2024 · Published · SIGIR-AP 2024
AU-RAG
문서, 테이블, 데이터베이스, API처럼 서로 다른 데이터 소스를 에이전트가 찾아 쓰게 만든 RAG 구조입니다.
An agent-based universal RAG framework for large, heterogeneous, and frequently changing enterprise data sources.
기업 데이터는 한 벡터 DB에 모두 넣기 어렵습니다. AU-RAG는 데이터 소스를 설명하는 메타데이터와 예시 기반 retrieval action을 이용해 필요한 소스를 동적으로 찾고 정보를 추출합니다.
AU-RAG studies how RAG can work when enterprise knowledge is spread across static documents, tables, databases, and API-only dynamic sources that cannot all be pre-encoded into vectors.
01 · 배경 Background
모든 소스를 벡터화할 수 없을 때
When Not Everything Can Be Vectorized
RAG는 LLM이 모르는 정보를 외부 자료에서 찾아 답변에 넣어 주는 방식이다. 보통은 문서를 작은 조각으로 나누고, 각 조각을 벡터로 저장한 뒤, 질문과 의미가 가까운 조각을 검색한다.
이 방식은 고정된 문서 모음에서는 잘 맞을 수 있다. 하지만 기업 환경에서는 데이터가 문서, 표, 데이터베이스, 내부 시스템, 외부 API처럼 여러 형태로 흩어져 있다. 어떤 데이터는 너무 크고, 어떤 데이터는 계속 바뀌며, 어떤 데이터는 API를 호출해야만 최신 값을 얻을 수 있다.
보안, 저작권, 운영 정책 때문에 모든 내용을 복사해서 벡터 DB에 넣을 수 없는 경우도 많다. 또 벡터 검색은 “비슷한 문장”을 찾는 데 강하지만, 특정 데이터 소스를 고르고 그 안에서 필요한 행, 표, 값, API 응답을 꺼내는 절차까지 자동으로 해결해 주지는 않는다.
AU-RAG는 이런 문제에서 출발했다. 모든 내용을 미리 embedding으로 바꾸는 대신, 데이터 소스를 설명하는 Source Object를 만들고, 분석가가 남긴 예시를 Extraction Guide로 저장한다. 에이전트는 이 예시를 참고해 어떤 소스를 선택하고 어떤 retrieval action을 수행할지 결정한다.
RAG helps an LLM answer questions by retrieving external information and adding it to the prompt. The standard approach chunks documents, embeds each chunk, and searches for chunks that are semantically close to the question.
This works well for stable document collections, but enterprise data is spread across documents, tables, databases, internal systems, and external APIs. Some sources are too large, some change frequently, and some can only be accessed by calling an API.
Governance, copyright, and security constraints can also prevent copying all content into a vector database. In addition, vector search finds similar text, but it does not fully solve the procedural problem of selecting a source and extracting the right row, table, value, or API response.
AU-RAG starts from this limitation. Instead of pre-embedding everything, it represents data sources as Source Objects and stores analyst examples as Extraction Guides. The agent uses these guides to decide which source to select and which retrieval action to perform.
02 · 방법 Method
Source Object와 Extraction Guide
Source Objects and Extraction Guides
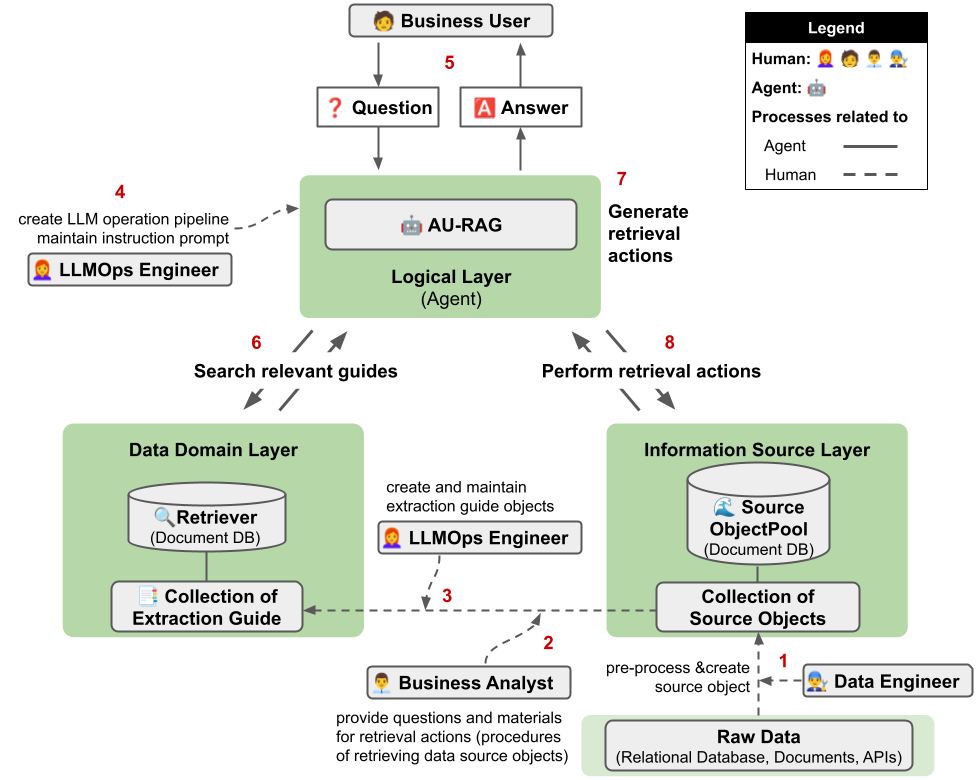
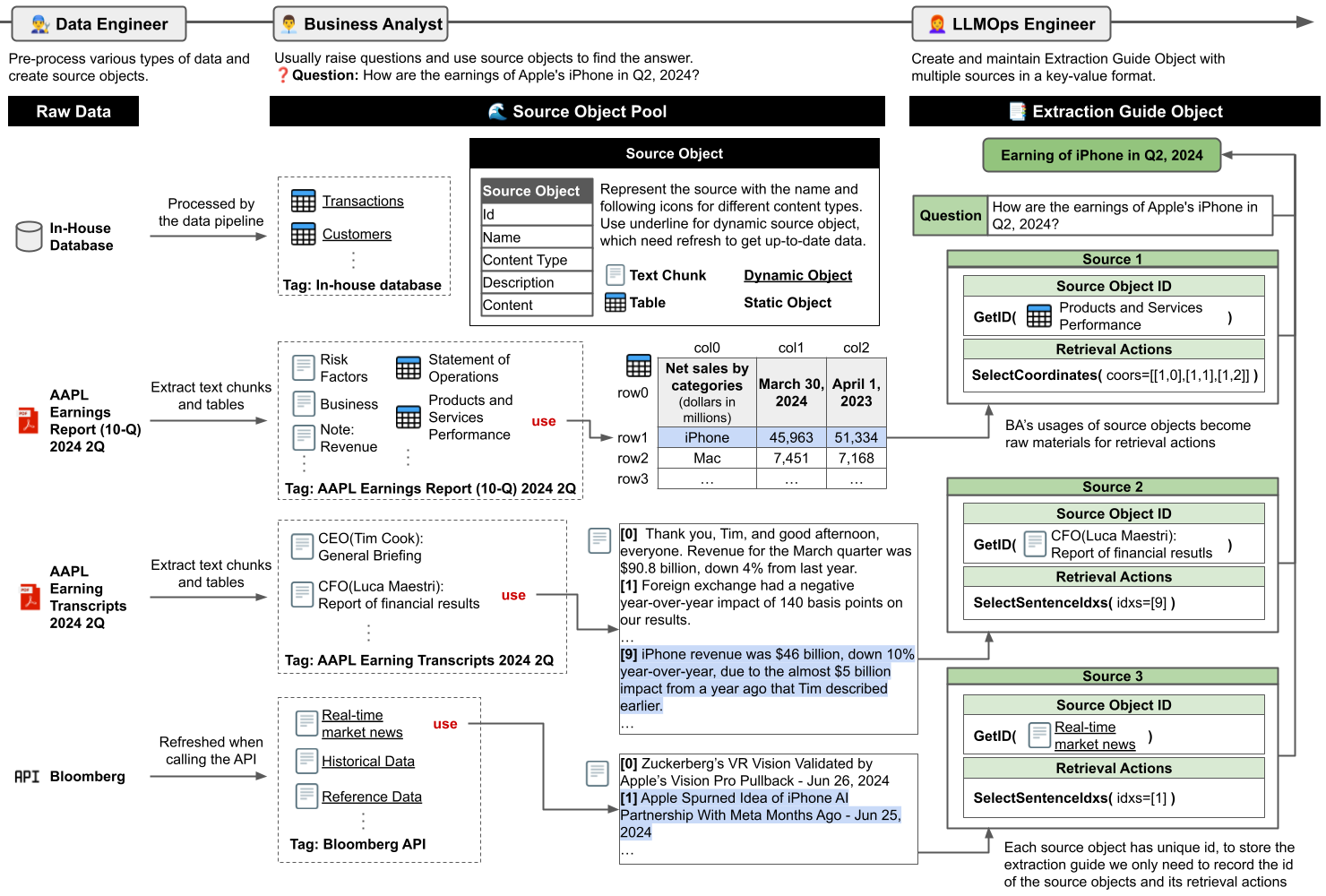
AU-RAG의 첫 번째 단위는 Source Object다. 문서 조각, 문서 안의 표, 데이터베이스 테이블, API 호출 결과처럼 서로 다른 원천 데이터를 같은 형식의 객체로 감싸고, 설명, 태그, 타입, 원천 위치 같은 메타데이터를 붙인다.
Source Object는 static과 dynamic으로 나뉜다. PDF 문단이나 문서 표처럼 거의 바뀌지 않는 것은 static source이고, 데이터베이스나 API처럼 호출할 때 최신 값이 필요한 것은 dynamic source다. Dynamic source는 `refresh` 메서드를 통해 최신 데이터를 다시 가져올 수 있게 설계했다.
두 번째 단위는 Extraction Guide다. 비즈니스 분석가가 어떤 질문을 풀 때 어떤 소스를 골랐고, 그 안에서 어떤 행이나 문장을 선택했는지를 예시로 남긴다. 이 예시는 단순 답안이 아니라 “어디에서 무엇을 꺼냈는가”를 보여주는 절차 지식이다.
새 질문이 들어오면 AU-RAG는 먼저 비슷한 Extraction Guide를 찾고, 그 예시를 바탕으로 후보 Source Object를 고른다. 그다음 에이전트가 각 소스에 맞는 retrieval action을 만든다. 표라면 좌표나 행/열을 고르고, 텍스트라면 필요한 문장 index를 고르는 식이다.
마지막에는 추출한 context로 답변을 만들고, 충분하지 않으면 다시 소스를 찾거나 추출을 반복한다. 이 논문은 MCP 서버 이전의 작업이라, 현재의 tool server 개념보다는 source object와 retrieval action으로 문제를 정리했다.
The first unit is the Source Object. Text chunks, document tables, database tables, and API outputs are wrapped in a common object format with descriptions, tags, content types, and source metadata.
Source Objects are divided into static and dynamic sources. PDF paragraphs and document tables are static, while databases and APIs are dynamic because they may need the latest value at access time. Dynamic sources include a `refresh` method for reloading current content.
The second unit is the Extraction Guide. It records how a business analyst answered a question: which sources were selected and which rows, columns, or sentences were extracted. This is procedural knowledge, not just a final answer.
Given a new question, AU-RAG retrieves similar Extraction Guides and uses them to select candidate Source Objects. The agent then generates retrieval actions suited to each source type, such as selecting table coordinates or sentence indices.
The extracted context is used to generate an answer, and the system can repeat source selection or extraction if the context is insufficient. This paper predates the current MCP-server framing, so the design is expressed through source objects and retrieval actions rather than external tool servers.
03 · 결과 Results
정확한 소스를 더 선택적으로 찾기
Selective Source Retrieval
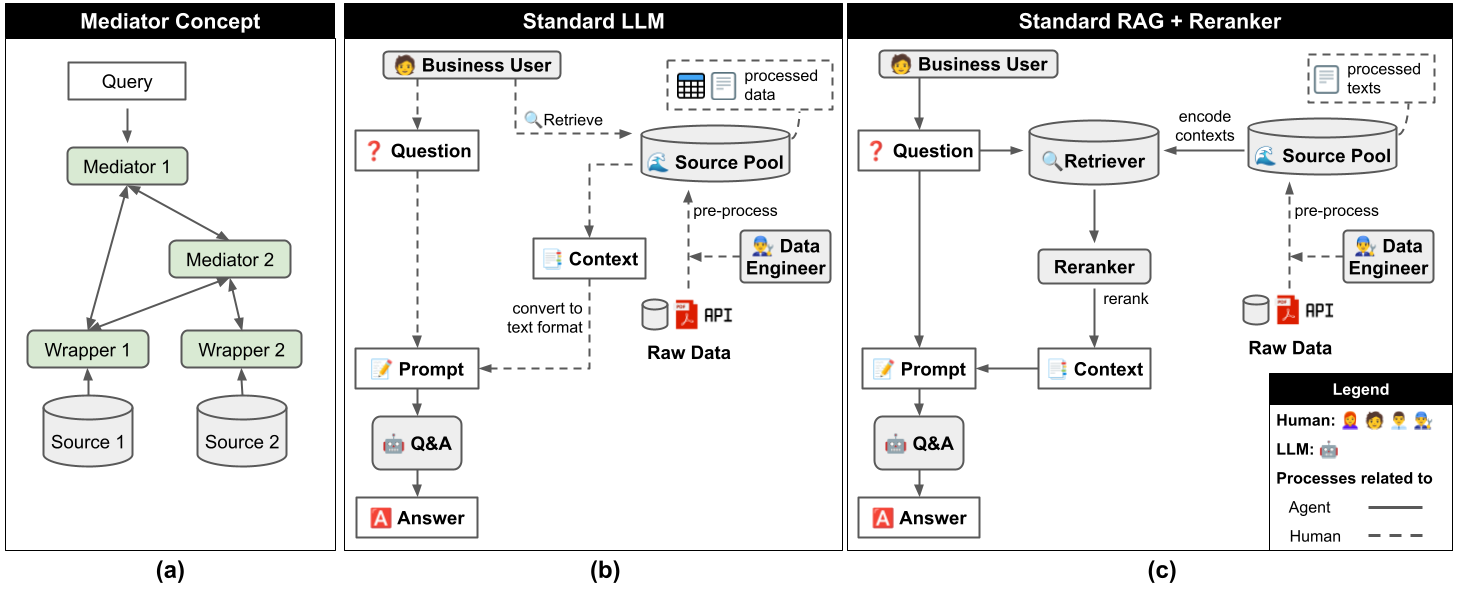
실험은 TAT-QA를 바탕으로 multi-source QA 환경을 만들어 진행했다. 원래의 표와 문단을 Source Object로 만들고, 학습 데이터에서 Extraction Guide를 구성했다. 평가의 초점은 최종 답변만이 아니라, 올바른 소스를 찾고 올바른 retrieval action을 만들었는지에 있었다.
Source Object 수가 30개, 90개, 270개로 늘어날수록 모든 방법의 검색은 어려워졌다. 그 안에서 AU-RAG는 RAG + reranker보다 recall은 낮을 수 있지만 precision은 더 높게 유지했다. 즉 넓게 많이 가져오기보다, 더 맞을 가능성이 높은 소스를 선택적으로 고르는 방향이었다.
Source Object가 270개인 조건에서 retrieval precision은 RAG + reranker가 24.24%, AU-RAG가 30.28%였다. F1은 거의 비슷했지만, AU-RAG는 더 적은 false positive를 만드는 쪽에 강점이 있었다.
Extraction Guide를 30개에서 90개, 270개로 늘리면 AU-RAG의 retrieval F1은 31.51%, 31.83%, 33.06%로 증가했다. 예시가 많아질수록 에이전트가 어떤 소스를 고르고 어떻게 뽑아야 하는지 더 잘 배운 것이다.
반대로 최종 답변 ROUGE-L은 항상 AU-RAG가 더 높지는 않았다. AU-RAG는 필요한 부분만 잘라 쓰는 방식이라 답변이 짧아지는 경향이 있었고, baseline은 더 많은 context를 넣어 긴 답변을 만들었다. 그래서 이 연구의 핵심 결과는 “답변 길이”보다 “소스 선택과 추출 절차”에 있다.
The evaluation used TAT-QA to create a multi-source QA setting. Tables and paragraphs were converted into Source Objects, and training examples were used to construct Extraction Guides. The evaluation focused not only on final answers but also on source selection and retrieval actions.
As the number of Source Objects increased from 30 to 90 and 270, retrieval became harder for all methods. AU-RAG showed lower recall than RAG + reranker in some settings, but it maintained higher retrieval precision. It behaved more selectively instead of retrieving broadly.
With 270 Source Objects, retrieval precision was 24.24% for RAG + reranker and 30.28% for AU-RAG. F1 was similar, but AU-RAG produced fewer false-positive sources.
Increasing Extraction Guides from 30 to 90 and 270 improved AU-RAG retrieval F1 from 31.51% to 31.83% and 33.06%. More demonstrations helped the agent learn which sources to select and which retrieval actions to apply.
Final-answer ROUGE-L was not always higher for AU-RAG. Because AU-RAG extracts narrower contexts, its answers tend to be shorter, while the baseline often supplies more context and produces longer answers. The core result is therefore about source selection and extraction procedure rather than answer length alone.
- Source Object 270개 조건에서 AU-RAG retrieval precision 30.28%, RAG + reranker 24.24%
- AU-RAG는 recall보다 precision을 중시하는 선택적 검색에 강점
- Extraction Guide가 많아질수록 retrieval F1이 31.51% → 31.83% → 33.06%로 증가
- With 270 Source Objects, AU-RAG retrieval precision reached 30.28% vs 24.24% for RAG + reranker
- AU-RAG favored selective, high-precision retrieval over broad recall
- Retrieval F1 improved from 31.51% to 31.83% to 33.06% as Extraction Guides increased
04 · 시사점 Reflection
검색 대상이 아니라 검색 절차를 학습하기
Learning Retrieval Procedures
이 연구의 시사점은 RAG를 단순히 문서 조각을 찾는 문제로만 보면 부족하다는 점이다. 기업 환경에서는 어떤 소스를 찾을지뿐 아니라, 그 소스 안에서 무엇을 어떻게 꺼낼지도 중요하다.
AU-RAG의 핵심은 예시를 절차 지식으로 쓰는 것이다. 분석가가 남긴 질문, 선택한 소스, 추출 행동은 다음 질문을 푸는 방법을 보여준다. 이는 단순히 관련 문장을 prompt에 넣는 것보다 한 단계 더 작업 지향적이다.
동시에 precision과 recall의 선택이 중요하다는 점도 보였다. AU-RAG는 더 정확한 소스를 고르는 경향이 있지만, 일부 관련 소스를 놓칠 수 있다. 업무 환경에 따라 “조금 적게 가져오더라도 정확한 것”이 중요한지, “많이 가져와 놓치지 않는 것”이 중요한지 다르게 판단해야 한다.
한계도 있었다. 실험은 TAT-QA 기반의 static source에 집중했고, 실제 API나 데이터베이스가 계속 바뀌는 운영 환경까지 충분히 검증한 것은 아니다. Source Object와 Extraction Guide를 누가 만들고, 어떻게 업데이트하고, 오래된 guide를 어떻게 관리할지도 남은 문제다.
지금의 관점에서 보면 AU-RAG는 MCP 이전에 데이터 소스 접근과 절차 예시를 어떻게 구조화할 수 있는지 탐색한 연구라고 볼 수 있다. 이후에는 기업 지식 검색, 금융 리포트 분석, 내부 API 기반 질의응답처럼 heterogeneous source를 다루는 agentic retrieval로 확장할 수 있다.
The main lesson is that RAG is not only about finding relevant chunks. In enterprise settings, it also matters which source should be selected and what should be extracted from that source.
AU-RAG turns examples into procedural knowledge. A question, selected sources, and retrieval actions from an analyst demonstrate how future questions should be solved. This is more task-oriented than simply inserting relevant text into a prompt.
It also shows that precision and recall need to be chosen deliberately. AU-RAG tends to select more accurate sources, but it can miss some relevant ones. Different enterprise workflows may prefer precise retrieval or broad recall depending on risk.
The limitation is that the evaluation focused on static sources derived from TAT-QA. It did not fully test live APIs, changing databases, or production-scale source governance. Maintaining Source Objects and Extraction Guides is also an open operational problem.
From today’s perspective, AU-RAG can be read as an early attempt to structure data-source access and procedural examples before the MCP-server framing became common. It extends naturally to enterprise knowledge search, financial report analysis, and internal API-based question answering.