3. Data Modeling

어플리케이션에 따라 데이터를 조회하는 패턴이 다르고 퍼포먼스도 이에 따라 달라진다. 따라서 데이터 모델링을 할 때는 데이터를 어떻게 사용하는지를 봐야한다.1 이번 시간에는 MongoDB에서 데이터 모델링 예시와 패턴들을 알아본다.
기존의 RDBMS 데이터베이스와 다르게 MongoDB는 유연한 스키마(Flexible Schema) 구조를 가지고 있다. 각 컬렉션(Collections)에 들어가는 도큐먼트(Documents)들은 꼭 같은 스키마가 들어갈 필요가 없다. 이는 즉:
-
하나의 컬렉션에 포함된 도큐먼트들 꼭 같은 필드가 들어갈 필요가 없고, 같은 필드라도 다른 데이터 타입을 가질 수 있다. 즉, 아래와 같이 데이터를 삽입할 수도 있다.
-
새로은 필드 추가, 기존 필드 제거 혹은 필드 값 타입의 변경등으로 도큐먼트의 구조를 쉽게 변경할 수 있다.
개발 초기에는 이러한 점이 장점이 될 수 있다. 그러나, 실제 어플리케이션에서는 주로 같은 컬렉션에 있는 도큐먼트들은 같은 필드를 공유하고, document validation rules를 사용하여 데이터 삽입 시 문제가 없는지 진단하는 경우가 많다. 2
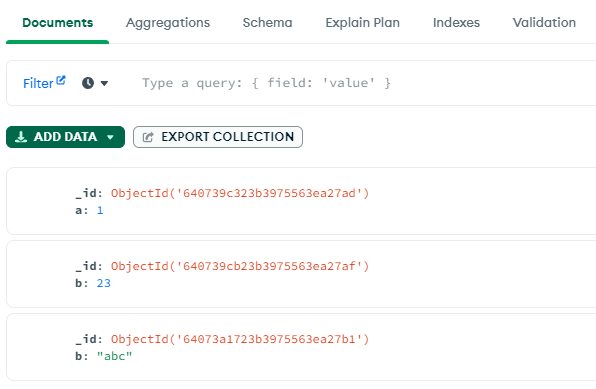
Schema Validation을 적용하기전 b 필드에는 int 타입과 string 타입이 들어 갈 수 있었다.
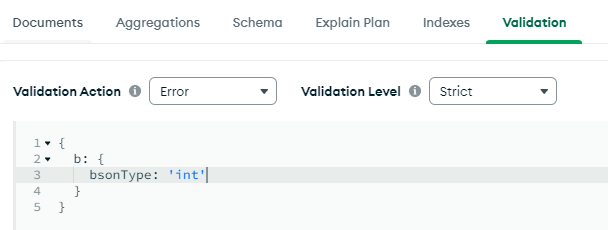
b 필드에 Schema Validation을 적용하여 int 타입만 받게 한다.
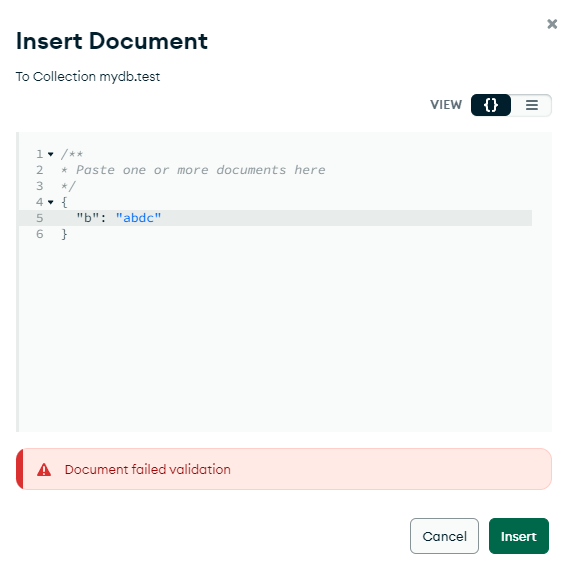
더 이상 string 타입의 데이터를 삽입할 수 없게 된다.
데이터 모델링 예시¶
MongoDB Compass¶
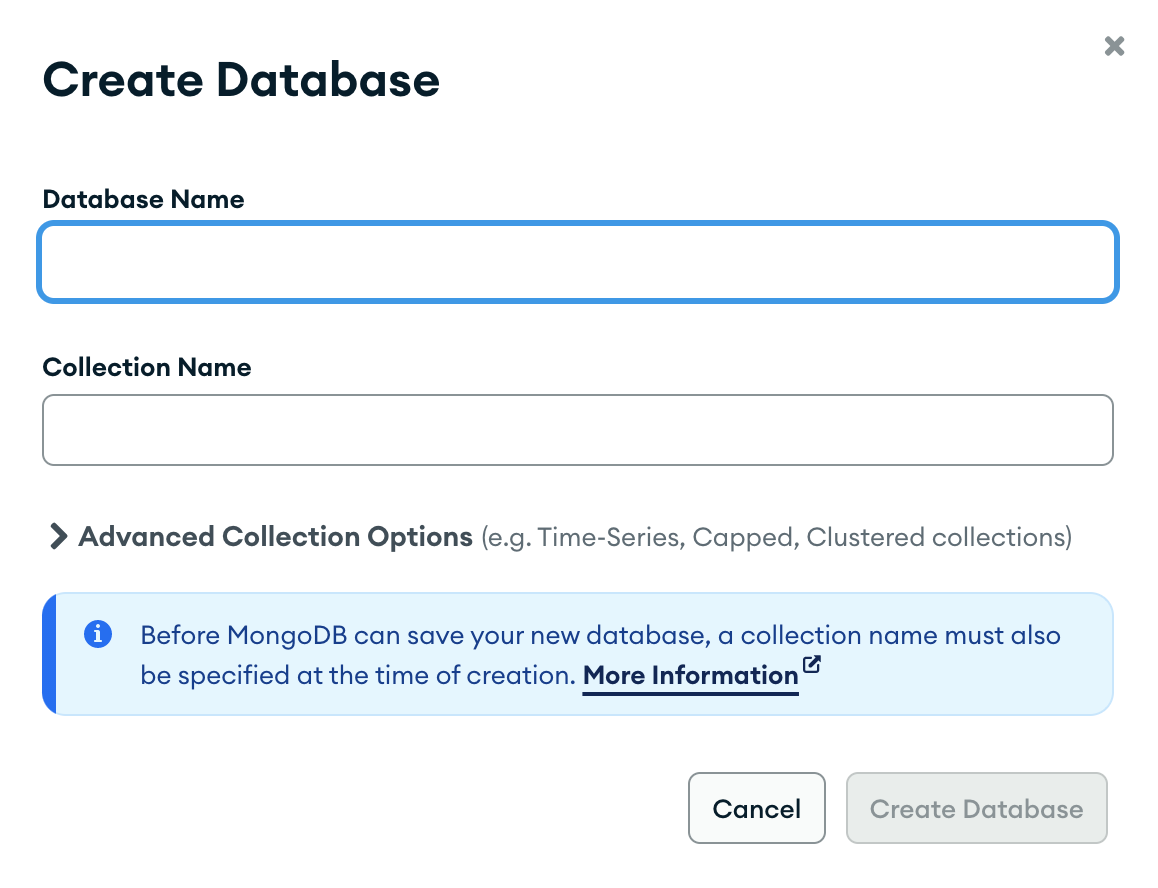
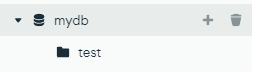
이번에는 MongoDB Compass(다운로드 링크)로 여러 작업을 수행해보도록 하겠다. 우선 데이터베이스 mydb 라는 데이터베이스와 test라는 컬렉션을 만들고 데이터를 불러오자.
One-to-One Relationships with Embedded Documents¶
일대일 대응관계가 있을 때 임베디드 도큐먼트를 사용하는 데이터 모델링 예제를 다룬다. 도큐먼트 안에 데이터를 연결 경우 읽기 작업을 줄일 수가 있다.
예시로 후원자(patron)와 후원자의 주소가있는 두 개의 도큐먼트가 있다. Normalized 데이터 모델에서는 address 도큐먼트의 patron_id 스키마가 patron 도큐먼트를 참조(reference)한다.
// patron document
{
_id: "joe",
name: "Joe Bookreader"
}
// address document
{
patron_id: "joe", // (1)
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
 reference to patron document
reference to patron document
만약에 address 데이터를 name과 함께 자주 조회해야 하는 상황이라면 계속 해당 name을 조회할 때마다 JOIN operation을 수행해야한다. 따라서 아래와 같이 embedded document로 정보를 하나의 도큐먼트에 담는 것이 도움이 된다.
{
_id: "joe",
name: "Joe Bookreader",
address: {
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
}
그러나 이러한 패턴의 단점도 명확하다. 우리가 필요하지 않은 정보를 모두 한 도큐먼트에 담아서 도큐먼트의 크기가 커진다(참고로 하나의 도큐먼트의 최대 크기는 16MB다). 예를 들어 영화 정보를 보여주는 어플리케이션의 경우:
{
"_id": 1,
"title": "The Arrival of a Train",
"year": 1896,
"runtime": 1,
"released": ISODate("01-25-1896"),
"poster": "http://ia.media-imdb.com/images/M/MV5BMjEyNDk5MDYzOV5BMl5BanBnXkFtZTgwNjIxMTEwMzE@._V1_SX300.jpg",
"plot": "A group of people are standing in a straight line along the platform of a railway station, waiting for a train, which is seen coming at some distance. When the train stops at the platform, ...",
"fullplot": "A group of people are standing in a straight line along the platform of a railway station, waiting for a train, which is seen coming at some distance. When the train stops at the platform, the line dissolves. The doors of the railway-cars open, and people on the platform help passengers to get off.",
"lastupdated": ISODate("2015-08-15T10:06:53"),
"type": "movie",
"directors": [ "Auguste Lumière", "Louis Lumière" ],
"imdb": {
"rating": 7.3,
"votes": 5043,
"id": 12
},
"countries": [ "France" ],
"genres": [ "Documentary", "Short" ],
"tomatoes": {
"viewer": {
"rating": 3.7,
"numReviews": 59
},
"lastUpdated": ISODate("2020-01-09T00:02:53")
}
}
하나의 도큐먼트에 다 담지 말고 영화의 간단한 정보만 보여주는 movie 컬렉션과 자세한 정보를 보여주는 movie_details 컬렌션을 분리하여 담아두는 것이 좋다. 예를 들어 사람들이 영화를 검색할 때 제목, 연도, 장르 혹은 감독/연출자로 검색을 한 후에 디테일한 정보를 나중에 보기 때문에, 주로 자주 조회되는 요약된 정보를 하나의 콜렉션으로 담고, 나머지 디테일한 정보는 참조 형태로 만드는 것이 더 유용하다.
{
"_id": 156,
"movie_id": 1, // (1)
"poster": "http://ia.media-imdb.com/images/M/MV5BMjEyNDk5MDYzOV5BMl5BanBnXkFtZTgwNjIxMTEwMzE@._V1_SX300.jpg",
"plot": "A group of people are standing in a straight line along the platform of a railway station, waiting for a train, which is seen coming at some distance. When the train stops at the platform, ...",
"fullplot": "A group of people are standing in a straight line along the platform of a railway station, waiting for a train, which is seen coming at some distance. When the train stops at the platform, the line dissolves. The doors of the railway-cars open, and people on the platform help passengers to get off.",
"lastupdated": ISODate("2015-08-15T10:06:53"),
"imdb": {
"rating": 7.3,
"votes": 5043,
"id": 12
},
"tomatoes": {
"viewer": {
"rating": 3.7,
"numReviews": 59
},
"lastUpdated": ISODate("2020-01-29T00:02:53")
}
}
- reference to the movie collection
One-to-Many Relationships with Embedded Documents¶
이번에는 일대다 대응관계의 상황을 살펴본다. 아래와 같이 한 후원자가 두 개의 주소를 가질 수 있다. 마찬가지로 이름과 모든 주소를 함께 조회하려면 각 도큐먼트에 JOIN operation을 한 다음에 모든 주소를 가져올 수 있다.
// patron document
{
_id: "joe",
name: "Joe Bookreader"
}
// address documents
{
patron_id: "joe", // (1)
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
{
patron_id: "joe",
street: "1 Some Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
- reference to patron document
해당 경우는 배열의 형태로 모든 주소를 담는 것이 더 효율적이다.
{
"_id": "joe",
"name": "Joe Bookreader",
"addresses": [
{
"street": "123 Fake Street",
"city": "Faketon",
"state": "MA",
"zip": "12345"
},
{
"street": "1 Some Other Street",
"city": "Boston",
"state": "MA",
"zip": "12345"
}
]
}
이전과 마찬가지로 embedded document 패턴의 단점은 문서가 길어질 수가 있다는 점이다. 예를 들어 후원자의 최근 10개의 후원 내역을 보여주는 어플리케이션을 만든다고 가정해보자. 만약 하나의 도큐먼트에 임베디드 형태로 만들 었을 때, 해당 후원자를 조회 할 때 마다 모든 후원내역을 가져와야함으로 비효율적이다.
{
"_id": "joe",
"name": "Joe Bookreader",
"addresses": [
{
"street": "123 Fake Street",
"city": "Faketon",
"state": "MA",
"zip": "12345"
},
{
"street": "1 Some Other Street",
"city": "Boston",
"state": "MA",
"zip": "12345"
}
],
"donations": [
{
"donate_id": 786,
"date": ISODate("2023-03-12"),
"amount": "3.05",
"currency": "dollar"
},
...
{
"donate_id": 1,
"date": ISODate("2019-01-03"),
"amount": "1.05",
"currency": "dollar"
},
]
}
이때는 과거의 모든 내역을 보여주는 것 보다 최근 10개의 내역을 하나의 도큐먼트에 담고, 이전 내역은 분리된 콜렉션에 두는 것이 더 좋다.
{
"_id": "joe",
"name": "Joe Bookreader",
"addresses": [
{
"street": "123 Fake Street",
"city": "Faketon",
"state": "MA",
"zip": "12345"
},
{
"street": "1 Some Other Street",
"city": "Boston",
"state": "MA",
"zip": "12345"
}
],
"donations": [
{
"donate_id": 786,
"date": ISODate("2023-03-12"),
"amount": "3.05",
"currency": "dollar"
},
...
{
"donate_id": 776,
"date": ISODate("2023-01-09"),
"amount": "5.25",
"currency": "dollar"
},
]
}
더 작은 크기의 도큐먼트로 자주 접근하는 데이터 구조를 설계하면 읽기 속도를 향상 시키지만, 단점으로 중복된 데이터가 저장 될 수 있다는 단점이 있다. 위 예시에서 최근 10개의 리뷰는 항상 새로운 후원이 들어올 경우 patron과 donation 콜렉션이 함께 업데이트가 되어야한다. 물론 patron 컬렉션의 최근 10개 내역을 donation의 가장 최근 10 개로 보장하는 로직을 설계할 수도 있다.
One-to-Many Relationships with Document References¶
마지막으로 일대다의 대응관계를 가질때 Embedded Documents가 아닌 Reference 형태로 데이터를 연결을 해본다. 예시로 출판사와 책의 관계를 모델링 하려고한다. 책 도큐먼트에서 출판사의 정보가 현재 Embedded Documents 형태로 연결되어 있으며 중복된 데이터가 존재한다.
{
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
{
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
이러한 경우에는 출판사와 책을 두 개의 컬렉션으로 만드는 것이 효율적이다. 여러 개의 출판사와 여러 권의 책 도큐먼트를 별 개의 컬렉션에 담는 것이다.
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English"
publisher_id: "oreilly"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English"
publisher_id: "oreilly"
}