2025 · Published · SIGIR-AP 2025
QueryCapsule
검증된 SQL과 그 의도를 재사용 가능한 예시로 바꾸어 NL2SQL을 더 정확하게 만드는 연구입니다.
A data-centric NL2SQL framework that turns validated SQL workloads into reusable query examples.
검증된 SQL을 그대로 저장하는 대신, SQL의 의도 설명과 값이 추상화된 템플릿으로 묶었습니다. 비슷한 질문이 오면 이 캡슐을 예시로 제공해 더 정확한 SQL 생성을 돕습니다.
QueryCapsule packages a natural-language query context with a typed SQL template, then retrieves useful capsules so LLMs can generate structurally and semantically better SQL.
01 · 배경 Background
맥락을 품은 분석 쿼리
Context-Rich Analytic Queries
NL2SQL은 사용자가 자연어로 질문하면 데이터베이스가 실행할 수 있는 SQL로 바꿔 주는 기술이다. 예를 들어 “작년에 가장 많이 팔린 상품은?”이라는 질문을 사람이 SQL을 몰라도 데이터베이스에 물어볼 수 있게 해 준다.
문제는 실제 기업 데이터베이스가 단순하지 않다는 점이다. 테이블이 많고, 컬럼 이름이 업무 용어와 다르며, 같은 단어도 회사 안에서 특별한 의미를 가질 수 있다. LLM이 SQL 문법을 알아도 어떤 테이블과 컬럼을 연결해야 하는지, 어떤 조건을 걸어야 하는지는 쉽게 틀릴 수 있다.
이때 과거에 이미 검증된 질문-SQL 예시는 큰 도움이 된다. 하지만 예시를 그대로 저장해 두면 특정 값이나 특정 질문에 묶여 있어서, 새 질문에 어떻게 다시 써야 할지 알기 어렵다.
QueryCapsule은 검증된 SQL을 재사용 가능한 지식으로 바꾸려는 연구다. SQL이 무엇을 하려는지 설명하는 자연어 맥락과, 구체적인 값을 자리표시자로 바꾼 SQL 템플릿을 함께 저장해, 비슷한 질문이 왔을 때 LLM이 더 정확한 SQL 구조를 만들도록 돕는다.
NL2SQL translates a user’s natural-language question into executable SQL. It lets non-technical users ask a database questions such as “which product sold the most last year?” without writing SQL themselves.
The challenge is that enterprise databases are rarely simple. They have large schemas, company-specific terms, implicit business logic, and values that do not appear clearly in table or column names. Even when an LLM knows SQL syntax, it can still link the wrong schema elements or generate a structurally plausible but incorrect query.
Previously validated question-SQL examples can help, but raw examples are hard to reuse. Concrete values and one-off wording make it unclear how an old query should guide a new one.
QueryCapsule turns validated SQL into reusable knowledge. It stores a natural-language query context together with a SQL template whose concrete values are abstracted into typed placeholders, helping the LLM adapt prior query patterns to new questions.
02 · 방법 Method
다시 쓰기 쉬운 쿼리 캡슐
Reusable Query Capsules
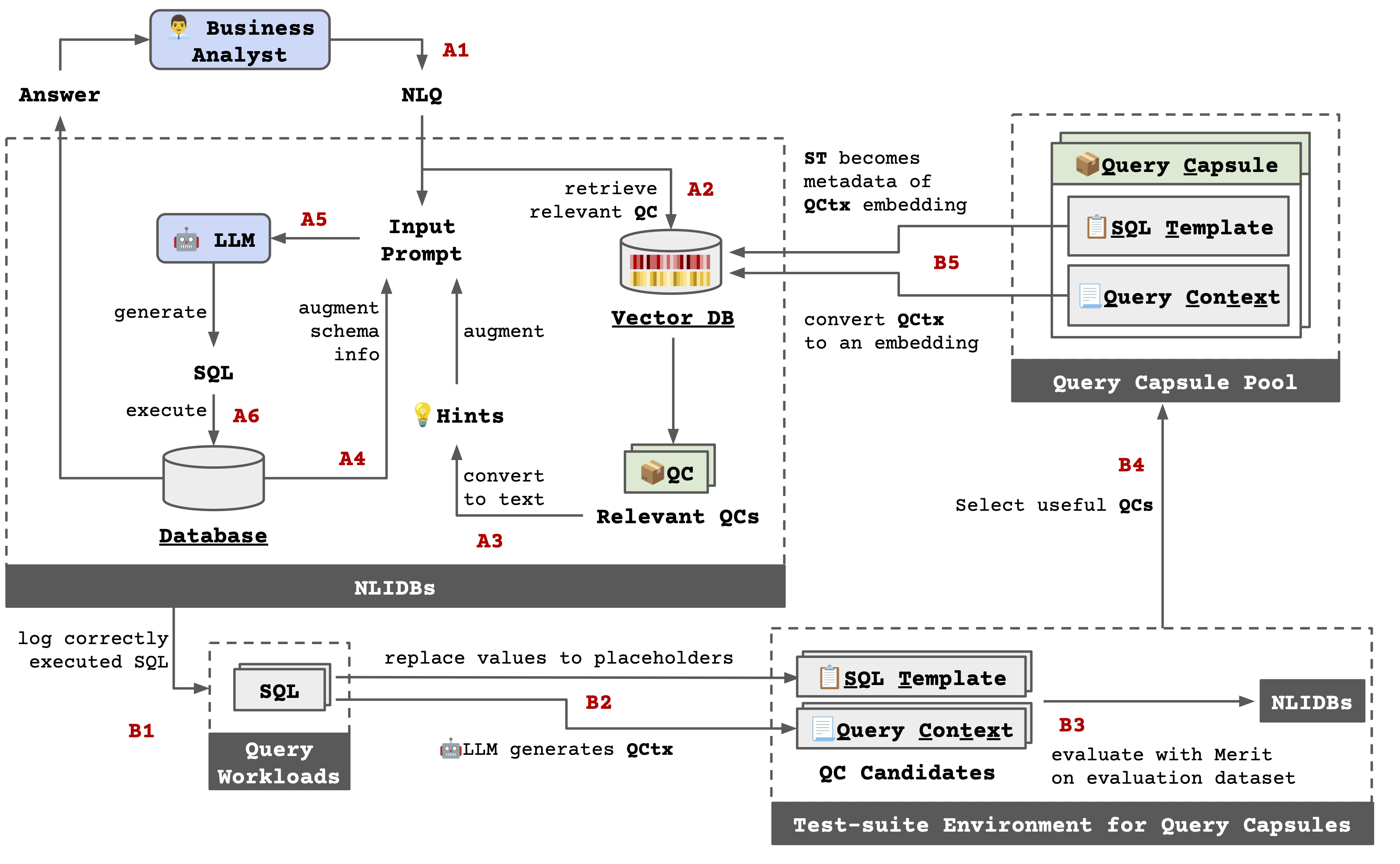
QueryCapsule의 기본 단위는 QC(Query Capsule)다. 하나의 QC는 두 부분으로 구성된다. 첫째는 SQL이 무엇을 하려는지 설명하는 query context이고, 둘째는 실제 SQL에서 구체적인 값을 타입이 있는 placeholder로 바꾼 SQL template이다.
예를 들어 특정 부품을 주문할 수 있는 공급자를 찾는 SQL이 있다면, query context는 그 SQL의 업무 목적을 설명하고, SQL template은 부품 ID나 수요량 같은 값만 바꿔 다른 질문에도 다시 쓸 수 있게 만든다.
새 질문이 들어오면 시스템은 질문과 가까운 QC를 검색한다. 검색된 QC의 설명과 SQL template은 LLM prompt에 예시로 들어가고, LLM은 전체 schema 정보와 함께 이 예시를 참고해 새 SQL을 만든다.
이 논문의 중요한 부분은 “좋은 QC를 어떻게 고를 것인가”다. 이를 위해 생성 SQL과 정답 SQL을 SQL component 단위로 비교했다. Structural Score는 SELECT, WHERE, JOIN, GROUP BY 같은 SQL 구조가 얼마나 비슷한지 보고, Semantic Score는 표현은 달라도 의미가 비슷한지를 본다.
두 점수는 F1 Score로 합친다. 수식으로 쓰면 F1 Score_c = 2 × Structural Score_c × Semantic Score_c / (Structural Score_c + Semantic Score_c + ε) 이다. 여기서 c는 SQL component이고, ε는 0으로 나누는 문제를 피하기 위한 작은 값이다.
Merit는 QC를 넣었을 때 F1 Score가 얼마나 좋아졌는지를 뜻한다. Merit = average_c(F1 Score with QCs)_c − average_c(F1 Score without QCs)_c 로 계산한다. 즉 자주 나온 예시가 아니라, 실제로 SQL 구조와 의미를 더 정답에 가깝게 만드는 QC를 고르려 했다.
The basic unit is a Query Capsule (QC). Each QC has two parts: a query context that explains the SQL intent in natural language, and a SQL template where concrete values are replaced with typed placeholders.
For example, if a SQL query finds suppliers for a given part and demand, the query context describes that business intent, while the SQL template keeps the reusable structure and abstracts away the specific part ID or demand value.
Given a new question, the system retrieves similar QCs. The retrieved query contexts and SQL templates are inserted into the LLM prompt together with schema information, giving the model concrete structural guidance for generating a new SQL query.
A key part of the paper is how to select useful QCs. The generated SQL and reference SQL are compared by SQL components. Structural Score measures whether components such as SELECT, WHERE, JOIN, and GROUP BY are structurally similar, while Semantic Score measures whether they are meaningfully similar even when written differently.
The two scores are combined as F1 Score. The formula is F1 Score_c = 2 × Structural Score_c × Semantic Score_c / (Structural Score_c + Semantic Score_c + ε), where c is an SQL component and ε avoids division by zero.
Merit measures how much the F1 Score improves when QCs are provided: Merit = average_c(F1 Score with QCs)_c − average_c(F1 Score without QCs)_c. The goal is therefore to select QCs that actually move generated SQL closer to the target in both structure and meaning.
03 · 결과 Results
재사용 가능한 분석 단위
Reusable Analytic Units
실험은 Spider와 BIRD benchmark에서 direct 방식과 pipeline 방식의 SQL 생성을 나누어 진행했다. 두 방식 모두 QC를 prompt에 넣었을 때 실행 정확도와 F1 Score가 대체로 좋아졌다.
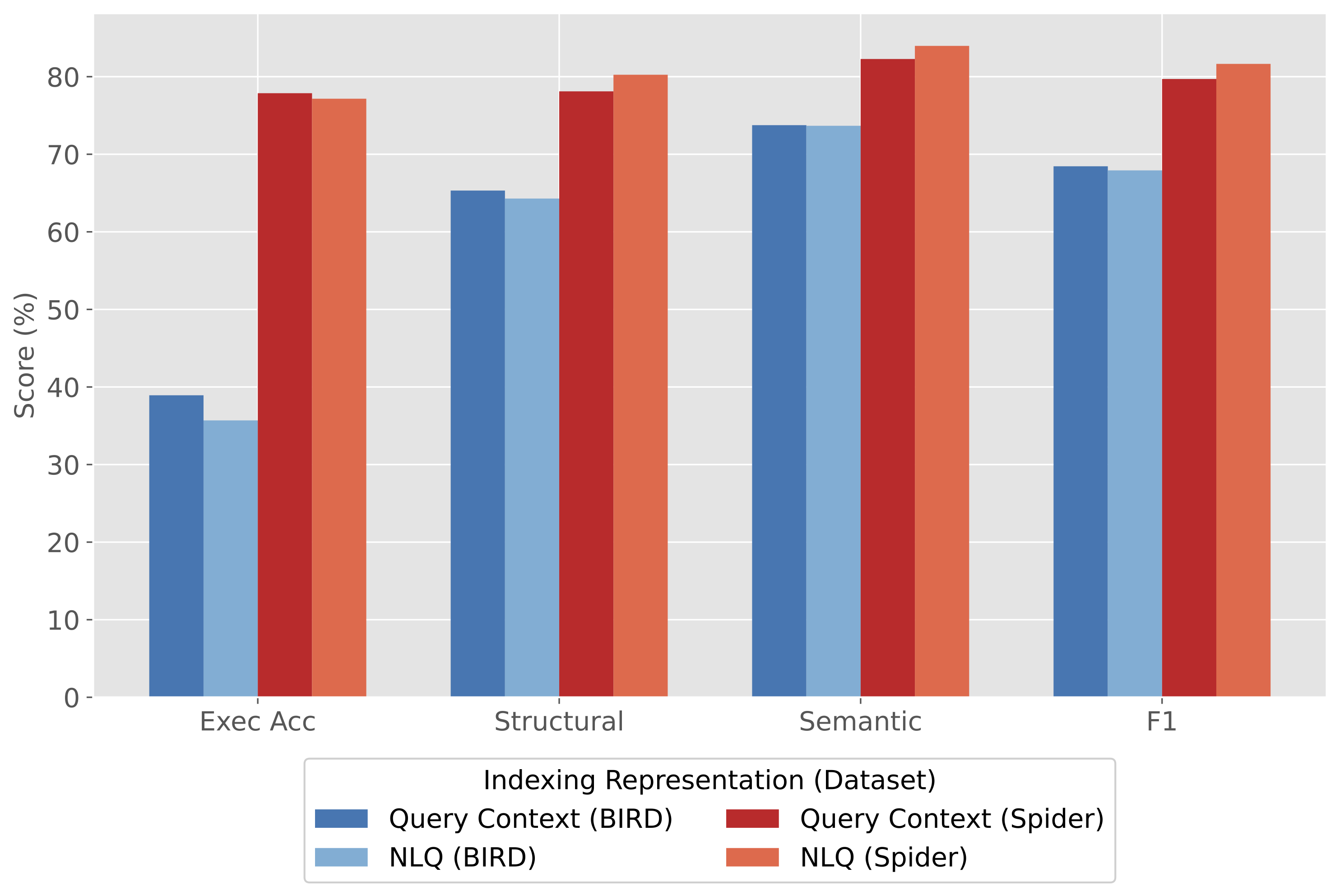
BIRD에서는 direct 방식 기준으로 execution accuracy가 36.80에서 38.93으로, F1 Score가 63.24에서 68.45로 올랐다. Spider에서도 direct 방식 기준 execution accuracy가 74.46에서 77.87로, F1 Score가 75.43에서 79.70으로 올랐다.
TPC-H case study에서는 더 실무적인 효과가 보였다. 단순히 정답 query description만 넣는 것보다, description과 SQL template을 함께 가진 QC를 retrieval해서 넣는 방식이 세 모델 모두에서 더 높은 실행 정확도를 보였다.
다만 QC가 항상 좋은 방향으로만 작동한 것은 아니다. 잘못 맞는 QC가 들어오면 불필요한 join이 추가되거나 너무 복잡한 SQL이 만들어질 수 있었다. 따라서 QueryCapsule의 핵심은 “예시를 넣는다”가 아니라 “도움이 되는 예시를 고른다”에 가깝다.
The experiments tested both direct and pipeline SQL generation on Spider and BIRD. In most settings, adding QCs improved execution accuracy and F1 Score.
On BIRD with direct generation, execution accuracy improved from 36.80 to 38.93, and F1 Score improved from 63.24 to 68.45. On Spider with direct generation, execution accuracy improved from 74.46 to 77.87, and F1 Score improved from 75.43 to 79.70.
The TPC-H case study showed a more practical effect. Retrieval of a QC containing both description and SQL template outperformed simply adding the target query description across all three tested models.
QCs did not always help. A poorly matched QC could introduce unnecessary joins or over-complicate the SQL. The central lesson is therefore not merely to add examples, but to select examples that are useful for the target query.
- Query context와 SQL template을 하나의 QC로 저장
- BIRD direct F1 Score 63.24 → 68.45, Spider direct F1 Score 75.43 → 79.70
- TPC-H case study에서 QC retrieval이 평균 2.63배 실행 정확도 향상
- Stored query context and SQL template as one Query Capsule
- BIRD direct F1 Score improved from 63.24 to 68.45; Spider direct F1 Score from 75.43 to 79.70
- QC retrieval improved TPC-H execution accuracy by 2.63x on average
04 · 시사점 Reflection
로그를 지식으로 바꾸기
Analytic History as Knowledge
이 연구의 시사점은 과거 SQL 로그가 단순한 기록이 아니라 다음 질문을 푸는 예시 지식이 될 수 있다는 점이다. 다만 그대로 넣는 것이 아니라, 의도와 구조를 분리해 재사용 가능한 형태로 바꿔야 한다.
NL2SQL에서 어려운 부분은 SQL 문법만이 아니다. 질문 이해, schema linking, database content grounding, join 구조 선택이 함께 맞아야 한다. QC는 이 중에서 특히 schema와 join 구조를 잡는 데 도움이 되는 구체적인 힌트가 된다.
한계는 예시 선택에 있다. 잘못 맞는 QC는 오히려 불필요한 join을 만들고 SQL을 복잡하게 할 수 있다. 또 쿼리 로그가 부족한 조직에서는 좋은 QC pool을 만들기 어렵고, 자주 쓰는 질문만 과하게 대표될 수 있다.
앞으로는 업무 복잡도별로 균형 잡힌 QC를 만들고, 비즈니스 분석가가 검수한 예시를 어떻게 운영할지 보는 것이 중요하다. QueryCapsule은 기업 NL2SQL, 데이터 분석 코파일럿, 반복 보고서 생성에서 “검증된 SQL 경험을 재사용하는 메모리”로 확장될 수 있다.
The main lesson is that past SQL workloads can become example knowledge for future questions. They should not be inserted raw; their intent and structure need to be separated into a reusable form.
NL2SQL is not only about SQL syntax. Question understanding, schema linking, database-content grounding, and join-structure selection all have to work together. QCs give concrete guidance especially for schema and join structure.
The limitation is example selection. A poorly matched QC can introduce unnecessary joins and make the SQL too complex. Cold start is another issue: organizations with sparse logs may struggle to build a useful QC pool, and frequent questions can dominate the examples.
Future work should build balanced QCs across query complexity and include business-analyst curation. QueryCapsule can be extended as a memory structure for enterprise NL2SQL, data copilots, and recurring report generation.