8. Planning and Learning with Tabular Methods
데이터사이언스 대학원 강화학습 수업을 듣고 정리한 내용입니다.
지금까지는 model-based와 model-free 방법들을 다루어 보았다.
- Model-based (e.g., Dynamic Programming)은 planning에 초점이 맞춰져있다.
- Model-free (e.g., Monte Carlo, Temporal Difference)은 learning에 초점이 맞춰져있다.
Planning¶
planning은 model을 입력으로하고 policy를 출력으로하는 어떤 계산 프로세스로 정의된다.
- State-space planning: state space에서 optimal policy를 찾는 과정. Actions는 state과 state 사이의 transition을 야기하며, value function는 state로 계산된다.
- Plan-space planning: plan space를 찾는 과정. 하나의 plan에서 다른 plan으로 변경하는 연산(operators)을 찾는 것이다.
우선 같은 structure을 공유하는 state-space planning만 알아본다. Policy를 개선하기 위해서 value function을 계산하고, simulated experiences가 value function을 계산하는데 근거가 되어준다.
Planning & Learning¶
Planning과 Learning의 차이점은 학습에 사용되는 경험 종류다. Planning은 model에서 생성된 simulated experience를 사용하고, Learning은 환경에서 생성된 real experience를 사용한다. 보통 두 방법을 결합해서 사용하는데 대표적인 예로 "the planning method based on Q-learning"이 있다.
random-sample one-step tabular Q-planning

- 2번에서 보통 real experience를 쓰지만, sample method가 사용되었다.
Dyna-Q: Integrated Planning and Learning¶
| Dyna | General Dyna |
|---|---|
 |
 |
Dyna-Q는 online planning agent의 주요 functions을 포함하는 간단한 아키텍쳐다. Online 상황에서 planning, acting, learning을 결합한 방법이다.
- Model-Learning: real experience로 model을 학습하는 것으로, 환경을 조금 더 잘 정확하게 따라할 수 있도록 한다.
- Direct RL: 강화학습으로 value function과 policy 을 개선하는 과정.
- Indirect RL: model을 통해 value function과 policy를 개선하는 과정.
- Planning: model을 통해 simulated experience를 생성하고, 이를 통해 value function과 policy을 개선한다.
- Search Control: simulated experience를 생성하기 위해 starting state와 action을 선택해서 model에 입력하는 과정.
Tabular Dyna-Q

- 여기서 (e) 와 (f) 과정이 없으면 one-step tabular Q-learning과 동일하다.
Dyna Maze
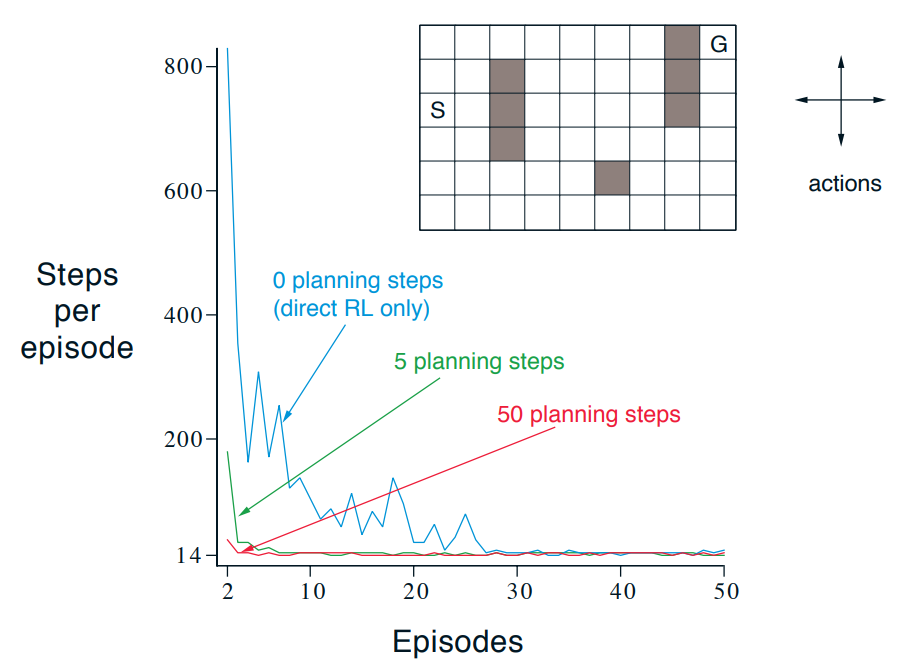
미로 문제에서 Dyna-Q를 적용한 결과다. Dyna-Q는 planning을 통해 더 많은 경험을 얻어서 더 빠르게 optimal policy를 찾을 수 있다.
- 모든 episode는 \(S\)에서 시작한다. 미로의 밖같과 검은 장애물은 지나갈 수 없다.
- Actions = 상, 하, 좌, 우
- Reward = \(G\)에 도착시 \(+1\), 나머지는 \(0\).
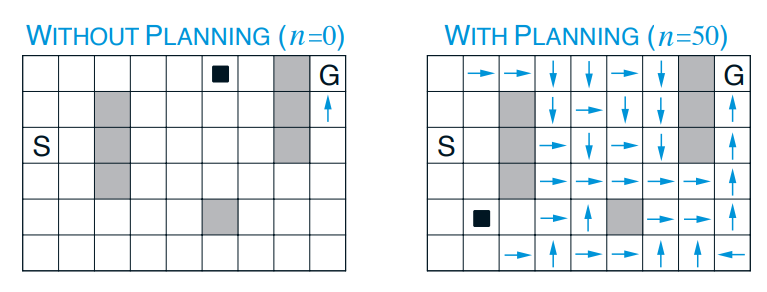
위 그림은 두번째 episode에서 Planning 유무에 다른 policy 차이를 보여준다. Planning의 유무에 따라서 optimal policy를 찾는 속도가 달라진다.
When the Model is Wrong¶
Model이 항상 옳은 것은 아니다. 예를 들어, (1) 환경이 stochastic하고, 경험의 갯수가 충분치 않을 때, (2) 일반화가 잘 되지 않을 때, (3) 환경이 변했는데 model이 관찰하지 못하는 경우 등이 있다. 다음 예제를 한 번 보자. Dyna-Q+는 조금 있다 다룬다.
Example: Blocking and Shorcut Maze

간단한 미로이지만 1000 time steps 이후에 장벽으로 생긴 블록이 오른쪽으로 한칸 이동한다. 처음에 최적의 경로는 오른쪽으로 탐색하는 것이고 블록이 옮겨지면 왼쪽으로 찾는 것이 최적의 경로다.

간단한 미로이지만 3000 time steps 이후에 장벽의 오른쪽이 뚫리며 숏컷이 생긴다. 처음에 최적의 경로는 왼쪽으로 탐색하는 것이고 블록이 사라지면 오른쪽으로 찾는 것이 최적의 경로다. 그러나 Dyna-Q는 블록이 사라지고 나서 최적의 경로를 찾지 못하고 이전의 경로에 만족하는 모습을 보인다(cumulateive reward의 기울기가 급격하게 상승하지 않는다). Exploration-exploitation trade-off가 존재한다.
Dyna-Q+¶
Dyna-Q+는 각 state-action 쌍이 지난번 시도 이후로 얼만큼 오랫동안 경과했는지 기록하는 휴리스틱한 방법이다. 시간이 오래되었을 수록 해당 state-action 쌍에 대한 모델의 지식이 잘못 되었다는 것을 알려주기 위함이다. 그래서 보상에 경과된 시간을 추가하여 업데이트 한다.
- \(\kappa\)는 경과된 시간에 대한 보상의 가중치이다. \(\kappa\)가 크면 경과된 시간이 길어질수록 보상이 커지고, \(\kappa\)가 작으면 경과된 시간이 길어질수록 보상이 작아진다.
Prioritized Sweeping¶
Dyan-Q Planning 단계에서 랜덤하게(uniformly) 경험들을 선택해서 해당 state-action 쌍의 value를 업데이트 했다. Uniformly 하게 샘플링하지 말고 다른 방법으로 할 수 있다.
- Backward-focusing: value 가 업데이트 된 state-action 쌍부터 거꾸로 planning을 진행하는 방법
- Prioritized Sweeping: value의 업데이트 변동성이 큰 state-action 쌍부터 planning을 진행하는 방법
구체적으로 우선순위 큐(priority queue)를 사용하여 value의 변동량이 특정 값 \(\omega\)를 넘기면 우선순위 큐에 넣는다. 그리고 해당 큐에서 dequeue해서 simulated experience를 생성하여 Q-Learning을 진행한다. 만약에 이 과정에서 value의 변동량이 또 \(\omega\)를 넘으면 다시 큐에 넣는다.
Prioritized Sweeping

Trajectory Sampling¶
Dynamic Programming에서 모든 state를 방문해서 value를 업데이트 했는데 이를 exhaustive sweep이라고 한다. 일단 dynamics를 알아야 하지만, 모든 state를 탐색한다는 것은 현실에서 거의 불가능하다. 그래서 특정 분포를 가지는 state space를 샘플링하여 planning을 하게 된다. Dyna-Q에서는 Uniform sampling을 사용했다. Trajectory Sampling은 on-policy distribution에 따라 샘플링을 한다. 주어진 model로 state transitions와 rewards을 샘플링하고, 현재 policy를 기반으로 action을 샘플링한다.
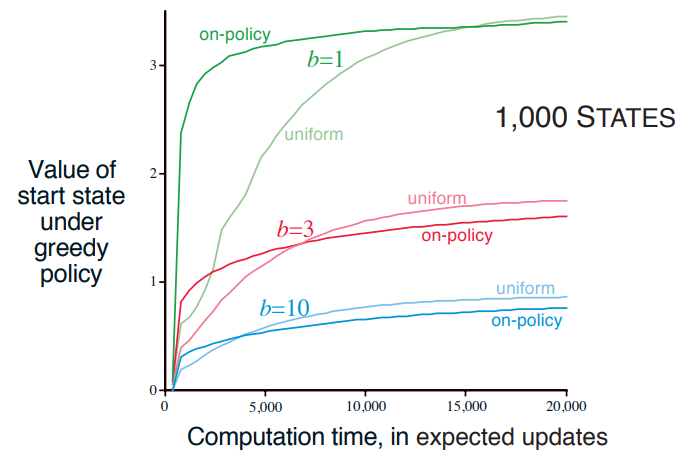
위 그림에서 b는 branching factor이다.
the branch factor refers to the number of possible actions that an agent can take at each state in the environment.
On-policy distribution을 사용의 장단점은 다음과 같다.
- 장점: 중요하지 않은 state 혹은 state-action 쌍을 무시할 수가 있다.
- 단점: model이 잘못되었을 때, 잘못된 state 혹은 state-action 쌍을 계속해서 샘플링하게 된다.
Real-time Dynamic Programming (RTDP)¶

Dynamic Programming에서 valute iteration을 on-policy trajectory sampling로 하는 방법이 Real-time Dynamic Programming (RTDP)이다. 다음 수식을 사용하여 state-action 쌍이 주어졌을 때(real experience 혹은 simulated experience) value를 업데이트 한다.
좌측의 그림과 같이 지정된 시작 states에서 시작하여 도달가능한 state들(=유용한 states)을 업데이트 한다. Optimal policy를 찾기 위해서 필요없는 states, 즉 경로에 도달 할 수 없는 states는 업데이트 하지 않기 때문에, 필요없는 action을 선택할 필요가 없다. Optimal poilcy와 관련 없는 state에 대해서 임의의 action을 지정하거나 선택하지 않는 policy를 optimal partial policy라고 한다.
하지만 optimal partial policy를 찾기 위해서는 모든 state를 방문해야 할 수도 있다. 특정 문제에서 RTDP는 모든 state 방문없이 optimal policy를 찾을 수 있다.
Planning at Decision Time¶
지금까지 현재 state \(S_t\)에서 선택한 action 뿐만 아니라 과거 경험 했던 state에서 action을 선택할 때에도 planning을 사용했다. 이러한 과정을 Background Planning이라고 한다.
그러나 Decision-time Planning에서는 현재 state \(S_t\)에서 action을 선택하기 위해서만 planning을 사용한다. 그리고 State value를 사용할 수 있을 때만 planning을 진행하며, 각 state에서 model이 예측한 value를 기반으로 action을 선택한다.
- Decision-time Planning은 빠른 응답이 필요하지 않은 Environment에서 유용
Heuristic Search¶
Heuristic Search는 매 State 방문마다 tree를 생성하여 planning을 진행하는 방법이다. Tree의 리프 노드에 추정한 value function을 적용하고, 현재 state를 root node로 두어 리프 노드부터 루트까지 거꾸로 올라가는(Backup) 방식으로 탐색을 진행한다. 아래 그림은 DFS(Depth First Search)를 사용한 예시이다.

Rollout Algorithms¶
Rollout Algorithm은 현재 state에서 시작하여 simulated trajectory에 적용된 Monte Carlo Control을 기반으로 planning을 진행하는 방법이다. 현재 state의 가능한 action에서 주어진 policy를 따라 simulated trajactory의 reward 평균을 계산하여 action value를 추정한다. 추정한 action value가 충분히 정확하다고 판단되면 가장 높은 추정값을 갖는 action이 선택되고, 그 action의 결과로 생성된 다음 state에서 해당 과정이 반복된다.
Monte Carlo Tree Search (MCTS)¶
Monte Carlo Tree Search (MCTS)는 Rollout Algorithm에 기반하지만 Monte Carlo simulations에서 얻은 value 추정값을 누적하여 확장한 버전이다. 시뮬레이션에서 보다 높은 reward를 받는 trajectory로 더 유도하기 위해서 고안되었다.
MCTS는 action을 선택하기 위해 새로운 state를 방문했을 때 실행된다. MCTS의 핵심 아이디어는 이전 시뮬레이션에서 높은 평가를 받은 trajectory의 초반부분을 확장하여 현재 state에서 연속적으로 여러 번의 시뮬레이션을 행할 수 있게 하는 것이다.
다음 그림으로 구체적인 MCTS의 과정을 살펴보자123.
MCTS Illustration
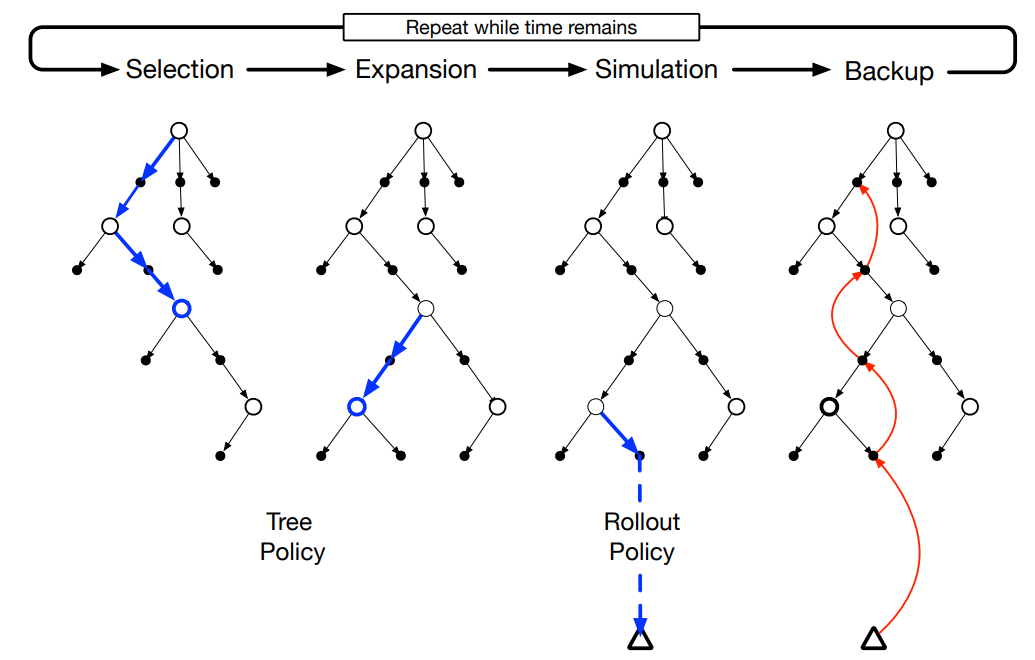
- Selection: 자식 노드 선택 policy를 재귀적으로 적용하여, Root 노드에서 가장 중요 확장 가능한(urgent expandable) 노드로 트리를 따라 내려간다. "확장 가능한"이란 노드가 비 종료 상태이고 방문하지 않은 자식들(unexpanded 포함)을 뜻한다. 여기서 leaf node는 제일 끝에 있는 노드가 아니라 확장 가능한 노드를 뜻한다.
- Expansion: 가능한 action에 따라 하나 이상의 자식노드가 추가되서 트리를 확장한다.
- Simulation: Rollout Policy에 따라 새 노드들에서 시뮬레이션을 실행하여 결과를 생성한다.
- Backup(Backpropagation): 시뮬레이션 결과(backed up)를 사용하여 트리를 업데이트한다. Rollout Policy에 의해 Tree의 밖에서 방문한 state 및 action에 대한 정보는 저장하지 않는다(Expansion 단계에서 확장된게 아니면 저장하지 않음).


