2026 · Under review
NL2SQL+
자연어 질문에서 예측이 필요한 경우를 탐지해 데이터베이스 안에서 Embedded ML Function을 수행하는 SQL로 바꾸는 연구입니다.
An extended framework for SQL generation with on-demand embedded machine learning functions.
기존 NL2SQL은 조회와 집계에 강했습니다. NL2SQL+는 여기서 더 나아가 예측 모델이 필요한 질문을 감지하고, 알맞은 모델과 SQL 템플릿을 골라 실행 가능한 쿼리로 만듭니다.
NL2SQL+ extends text-to-SQL from retrieval and aggregation queries to predictive analytics by routing ML-intent questions into model selection and platform-specific ML SQL generation.
01 · 배경 Background
예측 질문까지 다루는 NL2SQL
Predictive NL2SQL
NL2SQL은 사람이 자연어로 물어본 질문을 SQL로 바꾸는 기술이다. 예를 들어 "지난달 지역별 매출을 보여줘"라는 질문은 테이블을 조회하고, 필터링하고, 합산하는 SQL로 바꿀 수 있다. 기존 NL2SQL 연구는 주로 이런 조회와 집계 질문에 강했다.
하지만 실제 업무에서는 저장된 값을 꺼내 보는 것만으로 충분하지 않은 질문도 많다. "다음 달 수요는 얼마나 될까?", "어떤 고객이 이탈할 가능성이 높을까?", "이 조건을 바꾸면 결과가 어떻게 달라질까?" 같은 질문은 과거 데이터를 바탕으로 예측을 해야 한다.
요즘 데이터베이스는 이런 예측을 데이터베이스 밖으로 꺼내지 않고 SQL 안에서 수행할 수 있는 기능을 제공한다. BigQuery ML, Redshift ML, Azure Synapse, Postgres ML처럼 데이터베이스 안에서 모델을 학습하거나 예측을 실행하는 Embedded ML Function을 지원하는 시스템이 늘고 있다.
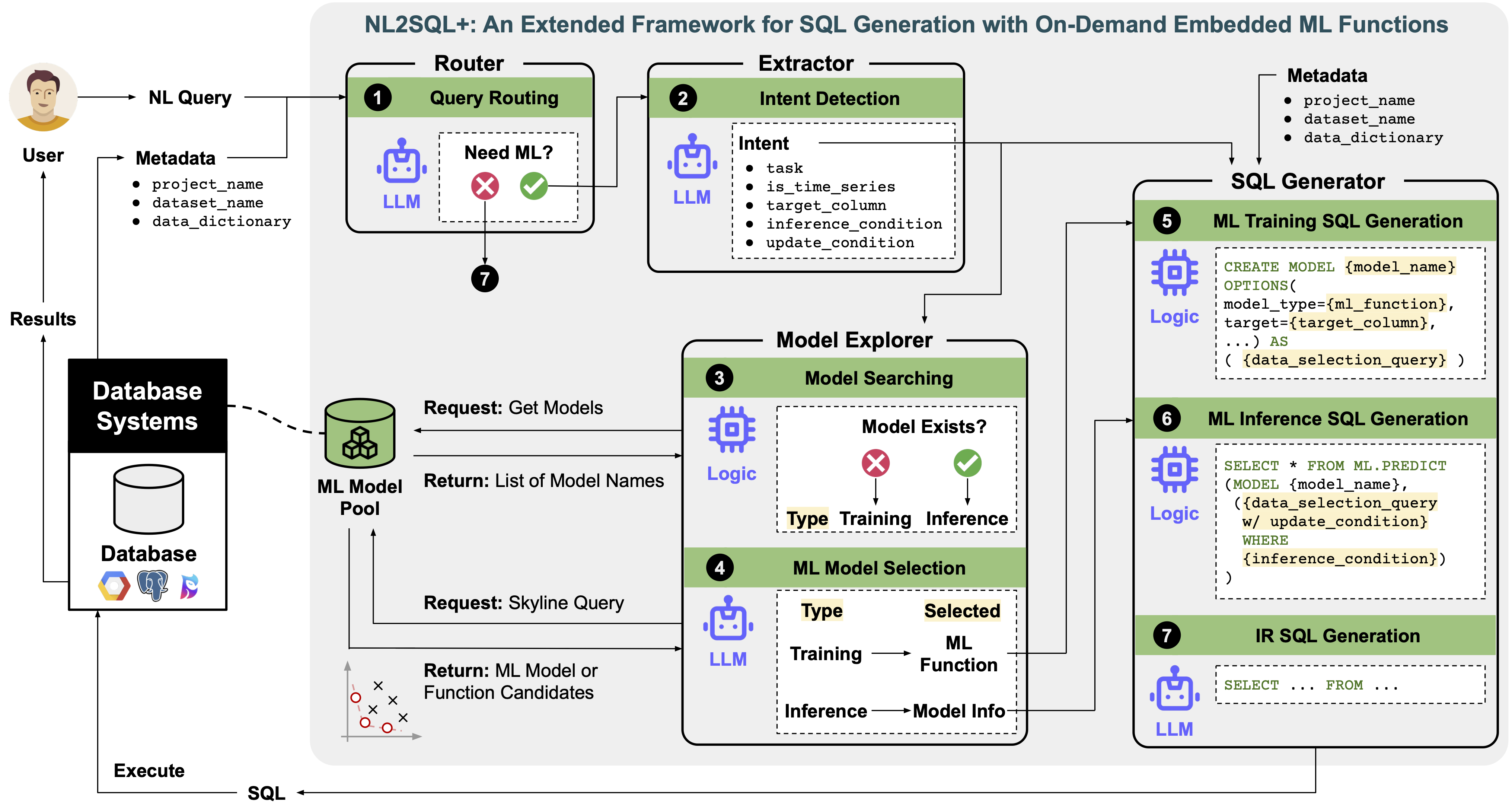
문제는 이 기능을 쓰려면 사용자가 데이터베이스 구조뿐 아니라 예측 대상, 조건, 모델 종류, 학습 SQL과 추론 SQL의 문법까지 알아야 한다는 점이다. NL2SQL+는 자연어 질문이 단순 조회인지 예측이 필요한 질문인지 먼저 구분하고, 예측이 필요하면 필요한 정보를 구조화해 Embedded ML Function을 수행하는 SQL로 바꾼다.
NL2SQL translates natural-language questions into SQL. A question such as "show last month's sales by region" can be handled by retrieval, filtering, joins, and aggregation. Most conventional NL2SQL research focuses on these retrieval-oriented queries.
Enterprise users also ask questions that require prediction rather than lookup: future demand, churn likelihood, anomaly detection, clustering, or counterfactual changes. These questions require predictive computation over historical data.
Modern databases increasingly expose embedded ML functions inside SQL. Systems such as BigQuery ML, Redshift ML, Azure Synapse, and Postgres ML allow users to train models and run inference directly in SQL.
The challenge is that using these functions still requires technical knowledge about schemas, predictive targets, model choices, and platform-specific training and inference syntax. NL2SQL+ first routes whether a question needs predictive ML, then extracts structured intent and turns it into SQL that invokes embedded ML functions.
02 · 방법 Method
네 단계 ML SQL 파이프라인
Four-Stage ML SQL Pipeline
시스템은 네 단계로 나뉜다. 먼저 질문이 일반 SQL인지 ML SQL인지 나눈다. ML 질문이면 예측 대상, 조건, 업데이트 방식 같은 정보를 뽑아낸다.
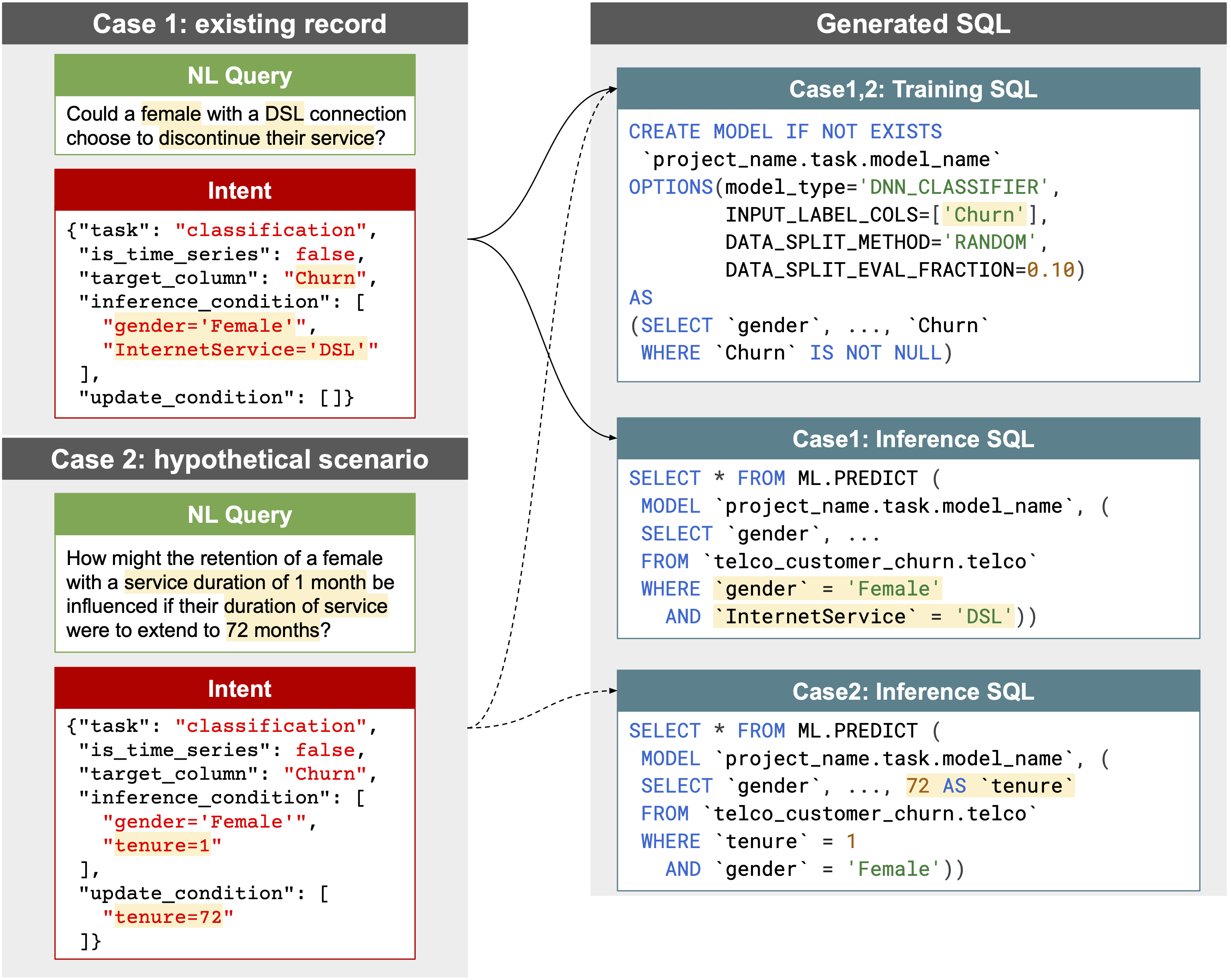
여기서 의도는 다섯 가지 정보로 정리된다. 어떤 예측 문제인지, 시간 흐름을 다루는지, 무엇을 예측할지, 어떤 record에 대해 예측할지, 그리고 가정 상황에서는 어떤 값을 바꿔 볼지를 구분한다. 예를 들어 "학력이 박사라면 소득이 얼마나 될까?" 같은 질문에서는 원래 조건과 바꿔 볼 값을 따로 잡아야 SQL을 정확히 만들 수 있다.
그다음 모델 후보에서 맞는 모델을 고르고, 플랫폼별 템플릿으로 학습 쿼리와 추론 쿼리를 만든다. 실험에는 라우팅 질문 1,200개, 학습 예제 7,231개, 테스트 예제 1,500개를 썼다.
The system has four stages: Query Routing, Intent Detection, ML Model Selection, and SQL Generation. It first classifies whether a question is ordinary SQL or ML SQL, then extracts structured intent such as task, target column, inference condition, and update condition.
The structured intent has five main fields: the predictive task, whether the question is time-series related, the target column, the inference condition, and the update condition. This distinction is important for hypothetical questions, where the system must separate which records to select from which input values to modify before generating SQL.
It then selects a model or ML function from metadata and instantiates platform-specific templates for training and inference SQL. The experiments used 1,200 routing queries, 7,231 training examples, and 1,500 test examples.
03 · 결과 Results
작은 모델로 안정적인 의도 추출
Fine-Tuned Intent Detection
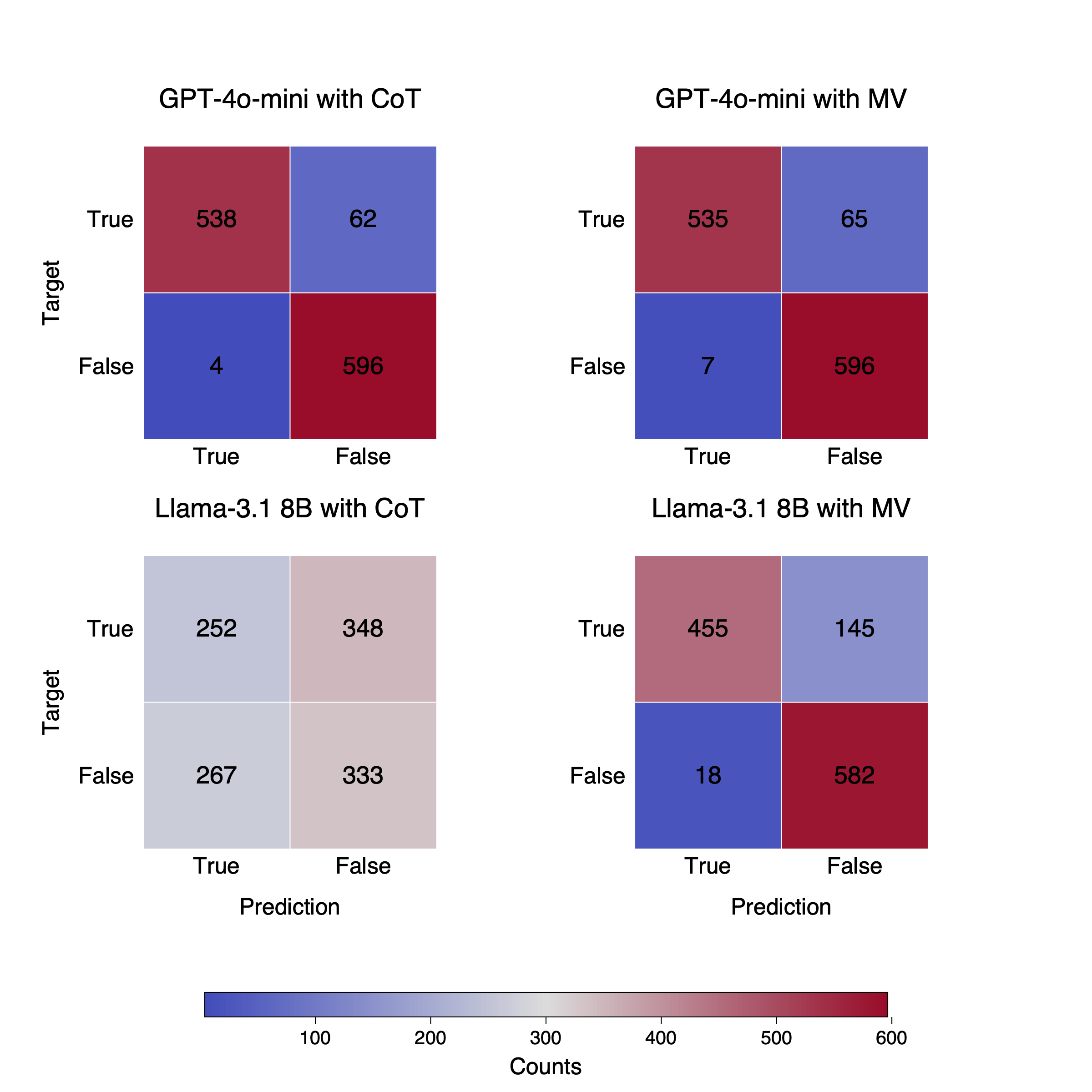
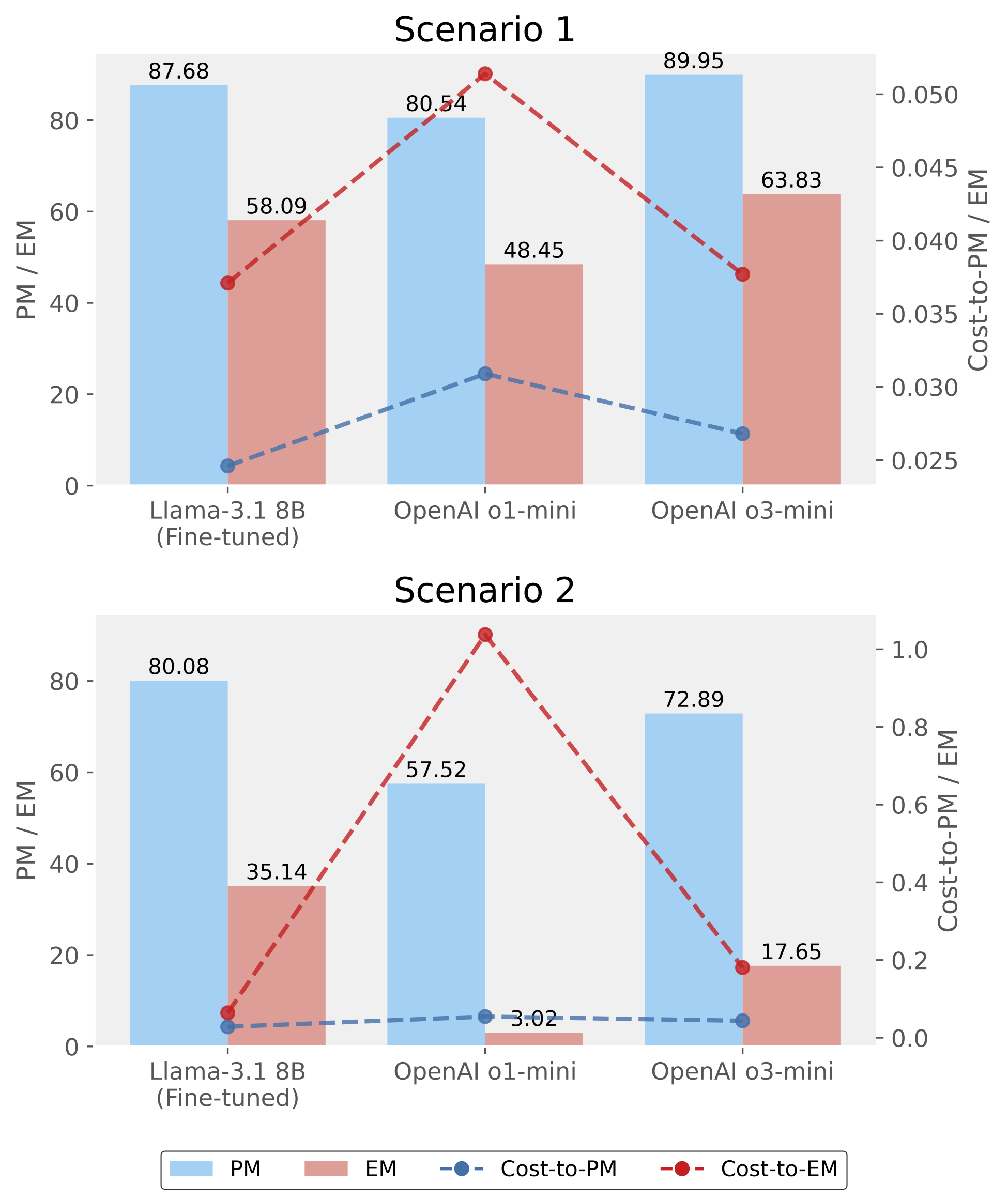
Query Router는 F1 94%를 기록했다. 의도 추출에서는 fine-tuned Llama-3.1 8B가 partial match 84.40, exact match 48.18을 보였다.
이는 직접 GPT-5-mini에 물었을 때의 exact match 12.27보다 훨씬 높다. o1-mini보다 67.08%, o3-mini보다 9.77% 높았고 토큰 사용량도 줄었다.
The Query Router achieved 94% F1. For Intent Detection, the fine-tuned Llama-3.1 8B reached 84.40 partial match and 48.18 exact match, far above the direct GPT-5-mini baseline exact match of 12.27.
Exact match was also 67.08% higher than OpenAI o1-mini and 9.77% higher than o3-mini, while token usage was substantially reduced. The result shows that complex ML SQL generation benefits from a structured pipeline rather than a single direct prompt.
- 질문 분류기 F1 94%
- 미세 조정한 Llama-3.1 8B: 부분 일치 84.40, 완전 일치 48.18
- GPT-5-mini에 바로 물었을 때 완전 일치 12.27
- o1-mini보다 67.08%, o3-mini보다 9.77% 높은 완전 일치
- Query Router reached 94% F1
- Fine-tuned Llama-3.1 8B: PM 84.40, EM 48.18
- Nearly 4x exact-match improvement over direct GPT-5-mini baseline EM 12.27
- Exact match improved by 67.08% over o1-mini and 9.77% over o3-mini
04 · 시사점 Reflection
분석 기능을 조합하는 자연어 인터페이스
Analytic Function Orchestration
이 연구를 하며 자연어 데이터 인터페이스가 단순 번역 문제를 넘어가고 있다는 점을 배웠다. 이제는 필요한 분석 기능을 고르고 조합하는 일이 중요해졌다.
다만 이 연구의 평가는 주로 의도 추출과 SQL 생성에 맞춰져 있다. 실제 데이터베이스에서 실행했을 때 성공하는지, 최종 답이 맞는지, 플랫폼마다 동작이 어떻게 달라지는지는 더 봐야 한다.
템플릿 기반 접근은 안정적이지만 복잡한 전처리나 여러 단계의 feature engineering까지 모두 다루기에는 부족하다. 실제 기업 사용자가 쓰는 질문, 실행 기반 평가, 개인정보가 어디까지 전달되는지에 대한 점검이 다음 과제다.
셀프서비스 분석, 데이터베이스 안의 ML 기능, 기업용 데이터 코파일럿처럼 사용자가 자연어로 모델 학습과 예측을 요청하는 환경에 맞다.
This work showed me that natural-language data interfaces are expanding from query translation into orchestration of analytic functions.
The current evaluation mainly focuses on intent extraction and SQL generation. Execution success, answer-level correctness, and platform-specific runtime behavior still need deeper evaluation.
Template-guided control is stable, but it may not cover unusual ML workflows, complex preprocessing, or multi-stage feature engineering. Future work should use human-authored enterprise queries, execution-based metrics, and privacy analysis of what data leaves the database boundary.
NL2SQL+ applies to self-service analytics, embedded ML in databases, and enterprise data copilots where users request model training and inference within SQL environments.