CS 285: Lecture 20, Inverse Reinforcement Learning
영상링크: https://youtu.be/EcxpbhDeuZw
Why should we worry about learning rewards?¶
- Imitation Learning 관점: 로봇과 다르게 사람은 모방하는 과정에서는 행동(action)을 모방하지 않고, 의도(intent)를 모방하려고 함. 이는 다양한 다른 행동을 만들어 낼 수 있음.
Inverse Reinforcement Learning¶
- IRL은 demonstrations으로부터 reward function을 학습하는 것을 목표로 함.

Feature matching IRL¶
- Linear reward function: \(r_\psi(s, a) = \sum_i \psi_i f_i(s,a) = \psi^T f(s, a)\)
- 중요한 feature의 expectation을 매칭하는 과정
- \(\pi^{r_\psi}\) 를 optimal policy 라고하면 원하는 것은 \(\Bbb{E}_{\pi^{r_\psi}}[f(s, a)] = \Bbb{E}_{\pi^{*}}[f(s, a)]\) 를 만족하는 \(\psi\) 를 찾는 것.
maximum margin priciple
\[ \underset{\psi, m}{\max}\ m \quad \text{s.t.} \quad \psi^T \Bbb{E}_{\pi^{*}}[f(s, a)] \geq \underset{\pi in \Pi}{\max}\ \psi^T \Bbb{E}_\pi \lbrack f(s, a) + m \rbrack \]
- 휴리스틱함
- 그래서 SVM으로 해결해보려고 함

Learning the Reward Function¶

- The optimality variable를 학습하여 reward function을 추정하자
- \(p(\mathcal{O}_t \vert s_t, a_t, \psi) = \exp \big( r_\psi (s_t, a_t) \big)\)
- demonstations from \(\pi^*(\tau)\): \(\lbrace \tau_i \rbrace\)
- \(p(\tau \vert \mathcal{O}_{1:T}, \psi) \propto p(\tau) \exp \big( \sum_t r_\psi (s_t, a_t) \big)\), 여기서 \(p(\tau)\)는 \(\psi\)과 독립이기 때문에 생략 가능
- Maximum likelihood learning: \(\underset{\psi}{\max}\ \dfrac{1}{N}\sum_{i=1}^N \log p(\tau_i \vert \mathcal{O}_{1:T}, \psi) = \underset{\psi}{\max}\ \dfrac{1}{N}\sum_{i=1}^N r_\psi (\tau_i) - \log Z\)
- \(Z\)가 학습을 힘들게함
The IRL Particion function¶
- \(Z = \int p(\tau) \exp \big( \sum_t r_\psi (s_t, a_t) \big)\), \(\underset{\psi}{\max}\ \dfrac{1}{N}\sum_{i=1}^N r_\psi (\tau_i) - \log Z\)
- gradient: \(\triangledown_\psi L = \dfrac{1}{N} \sum_{i=1}^N \triangledown_\psi r_\psi (\tau_i) - \dfrac{1}{Z} \int p(\tau) \exp \big( \sum_t r_\psi (s_t, a_t) \big) \triangledown_\psi r_\psi (\tau) d\tau\)
- \(\dfrac{1}{Z} \int p(\tau) \exp \big( \sum_t r_\psi (s_t, a_t) \big) = p(\tau \vert \mathcal{O}_{1:T}, \psi)\) 이기 때문에
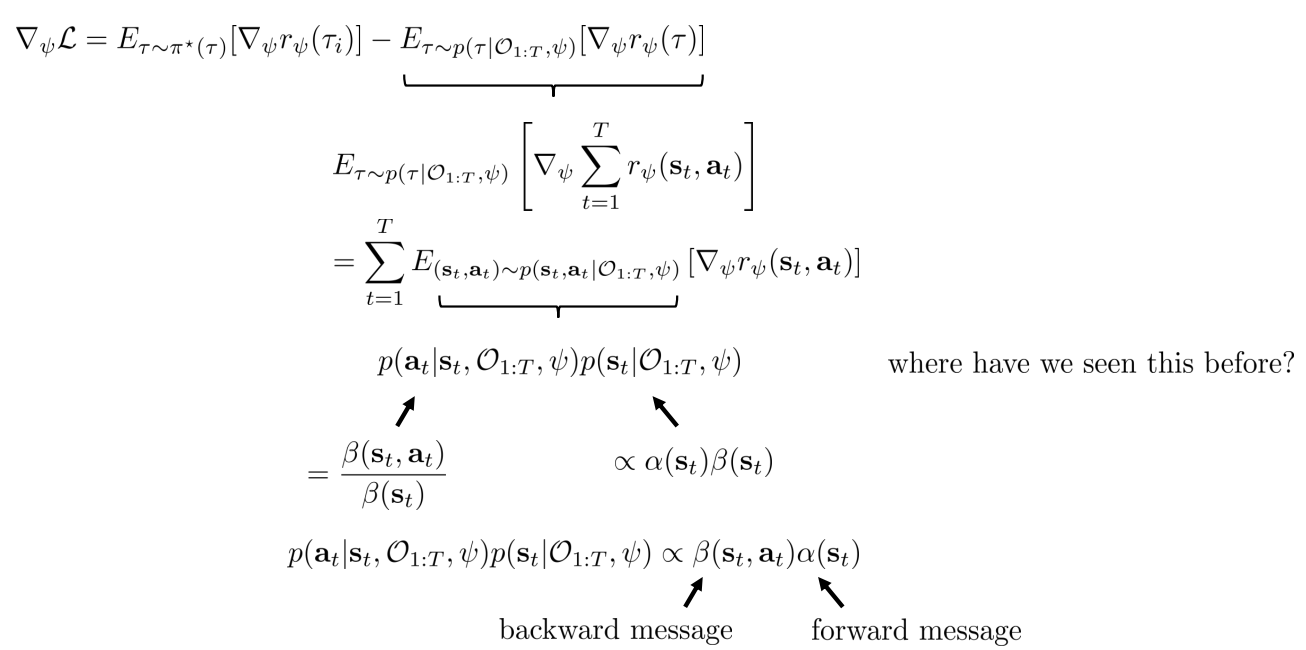
- \(\triangledown_\psi L = \Bbb{E}_{\tau \sim \pi^*(\tau)} \lbrack \triangledown_\psi r_\psi(\tau_i) \rbrack - \Bbb{E}_{\tau \sim \pi^*(\tau \vert \mathcal{O}_{1:T}, \psi)} \lbrack \triangledown_\psi r_\psi(\tau) \rbrack\)
- 앞의 항은 expert samples의 추정치이고, 뒤의 항은 현재 reward 하에서 soft optimal policy 다.
- 이를 풀어쓰면 backward message(\(\beta\))와 forward message(\(\alpha\))와 연관시킬 수 있음
Estimating the expectation¶

The MaxEnt IRL algorithm1¶

-
필요:
- Solving for (soft) optimal policy in the inner loop
- Enumerating all state-action tuples for visitation frequency and gradient
-
단점 및 한계점:
- Large and continuous state and action spaces
- States obtained via sampling only
- Unknown dynamics
Approximations in High Dimensions¶
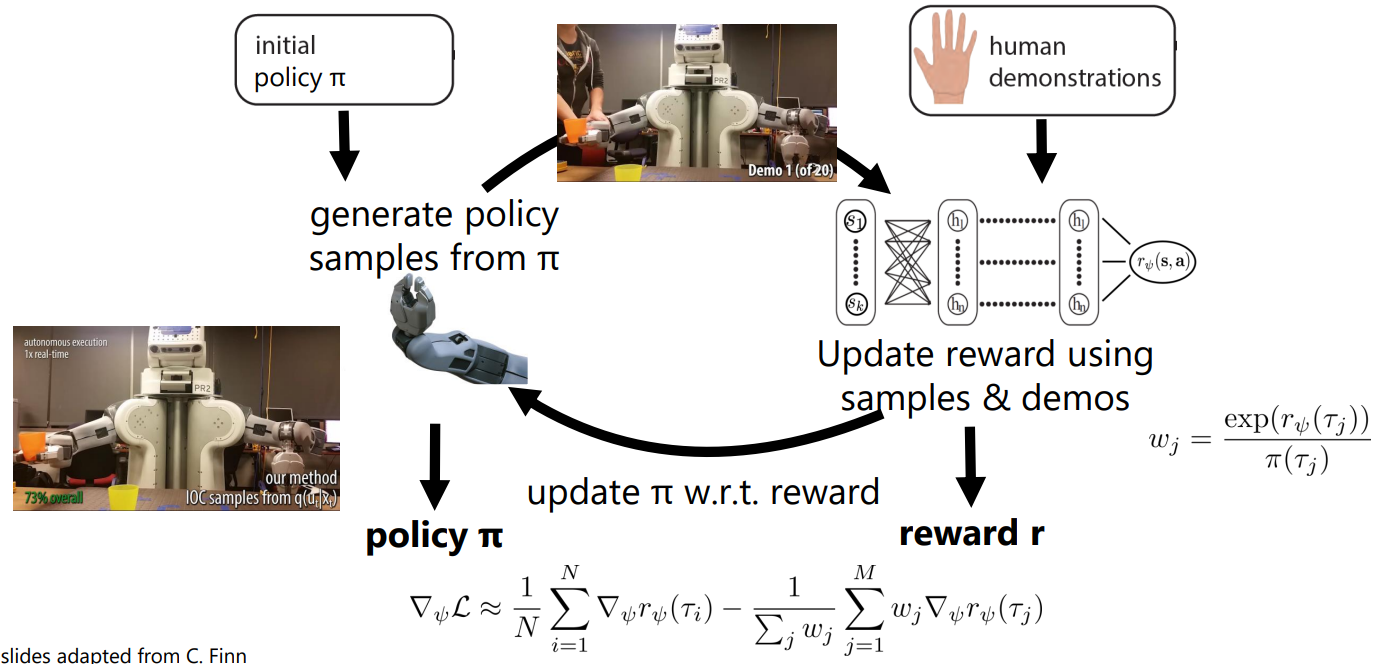
Guided cost learning algorithm2¶
- Unknown dynamics & large state/action spaces 일 경우 일반 강화학습처엄 sample 할 수 있음

- sample-based 방법으로 효율적인 업데이트가능


- policy samples를 먼저 생성 \(\rightarrow\) 사람 demonstrations과 같이 reward function을 추정 \(\rightarrow\) policy를 업데이트