3. Finite Markov Decision Processes
데이터사이언스 대학원 강화학습 수업, Deep RL Bootcamp1 를 듣고 정리한 내용입니다.
Markov Decision Processes (MDPs)¶
Markov decision process (MDP) is a discrete-time stochastic control process. 2
마르코프 결정 프로세스에서 행동(Actions)은 현재의 보상(Rewards)에 영향을 줄 뿐만 아니라 다음 상태(States)에도 영향을 준다.
Agent–Environment Interface¶
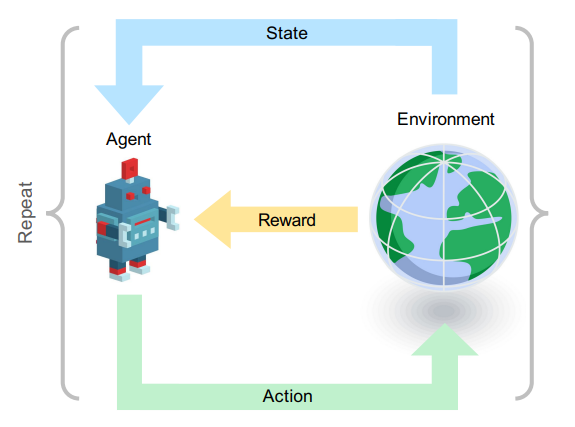
Agent-Environment Interface에서는 다음과 같은 상황을 서술한다. 매 time stamp \(t=0, 1, 2, \cdots\) 마다
- Agent는 상태(State) 정보 \(S_t \in \mathcal{S}\)를 받는다.
- Agent는 행동(Action) \(A_t \in \mathcal{A(s_t)}\)을 취한다.
- 한 스텝 이후(\(t+1\)), Agent는 보상 \(R_{t+1}\)을 받고 다음 상태 \(S_{t+1}\)가 결정된다.
따라서 이러한 상호작용은 일련의 시퀀스(혹은 trajectory) \(S_0, A_0, R_1, S_1, A_1, R_2, A_2, R_3, \cdots\) 를 생성한다.
Dynamics of MDP¶
Dynamics function은 두 개의 현재와 다음 상태(\(S_t\), \(S_{t+1}\)), 보상(\(R_t\)), 그리고 행동(\(A_t\))를 받아서 \(0\)과 \(1\)로 사이의 확률로 매핑해주는 함수다.
이 함수는 현재 상태, 행동이 주어졌을 때 다음 상태와 보상을 기술한다. \(s', s \in \mathcal{S}, r \in \mathcal{R}, a \in \mathcal{A(s)}\) 일때 확률은 다음과 같다.
Markov Property¶
"The future is independent of the past given the present."
Markov의 중요한 특성은 현 시점에서 모든 과거는 미래와 독립적인 관계라는 것이다. 상태 \(s\)가 Markov 특성을 지녔다라는 것은 다음과 같다. 모든 과거 정보 \(\lbrace S_0, A_0, \cdots, S_{t-1}, A_{t-1} \rbrace\)는 이미 상태에서 내포되어 있기 때문이라는 가정이 숨겨져 있다.
MDP dynamics \(p(s', r \vert s, a)\)를 사용하여 다른 항들을 계산 할 수 있다.
MDP calculation from dynamics

이 그림은 세 개의 State \(\mathcal{S} = \lbrace s_0, s_1, s_3 \rbrace\), 두 개의 행동 \(\mathcal{A} = \lbrace a_0, a_1 \rbrace\) 이 존재한다. 또한, \(+5\)와 \(-1\)을 제외하고 나머지는 모두 \(0\)의 보상을 가진다. 몇 가지 예제로 MDP를 이해해보자.
- \(s_1\) 상태에서 시작하여 \(a_0\)의 행동을 취한 경우, \(s_0\) 와 보상 \(r=5\)를 얻을 확률은 \(p(s_0, 5 \vert s_1, a_0) = 0.7\).
- \(s_1\) 상태에서 행동 \(a_0\)을 취했을 때, \(s_2\)로 전환될 확률은 \(p(s_2 \vert s_1, a_0) = 0.2\).
-
\(s_1\) 상태에서 행동 \(a_0\)의 기댓값:
\[\begin{aligned} r(s_1, a_0) &= 5 \cdot p(s_0, 5 \vert s_1, a_0) + 0 \cdot p(s_1, 0 \vert s_1, a_0) + 0 \cdot p(s_2, 0 \vert s_1, a_0) \\ &= 5 \cdot 0.7 + 0 \cdot 0.1 + 0 \cdot 0.2 = 3.5 \end{aligned}\]
MDP 프레임워크에서 경계값은 꼭 Agent의 물리적 경계값 일 필요는 없다. 또한, MDP 프레임워크에서 Agent는 환경(Environment)을 임의대로 변경 할 수 없다.
Reward Hypothesis¶
The goal of the agent is the maximization of the expected value of the cumulative sum of a received scalar (reward) signal.
Agent의 최종 목적은 보상 합의 기댓값을 최대화 하는 것이다. 목적을 달성하기 위해서 sub-goal를 추가하는 것이 도움이 될까? 도움이 될 수도 있고 안될 수 도 있다. 예를 들어, 체스게임에서 퀸을 잡는 것이 중요하다는 것을 sub-goal로 두어서 왕을 제외한 다른 모든 말들을 희생시켰다면, 이는 최종 목표인 게임 승리에 도움이 안된다(물론 적은 말들로 달성 했을 수도 있지만...).
Agent 목표 장기적인 보상 합의 최대화를 달성하기 위해서 기대 수익(expected return)을 \(G_t\) 라고 하면 두 가지 시나리오에서 수식으로 다음과 같이 정의 할 수 있다.
Expected Reward from difference scenario
여기서 \(\gamma \in \lbrack 0, 1 \rbrack\)는 할인율(discount rate)이라고 한다.
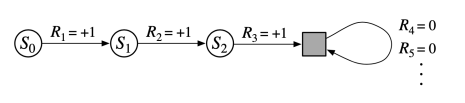
이러한 모형을 absorbing state라고 한다. \(T = \infty\) 혹은 \(\gamma = 1\)
Policies and Value Functions¶
Policy는 주어진 상태 \(S_t = s\) 에서 가능한 행동 \(A_t = a\)으로 매핑하는 함수 \(\pi_t(a \vert s)\)다. Policy 함수는 항상 확률 함수일 필요는 없다. 예를 들어 다음과 같은 deterministic policy 도 존재한다.
Policy가 확률 함수의 경우 선택된 행동의 실패 확률을 보통 noise라고 한다. 예를 들어, 특정 상태 \(s\)에서 \(a, a'\) 두 개의 행동을 선택할 수 있는 경우, \(\pi_t(a \vert s) = 0.9\) 이면 \(a\)를 선택할 확률이 90%이고, \(a'\)를 선택할 확률은 10%이다(noise).
\(\gamma\)는 할인율으로써 \(0 \leq \gamma \leq 1\)의 값을 가지며, 돈의 미래가치를 생각하면 이해가 된다. 현재 1만원을 가지고 있으면 지금은 1만원의 가치가 있지만, 내년에는 할인율에 따라 1만원 보다 적은 가치를 가지게 된다\((10000 \times gamma)\).
Value Function은 Policy가 주어졌을 때, 상태(혹은 상태-행동 쌍)가 얼마나 좋은 지를 평가하는 함수다. 왜 좋은지를 평가해야하고 좋은 평가는 무엇인지는 앞으로 차차 알아가 본다.
-
policy \(\pi\)하에 State-value function:
\[v_{\pi}(s) := \Bbb{E}_{\pi} \lbrack G_t \vert S_t = s\rbrack = \Bbb{E}_{\pi} \Bigg\lbrack \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \vert S_t = s \Bigg\rbrack\] -
policy \(\pi\)하에 Action-value function:
\[q_{\pi}(s, a) := \Bbb{E}_{\pi} \lbrack G_t \vert S_t = s, A_t = a\rbrack = \Bbb{E}_{\pi} \Bigg\lbrack \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \vert S_t = s, A_t = a \Bigg\rbrack\]
Bellman Equation¶
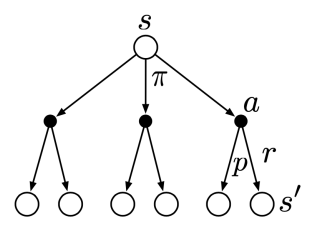
벨만 방정식(Bellman Equation)은 현재 상태(\(s\))의 value와 다음 상태(\(s'\))의 value 관계를 보여주는 식이다.
아래 그림은 bellman-backup diagram 이라는 그림인데, Bellman Equation을 잘 설명하고 있다. 즉, policy \(\pi\) 하에 현재 상태-가치(state-value) \(v_{\pi}(s)\) 는 모든 기대 수익을 각각의 행동에 따른 가중 평균을 구하는 것이며, 각 기대 수익은 할인된 다음 상태-가치 \(\gamma v_{\pi}(s')\) 와 다음 보상 \(r\)의 합을 가중 평균함으로써 구할 수 있다.
Example: Grid-World
아래의 좌측 그림 처럼 지도가 있는데, 네 개의 행동 \(\mathcal{A} = \lbrace N, S, E, W \rbrace\)을 취할 수 있다. 그리고 웜홀이 있어서 \(A\) 에서 \(A'\)로 전송하는 웜홀을 타면 \(+10\), \(B\) 에서 \(B'\)로가는 웜홀을 타면 \(+5\), 그리고 지도 밖을 벗어나면 \(-1\)를 받는 보상 상황이 주어졌다. 여기서 각각의 grid(네모칸)은 state라고 할 수 있다. 따라서, state transition은 결정적이다. 우측 그림은 state value를 구한 것이다. 우측 그림에서 볼 수 있듯이 A와 B grid(state)에서 높은 value를 갖는다.

Optimal Policies and Optimal Value Functions¶
Policy의 비교는 주어진 policy \(\pi\)하에서 state-value \(v_{\pi}(s)\) 가 높으면 좋은 것이다 (주의: state-value function이 항상 monotic한 것은 아니다). 따라서 최적의 policy \(\pi_{*}\)는 주어진 상태 \(s\)에서 다른 모든 policy 보다 좋은 state-value를 가지면 된다. 이 최적의 state-value를 optimal state-value function 이라고 하며 다음과 같이 정의 된다.
또한, 최적의 action-value function도 같이 정의할 수 있다.
Bellman Optimality¶
"The value of a state under an optimal policy must equal the expected return for the best action from that state."
\(v_{*}\)를 구하기 위한 Bellman Optimality Equation은 다음 수식과 같이 정의된다. 이 수식의 뜻은 최적의 policy \(\pi_{*}\) 하에 상태의 가치 \(v_{*}\)는 해당 상태에서 나오는 최적 행동의 기대 수익이다.
이전의 Bellman backup diagram과 다르게 최적 상태-가치(optimal state-value)를 구하기 위해서 \(v_{*}\) 이제는 기대 수익을 모든 행동에 대한 가중 평균 합이 아니라 최적 행동에 해당하는 기대 수익만 선택하면 되는 것이다. 그리고 최적 행동 가치(optimal action-value)는 선택된 최적 상태-가치를 보상에 대한 가중 평균 하면 되는 것이다.

또한 Bellman optimality equation은 \(v_*\)에 대해 단 하나의 유일한 솔루션을 가진다.
Example: Grid-World 에서의 optimal value function과 policy
중간의 그림이 optimal state-value 이고 우측은 optimal policy다. 각 state에서 여러 optimal policy를 가질 수 있지만, optimal state-value는 단 하나다. 예를 들어, 좌표 (4, 0)에서는 N으로 이동하던 E로 이동하던 모두 최적의 \(v_{*}\)를 얻을 수 있다.

ETC¶
두 개의 policy \(\pi_A\), \(\pi_B\)가 있는데, 어떤 state에서 optimal state-value가 \(\pi_A\)가 더 큰 경우가 있고, 어떤 state에서는 \(\pi_B\)가 더 크다. 그렇다면 optimal policy는 없는 것일까? 아니다. 각 state에서 state-value가 큰 policy를 선택해서 새로운 policy \(\pi_C\)를 만들면 된다. 따라서, 항상 \(v_{\pi}(s) \geq v_{\pi^{'}}(s)\)를 만족하는 \(\pi\)를 찾을 수 있다.