CS 285: Lecture 19, Control as Inference
영상링크: https://youtu.be/MzVlYYGtg0M
Optimal control as a Model of Human Behavior¶
Optimal control is a mathematical framework for computing control policies that optimize a given objective.
- \(r(s_t, a_t)\) 함수를 찾아서 데이터를 설명하려고함. 기본적 세팅은 다음과 같음.
\[\begin{aligned}
a_1, \dots, a_T &= \underset{a_1, \dots, a_T}{\arg \max} \sum_{t=1}^T r(s_t, a_t) \\
s_{t+1} &= f(s_t, a_t) \\
\pi &= \underset{\pi}{\arg \max} \mathbb{E}_{s_{t+1} \sim p(s_{t+1} \vert s_t, a_t), a_t \sim \pi(a_t \vert s_t)} \lbrack r(s_t, a_t) \rbrack \\
a_t &\sim \pi(a_t \vert s_t)
\end{aligned}\]
- 하지만 이는 적용하기 쉽지 않음. 우리는 목표에 최적화된 행동을 항상 하지 않음. 같은 목표라도 직진하는 경우도 있고, 멀리 돌아갈 때도 있음(결국에 목적에 도달함). 현 프레임워크에서 이를 설정하거나 설명하기 어려움. 어떤 행동이 최적화된 행동인지에 대한 변수자체가 없음.
- 그래서 이를 설명하기 위해 binary 변수 \(\mathcal{O}\) 도입함. 최적화인 행동일 때 1, 그렇지 아니할 때 0의 값을 가짐.

\[\begin{aligned}
p(\mathcal{O}_{1:T}) &= \exp \big( r(s_t, a_t) \big) \\
p(\tau \vert \mathcal{O}_{1:T}) &= \dfrac{p(\tau, \mathcal{O}_{1:T})}{p(\mathcal{O}_{1:T})} \\
&\propto p(\tau) \prod_t \exp \big( r(s_t, a_t) \big) = p(\tau) \exp \big( \sum_t r(s_t, a_t) \big)
\end{aligned}\]
- 이렇게 함으로써 suboptimal behavior를 모델링 할 수 있고, inference 알고리즘을 적용하여 control과 planning 문제를 해결할 수 있음. 그리고 stochastic behavior가 왜 선호되는지 설명할 수 있음. 이는 exploration과 transfer learning을 아는데 도움이 됨.
-
그러면 어떻게 inference할까?
-
Backward Messeage 계산: \(\beta(s_t, a_t) = p(\mathcal{O}_{1:T} \vert s_t, a_t)\)
- Policy 계산: \(\pi(a_t \vert s_t, \mathcal{O}_{1:T})\)
- Forward Message 계산: \(\alpha(s_t) = p(s_t \vert \mathcal{O}_{1:t-1})\)
Control as Inference¶
Backward Messages¶
\[\begin{aligned}
\beta(s_t, a_t) &= p(\mathcal{O}_{t:T} \vert s_t, a_t) \\
&= \int p(\mathcal{O}_{t:T}, s_{t+1} \vert s_t, a_t) ds_{t+1} \\
&= \int p(\mathcal{O}_{t+1:T} \vert s_{t+1}) p(s_{t+1} \vert s_t, a_t) p(\mathcal{O}_t \vert s_t, a_t) ds_{t+1}
\end{aligned}\]
- \(p(s_{t+1} \vert s_t, a_t)\)는 transition dynamics이고, \(p(\mathcal{O}_t \vert s_t, a_t)\)는 observation likelihood임.
- 그러면 제일 앞에 있는 \(p(\mathcal{O}_{t+1:T} \vert s_{t+1})\)를 풀어서 쓰면 다음과 같음.
\[\begin{aligned}
p(\mathcal{O}_{t+1:T} \vert s_{t+1}) &= \int p(\mathcal{O}_{1:T} \vert s_{t+1}, a_{t+1}) p(a_{t+1}\vert s_{t+1}) da_{t+1}
\end{aligned}\]
- 여기서 \(p(\mathcal{O}_{1:T} \vert s_{t+1}, a_{t+1})\) 를 다시 \(\beta(s_{t+1}, a_{t+1})\)로 바꿔서 쓸수 있음.
- 그리고 \(p(a_{t+1}\vert s_{t+1})\)는 action prior이라고 하는데 (policy는 아님) 우선은 uniform distribution으로 가정함. 왜냐면 아무도 어떤 행동을 할지 모르기 때문임. 게다가 수학적으로 해당 항을 지울 수 있음1.
- 따라서 Backward message passing은 다음과 같이 진행된다.
Backward Message Passing
\[\begin{aligned}
\text{for } \ t = T-1, &\dots, 1: \\
\beta(s_t, a_t) &= p(\mathcal{O}_t \vert s_t, a_t) \Bbb{E}_{s_{t+1} \sim p(s_{t+1} \vert s_t, a_t)} \big\lbrack \beta_{t+1}(s_{t+1}) \big\rbrack\\
\beta(s_t) &= \Bbb{E}_{a_t \sim p(a_t \vert s_t)} \big\lbrack \beta(s_t, a_t) \big\rbrack\\
\end{aligned}\]
- \(V_t(s_t) = \log \beta(s_t)\), \(Q_t(s_t, a_t) = \log \beta(s_t, a_t)\) 라고 재정의 하자. 따라서 \(V_t(s_t) = \log \int \exp \big( Q_t(s_t, a_t) \big) da_t\)로 쓸 수 있으며, 이는 soft value function이라고 함.
- \(Q_t(s_t, a_t)\)가 커짐에 다라서 \(V_t(s_t)\) 도 커짐. \(V_t(s_t) \rightarrow \underset{a_t}{\max} Q_(s_t, a_t)\).
- \(Q_t(s_t, a_t) = r(s_t, a_t) + \log \Bbb{E} \big\lbrack \exp( V_{t+1}(s_{t+1}) ) \big\rbrack\)
- deterministic transition: \(Q_t(s_t, a_t) = r(s_t, a_t) + V_{t+1}(s_{t+1})\)
- sthocastic case는 차후에 다룸
- Log domain에서 알고리즘을 다시 쓰면 다음과 같음.
Backward Message Passing(Log Domain)
\[\begin{aligned}
\text{for } \ t = T-1, &\dots, 1: \\
Q_t(s_t, a_t) &= r(s_t, a_t) + \log \Bbb{E}\big\lbrack \exp( V_{t+1}(s_{t+1}) ) \big\rbrack \\
V_t(s_t) &= \log \int \exp \big( Q_t(s_t, a_t) \big) da_t \\
\end{aligned}\]
Policy Computation¶
\[\begin{aligned}
p(a_t \vert s_t, \mathcal{O}_{1:T}) &= \pi(a_t \vert s_t) = p(a \vert s_t, \mathcal{O}_{t:T}) \\
&= \dfrac{p(a_t, s_t \vert \mathcal{O}_{t:T})}{p(s_t \vert \mathcal{O}_{t:T})} \\
&= \dfrac{p(a_t, s_t \vert \mathcal{O}_{t:T})p(a_t, s_t) / p(\mathcal{O}_{t:T}) }{p(\mathcal{O}_{t:T} \vert s_t) p(s_t) / p(\mathcal{O}_{t:T}) } \\
&= \dfrac{p(a_t, s_t \vert \mathcal{O}_{t:T})}{p(\mathcal{O}_{t:T} \vert s_t) } \dfrac{p(a_t, s_t)}{p(s_t)} = \dfrac{\beta_t(s_t, a_t)}{\beta_t(s_t)} p(a_t \vert s_t)
\end{aligned}\]
- \(p(a_t \vert s_t)\)는 action prior이라 무시하고, policy \(\pi(a_t \vert s_t) = \dfrac{\beta_t(s_t, a_t)}{\beta_t(s_t)}\)를 얻을 수 있음.
- Log domain에서 \(\pi(a_t \vert s_t) = \exp \big( Q_t(s_t, a_t) - V_t(s_t) \big) = \exp \big( A_t(s_t, a_t) \big)\) 로 쓸 수 있음.
- Temperature \(\alpha\) 를 도입하면 \(\pi(a_t \vert s_t) = \exp \big( \dfrac{1}{\alpha} Q_t(s_t, a_t) - \dfrac{1}{\alpha} V_t(s_t) \big) = \exp \big( \dfrac{1}{\alpha} A_t(s_t, a_t) \big)\)
- \(\alpha\) 가 0으로 갈 수록 deterministic policy가 되고 greedy policy에 가까움.
Forward Messages¶
\[\begin{aligned}
\alpha(s_t) &= p(s_t \vert \mathcal{O}_{1:t-1} ) \\
&= \int p(s_t, s_{t-1}, a_{t-1} \vert \mathcal{O}_{1:t-1}) da_{t-1} ds_{t-1} = \int p(s_t \vert s_{t-1}, a_{t-1}, \mathcal{O}_{1:t-1}) p(a_{t-1} \vert s_{t-1}, \mathcal{O}_{1:t-1}) p(s_{t-1} \vert \mathcal{O}_{1:t-1} ) da_{t-1} ds_{t-1} \\
&= \int p(s_t \vert s_{t-1}, a_{t-1}) p(a_{t-1} \vert s_{t-1}, \mathcal{O}_{1:t-1}) p(s_{t-1} \vert \mathcal{O}_{1:t-1} ) da_{t-1} ds_{t-1}
\end{aligned}\]
- \(p(s_t \vert s_{t-1}, a_{t-1}, \mathcal{O}_{1:t-1})\) 에서 \(\mathcal{O}_{1:t-1}\)는 \(s_{t-1}\)과 \(a_{t-1}\)에 의존하지 않으므로 생략 가능.
- \(\alpha_1(s_1) = p(s_1)\) 보통 알고 시작함.
- \(p(s_t \vert \mathcal{O}_{1:T})\) 를 계산하고 싶으면?
\[p(s_t \vert \mathcal{O}_{1:T}) = \dfrac{ p(s_t, \mathcal{O}_{1:T}) }{ p(\mathcal{O}_{1:T}) } = \dfrac{p(\mathcal{O}_{t:T} \vert s_t) p(s_t, \mathcal{O}_{1:t-1})}{p(\mathcal{O}_{1:T})} \propto \beta_t(s_t) \alpha_t(s_t) \]
Message Intersection¶

- 예를 들어 그림과 같이 목표지점에 공을 가져다 놓는 Task가 있다.
- Backward message는 목표지점에 도달하기 위한 상태의 확률을 나타내고, Forward message는 처음 상태에서 목표지점에 도달되는 상태를 표현한다(높은 reward 와 함께).
- 그리고 두 메시지의 곱은 목표지점에 도달하기 위한 상태의 확률을 나타낸다.
Control as Variational Inference¶
- Inference Problem: \(p(s_{1:T}, a_{1:T} \vert \mathcal{O}_{1:T})\)
- Marginalizaing과 conditioning을 통해 목적 policy \(p(a_t \vert s_t, \mathcal{O}_{1:T})\) 를 계산하고 싶음. "높은 리워드가 주어졌을 때, action probability가 어떻게 되는가?"
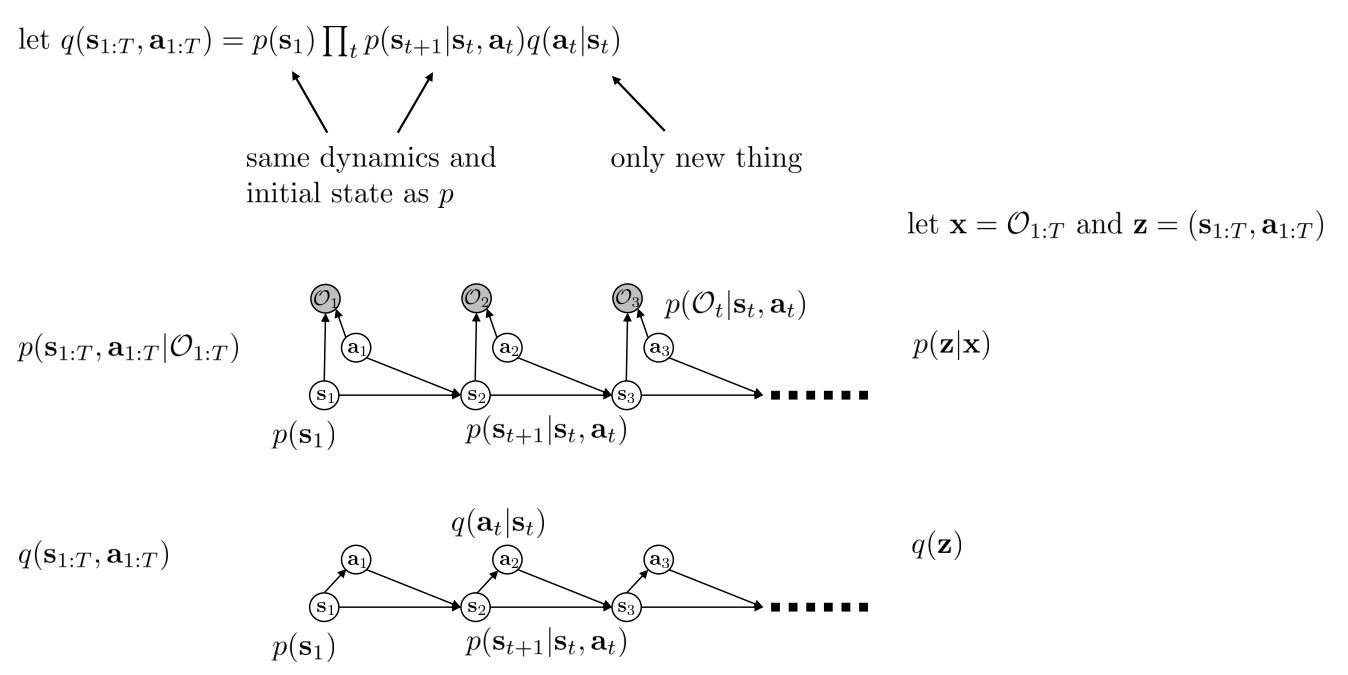
- \(q(s_{1:T}, a_{1:T})\) 분포로 \(p(s_{1:T}, a_{1:T} \vert \mathcal{O}_{1:T})\) 를 근사하면 어떻까(단 dynamics \(p(s_{t+1} \vert s_t, a_t)\) 하에서)?
- \(x = \mathcal{O}_{1:T}\), \(z = (s_{1:T}, a_{1:T})\) 로 두어서 \(p(z \vert x)\) 를 \(q(z)\) 로 근사해보자!
과정1



Algorithms for RL as Inference¶
Q-Learning with soft optimality¶

Benefits of Soft Optimality¶
- exploration을 향상시키고 entropy collapse를 방지할 수 있음
- policies를 더 쉽게 fine-tuning 할 수 있음
- 더 로버스트함. 더 많은 state를 커버하기 때문