 문구가 뜬다.

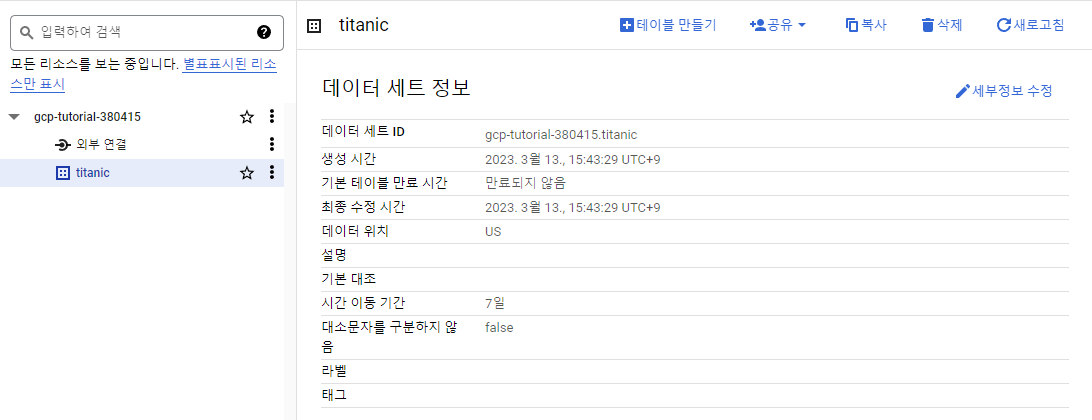
데이터세트가 생성되었다.
데이터 세트는 기존의 RDBMS에서 데이터베이스 같은 역할을 한다. 여기서 필요한 테이블을 생성할 수 있다.
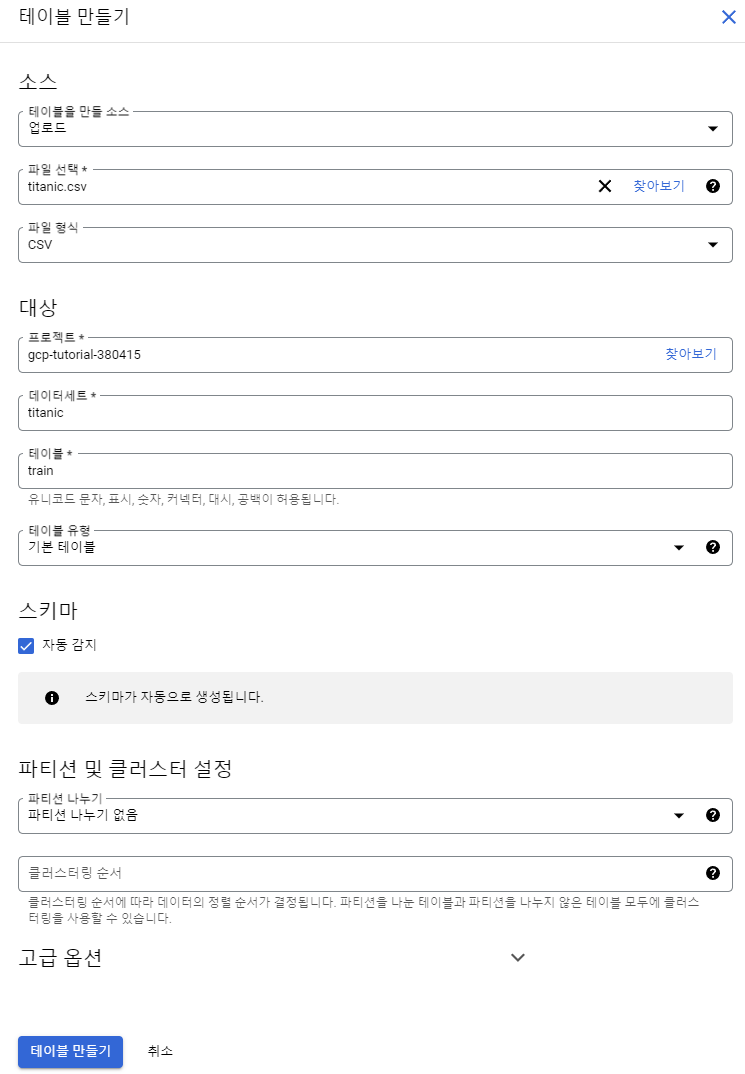
업로드를 통해서 소스 파일을 테이블로 만들자. 스키마는 직접 설정하거나 자동으로 감지하여 생성할 수 있다.
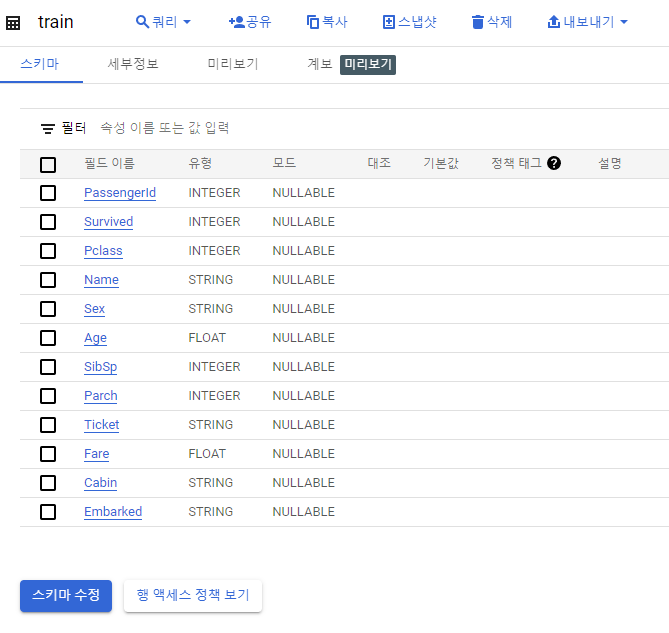
생성된 테이블을 보면 스키마가 잘 지정되어 있는 것을 확인 할 수 있다.
이제 쿼리를 실행하여 콘솔에서 필요한 질의 수행 해본다.
Null 데이터 파악하기
전체 데이터 크기 및 PassengerID의 최댓값 파악하기
성별로 인원이 얼마나 되었으며, 생존율이 어떻게 되었는 지?
나이 그룹 별로 생존율은 어떻게 되는지?
SELECT
AgeCate,
ROUND(SUM(Survived) / COUNT(PassengerId), 4) AS SurvivedRate
FROM (
SELECT
PassengerId,
Survived,
CASE
WHEN Age BETWEEN 0 AND 12 THEN 'Child'
WHEN Age BETWEEN 13 AND 18 THEN 'Teenager'
WHEN Age BETWEEN 19 AND 35 THEN 'YoungAdult'
WHEN Age BETWEEN 36 AND 55 THEN 'Adult'
WHEN Age > 55 THEN 'Senior'
ELSE 'NA'
END AS AgeBucket
FROM `[프로젝트 ID].titanic.train`
)
GROUP BY AgeCate
ORDER BY AgeCate
BigQuery ML¶
BigQuery ML을 사용하면 GoogleSQL 쿼리를 사용하여 BigQuery에서 머신러닝 모델을 만들고 실행할 수 있다. 실행 가능한 모델의 선택 가이드는 다음 그림과 같다.

이번 튜토리얼에서는 Kaggle Titanic2 데이터 세트를 사용하여 머신러닝 파이프라인을 SQL로만 만들어보자.
1. CREATE DATAVIEW¶
Kaggle Titanic2 데이터 세트에서 train.csv와 test.csv 파일을 업로드하여 데이터 train과 test 테이블을 만들고, 훈련을 하기위한 데이터 전처리를 한다.
CREATE OR REPLACE VIEW
`titanic.input_view` AS
SELECT
Pclass,
Sex,
CASE
WHEN Age BETWEEN 0 AND 12 THEN 'Child'
WHEN Age BETWEEN 13 AND 18 THEN 'Teenager'
WHEN Age BETWEEN 19 AND 35 THEN 'YoungAdult'
WHEN Age BETWEEN 36 AND 55 THEN 'Adult'
WHEN Age > 55 THEN 'Senior'
ELSE 'NA'
END AS AgeBucket,
SibSp,
Parch,
Fare,
Survived
FROM `[프로젝트 ID].titanic.train`
WHERE Embarked IS NOT NULL
CREATE OR REPLACE VIEW
`titanic.test_view` AS
SELECT
Pclass,
Sex,
CASE
WHEN Age BETWEEN 0 AND 12 THEN 'Child'
WHEN Age BETWEEN 13 AND 18 THEN 'Teenager'
WHEN Age BETWEEN 19 AND 35 THEN 'YoungAdult'
WHEN Age BETWEEN 36 AND 55 THEN 'Adult'
WHEN Age > 55 THEN 'Senior'
ELSE 'NA'
END AS AgeBucket,
SibSp,
Parch,
Fare
FROM `[프로젝트 ID].titanic.test`
WHERE Embarked IS NOT NULL
2. CREATE MODEL AND EVALUATION¶
CREATE OR REPLACE MODEL
`titanic.titanic_model`
OPTIONS
(
model_type='RANDOM_FOREST_CLASSIFIER',
input_label_cols=['Survived'],
data_split_method='AUTO_SPLIT'
) AS
SELECT
*
FROM
`titanic.input_view`
모델 훈련 OPTIONS 에서 DATA_SPLIT_METHOD가 있는데, 기본설정 값으로 AUTO_SPLIT으로 되어 있다. 500행 이하일 때는 데이터 스플릿을 진행하지 않는다. 만약 500행 이상일 경우 랜덤 스필릿으로 평가를 진행한다.
실행된 쿼리 결과를 살펴보자. 처리된 쿼리양은 32.34GB이며, 총 10분 16초의 시간이 걸렸다.

그리고 titanic_model를 클릭하여 평가 항목을 살펴보면 모델의 평가 데이터로 평가된 결과를 볼 수 있다.
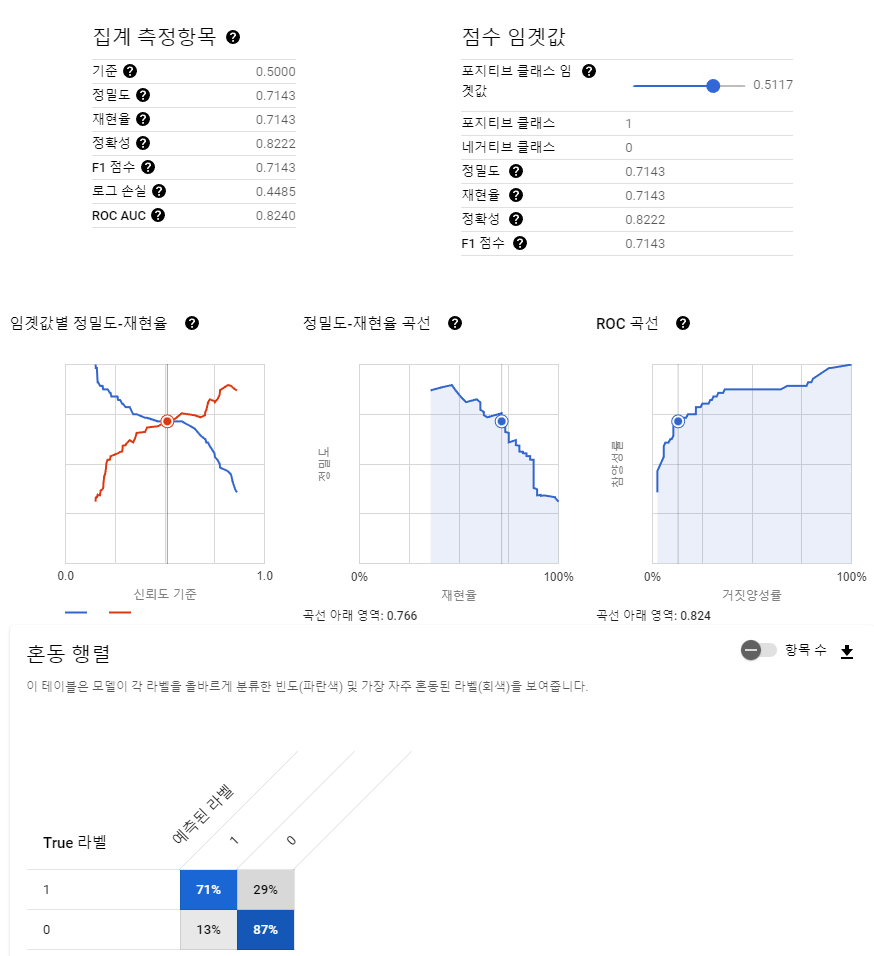
3. PREDICT¶
이제 테스트 데이터로 예측을 해본다.
Explainable AI 기능3을 사용하여 어떤 Feature가 예측에 중요하게 작용했는지도 볼 수 있다.
SELECT
*
FROM
ML.EXPLAIN_PREDICT(
MODEL `titanic.titanic_model`,
(
SELECT * FROM `titanic.test_view`
),
STRUCT(3 as top_k_features)
)
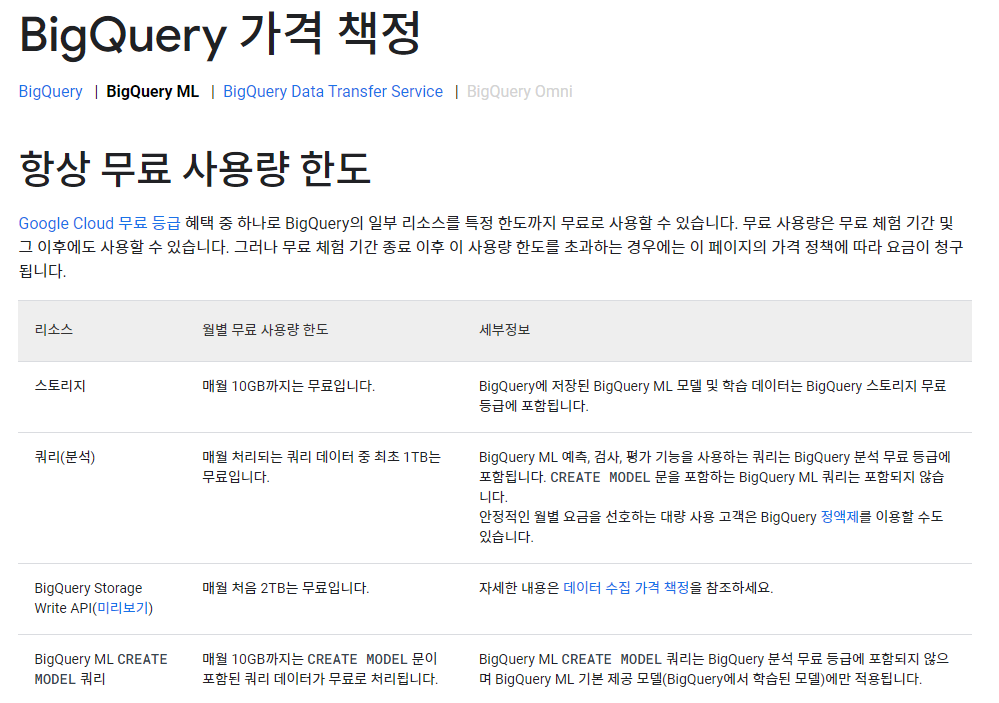
가격 책정¶
빅쿼리의 가격 책정4은 다음과 같다. 기본적으로 10GB의 무료 스토리지, 매월 1TB의 무료 쿼리 그리고 매월 10GB 무료 CREATE MODEL 문 쿼리로 돼있다. IAM 및 관리자 > 할당량 에서 현재 사용한 할당량을 확인 할 수 있다. 확인 결과 이번 튜토리얼에 해당하는 쿼리의 양은 총 32.498 GB 정도 된다.