6. Temporal-Difference Learning
데이터사이언스 대학원 강화학습 수업을 듣고 정리한 내용입니다.
Temporal Difference Learning 방법은 Monte Carlo(MC)와 Dynamic Programming(DP)의 아이디어를 결합한 방식이다. MC와 비슷하게 경험으로부터 직접 배우고, DP처럼 학습된 추정치(V, Q, ...)로 다른 추정치를 업데이트 한다.
TD Prediction¶
Monte Carlo 업데이트 규칙(every-visit)을 생각해보면 다음과 같다.
여기서 \(G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots \gamma^{T-t-1} R_{T}\)다. 그리고 확인할 수 있는 것은 MC 방법은 \(V(S_t)\)를 결정하기 위해서 항상 에피소드의 끝까지 기다려야 한다.
하지만, TD는 다르다. One-step TD, TD(0)의 업데이트 규칙은 다음과 같다.
따라서 one-step TD 방법은 하나의 타임 스텝만 기다리면 업데이트 할 수 있다.
Tabular TD(0)

TD(0)가 기존에 추정된 값들을 기반으로 업데이트 하기 때문에 bootstrapping 방법이라고도 한다. 그러기에 오차(TD Error)도 존재한다. 오차는 현재의 추정치 \(V(S_t)\)와 TD의 목표인 \(R_{t+1} + \gamma V(S_{t+1})\)의 차이로 계산된다.
다만, \(t+1\) 시점에서 이 오차를 확인 할 수 있다.
Example: Driving-Home

책에서 소개한 차를 타고 집으로가는 예제를 보자. 집으로 가는데 얼마나 걸리는 지를 예측하고 싶다. 그림과 같이 6개의 state가 있고, 실제 걸린 시간(Elapsed Time)과 예측된 남은 시간(Predicted Time to Go)이 있다. 매 State가 변할 때마다 예측된 남은 시간은 달라진다. 여기서 Reward는 실제 걸린시간이 된다.
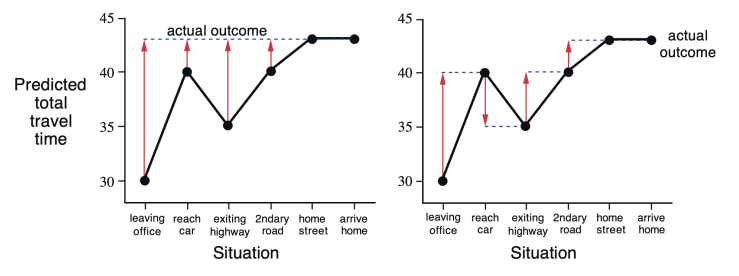
위 그림은 MC 방법과 TD 방법의 차이를 극명하게 보여주고 있다. y 축은 예측된 전체 소모 시간(=\(V(S_t)\))을 나타나는데, 빨간색 화살표가 가르치는 것은 각각 MC의 \(G_t\)와 TD(0)의 \(R_{t+1}+\gamma V(S_{t+1})\)를 나타낸다(\(\gamma=1\)). 예를 들어, Reach Car 상태에서 MC 방법의 \(G_t\)는 해당 에피소드의 최종 시간 43분이 return이 되는데, TD(0)의 경우 다음 타임스텝의 \(R_{t+1}=20\)과 \(V(S_{t+1})=15\)의 합이 된다. 따라서, 집에 도착 할 때까지 기다릴 필요없이 value를 업데이트 할 수 있다.
Example: Chain MDP

두 번째 예시로 5개의 state를 가지고, \(C\) 에서 시작하는 Markove reward process(MRP)가 있다. \(E\) 오른쪽 Terminal state \(T\) 에 도달할 경우만 1의 보상을 얻고 나머지는 0을 얻는다.
해당 MRP의 true value는 bellman equation \(V_\pi(s) = \sum_{r, s'} p(r, s' \vert s) (r + V(s'))\)을 이용할 수 있다. 여기서 policy \(\pi\)는 deterministic하기 때문에 어떤 액션을 취하든 \(\pi(a \vert s)=1\) 이다. 그리고 state transition probability \(p(r, s' \vert s)=0.5\)이다(좌로 가든 우로가든 반반이다). 또한, \(V(T)=0\)이다. 따라서 다음과 같이 계산된다1
따라서 \(V(A)\)를 차례대로 \(V(E)\)까지 대입하면 \(V(A) = 1/6\)이 된다.
아래 있는 그림 중 왼쪽은 TD(0) 방법을 사용 했을 때, 경험을 반복 할 때마다 emsimated 한 value function이 실제 값(검은선)에 근접하는 것을 확인 할 수 있다. 오른쪽 그림은 MC 방법과 TD 방법이 learning rate \(\alpha\)의 차이에 따라 실제 값의 차이를 episode의 흐름에 따라 표시한 것이다.
SARSA¶
보통 우리는 진짜 모델을 모르기 때문에, \(v_\pi(s)\) 보다 대신에 \(q_\pi(s, a)\) 학습할 수 있게 한다. SARSA의 업데이트 방식은 다음과 같다.
Sarsa (on-policy TD Control)

여기서 Greedy in the Limit with Infinite Exploration(GLIE)라는 가정이 들어간다.
-
모든 state-action 쌍은 무한의 횟수로 탐색이 가능하다는 것이다.
\[\lim_{t \rightarrow \infty} N_t(s, a) = \infty\] -
또한, policy는 greedy policy으로 수렴한다. 즉, state-action 쌍의 추정치가 개선됨에 따라 policy가 점점 결정론적으로 항상 최대의 가치를 가지는 policy가 된다는 뜻이다.
\[\lim_{t \rightarrow \infty} \pi_t(a \vert s) = \Bbb{1} \bigg\lbrack a = \underset{a'}{\arg\max} Q_k(s, a') \bigg\rbrack \]
예를 들어, \(\epsilon\)-greedy에서 \(\epsilon = \dfrac{1}{t}\)으로 설정하면 이는 GLIE를 만족하는 방법이다.
Convergence of SARSA¶
아래의 조건하에 SARSA는 최적의 action-value function으로 수렴한다 \(Q(s, a) \rightarrow q_*(s, a)\):
- \(\pi_t(a \vert s)\) 가 GLIE를 만족한다.
- 학습률(learning rate = step size)가 확률적 수렴에 만족한다.
Windy grid world

한번 움직일 때마다 \(-1\)의 보상, \(\gamma = 1\)인 바람이 부는 grid world 예제다. 뒤에 있는 빨강색 그래프는 에피소드가 끝날 때까지 걸린 Time steps를 \(x\)축, episode는 \(y\) 축에 드려지고 있다. 예를 들어 그래프 처럼 첫번째 eposide는 거의 1500대에 종료가 되었고 그 다음 에피소드는 대략 2100번 초반에 위치한 것으로 보인다. Pseudo Code로 다음과 같이 쓸 수 있다.
import matplotlib.pyplot as plt
episodes = [[1]*1500 + [2]*600 + ... [episode번호]*종료까지_걸린_횟수 ]
plt.plot(episodes)
plt.xlabel('time steps')
plt.ylabel('episodes')
plt.show()
\(\epsilon = 0.1, \alpha = 0.5\)를 적용했을 시, 우리는 시간이 지날 수록 목적에 더 빨리 도달함을 알 수 있다.
Q-Learning¶
Q-Learning은 SARSA와 비슷하지만, 다음 state의 action을 greedy하게 선택한다는 점이 다르다. 즉, \(Q(S_{t+1}, A_{t+1})\) 대신에 \(Q(S_{t+1}, \underset{a'}{\arg\max} Q(S_{t+1}, a'))\)를 사용한다. 다음 policy에 관계없이 최적의 action-value function을 추정한다.
Q-Learning (off-policy TD Control)

Q-Learning은 off policy이다. 학습하고자 하는 target policy는 \(\pi(a \vert S_t) = \underset{a'}{\arg \max}\ Q(S_t, a')\)이며, action을 선택하는 behavior policy는 \(\pi\)과 같지 않다. 예를 들어, \(\epsilon\)-greedy가 될 수가 있다. 즉, Q-Learning에서의 state-action쌍에 대한 return은 greedy policy을 가정하여 업데이트 하는데, 실제로는 greedy 하지 않기 때문이다. 반면에 SARSA가 on policy인 이유는 Q-values를 다음 state \(s'\)와 현재 policy에 의해 결정되는 action \(a'\) 를 사용하여 업데이트하기 때문이다.
Cliff Walking

- 조건: undiscounted, episodic, deterministic environment
- Action: 4개(상, 하, 좌, 우)
- Reward: 모든 state에서 -1 이지만, "The Cliff"에서는 -100의 보상을 받고 즉시 Start state \(S\)로 돌아간다.
- \(\epsilon\)-greedy policy를 사용하며 \(\epsilon = 0.1\)로 설정한다.

위 그림은 Sarsa와 Q-Learning을 비교한 것이다. Q-Learning이 각 에피소드 별로 더 많은 negative reward를 얻는 것을 볼 수 있다. 이는 고정적인 \(\epsilon\)을 사용하기도 하고, Q-Learning이 항상 최대의 Q-value에 근거하여 action을 선택하기 때문에, 더 많이 cliff로 떨어질 가능성도 높다.
다만, \(\epsilon\)을 줄이는 전략을 택했다면, 두 방법다 optimal policy에 접근할 수 있다.
Expected SARSA¶
Expected SARSA의 업데이트 규칙은 다음과 같다.
Expected SARSA는 SARSA 보다 계산적으로 복잡하지만, action 선택에 있어서 variance 줄여주기 때문에 조금 더 안정적이다.