2023 · Published · PAKDD 2023
PolyFIT
블랙박스 모델의 특징 상호작용을 이용해 사람이 읽을 수 있는 다항식 모델을 만드는 연구입니다.
An interpretable machine learning method that builds polynomial surrogate models from feature interaction trees.
블랙박스 모델에서 특징 간 상호작용을 추출하고, 이를 Feature Interaction Tree로 정리해 해석 가능한 다항식 모델을 만듭니다.
PolyFIT extracts global feature interactions from a black-box model, builds a feature interaction tree, and constructs polynomial models that narrow the gap between performance and interpretability.
01 · 배경 Background
해석 가능한 추세선
Interpretable Trend Fitting
데이터 분석에서는 점들이 어떤 방향으로 움직이는지 보기 위해 추세선을 자주 그린다. 직선 하나로 설명되는 경우도 있지만, 실제 데이터는 휘어지거나 특정 구간에서만 크게 변하는 경우가 많다.
복잡한 모델은 이런 패턴을 잘 맞출 수 있지만, 왜 그런 예측을 했는지 사람이 이해하기 어렵다. 반대로 단순한 선형 모델은 이해하기 쉽지만, 데이터 안의 복잡한 관계를 놓칠 수 있다.
설명가능 AI에서는 이 둘 사이의 균형이 중요하다. 성능이 좋은 모델을 쓰고 싶지만, 의사결정에 쓰려면 사용자가 모델의 판단 근거를 어느 정도 이해할 수 있어야 한다. 특히 금융, 채용, 복지처럼 영향이 큰 결정에서는 설명이 더 중요해진다.
PolyFIT은 블랙박스 모델이 발견한 특징 간 상호작용을 바탕으로, 사람이 읽을 수 있는 다항식 모델을 만드는 연구다. 단순히 곡선을 그려 주는 것이 아니라, 어떤 상호작용 항이 추가되며 모델이 만들어지는지 보여 주고, 성능과 해석 가능성 사이의 관계를 실험으로 확인하려 했다.
Trend lines are common tools for seeing how data moves. Some patterns can be explained by a straight line, but real data often bends, changes only in certain regions, or depends on interactions between features.
Complex black-box models can capture these patterns, but their internal logic is hard for humans to inspect. Simple linear models are easier to understand, but they may miss important relationships in the data.
Explainable AI has to balance these two needs. High performance is useful, but real decision-making also requires explanations that users can understand, especially in high-stakes domains such as finance, hiring, and public services.
PolyFIT builds human-readable polynomial models from feature interactions discovered by black-box models. The motivation is not only to draw fitted curves, but to expose how interaction terms are added and to empirically study the relationship between model performance and interpretability.
02 · 방법 Method
직접 비교하는 다항식 모델
Interactive Polynomial Modeling
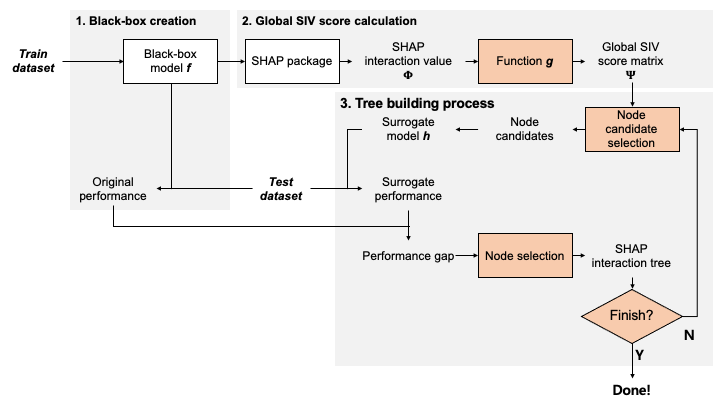
PolyFIT은 먼저 XGBoost 같은 블랙박스 모델을 학습시킨다. 이 모델은 복잡한 패턴을 잘 잡기 때문에, 데이터 안에서 어떤 특징들이 함께 작동하는지 찾는 출발점이 된다.
다음으로 SHAP interaction value를 이용해 특징 간 상호작용 점수를 계산한다. 단일 특징이 얼마나 중요한지뿐 아니라, 두 특징이 함께 있을 때 예측에 어떤 영향을 주는지를 본다.
이 상호작용 점수를 바탕으로 Feature Interaction Tree를 만든다. 트리는 “어떤 특징 조합을 먼저 다항식 항으로 넣을지”를 정하는 안내 역할을 한다.
마지막으로 다항식 surrogate model을 반복적으로 만든다. 후보 상호작용 항을 하나씩 추가해 보면서, 블랙박스 모델과의 성능 차이가 가장 작아지는 조합을 고른다. 이렇게 해서 선형 모델보다 표현력이 높고, 블랙박스보다 읽기 쉬운 모델을 만들고자 했다.
PolyFIT first trains a black-box model such as XGBoost. Because this model captures complex patterns, it becomes the starting point for discovering which features interact with each other.
It then computes feature interaction scores using SHAP interaction values. This measures not only the importance of individual features, but also how pairs of features jointly affect predictions.
From these interaction scores, PolyFIT builds a Feature Interaction Tree. The tree guides which feature combinations should be added as polynomial terms.
Finally, PolyFIT iteratively constructs polynomial surrogate models. It adds candidate interaction terms and selects the combination that minimizes the performance gap from the black-box model, aiming for a model that is more expressive than a linear model and more interpretable than a black box.
03 · 결과 Results
모델 선택과 해석
Model Choice and Interpretation
실험은 Titanic, Adult, Boston Housing, California Housing 네 데이터셋에서 진행했다. 분류 문제는 accuracy가 높을수록 좋고, 회귀 문제는 MSE가 낮을수록 좋다.
PolyFIT은 단순 선형 모델보다 분류와 회귀 모두에서 더 좋은 성능을 보였다. 논문 요약 기준으로 선형 모델 대비 분류에서는 평균 약 5%, 회귀에서는 평균 약 56% 개선됐다.
모든 데이터셋에서 블랙박스를 이긴 것은 아니지만, Titanic과 California에서는 XGBoost보다도 좋은 결과가 나왔다. 이는 블랙박스의 상호작용 지식을 이용하면 해석 가능한 모델도 복잡한 패턴을 어느 정도 따라갈 수 있음을 보여준다.
사용자 실험에서는 설명가능성이 단순히 “모델이 단순할수록 좋다”로 정리되지 않았다. 선형 모델이 항상 가장 이해하기 쉬운 것은 아니었고, 데이터셋과 과제에 따라 사용자가 도움이 된다고 느끼는 설명 방식이 달라졌다.
The experiments used four datasets: Titanic, Adult, Boston Housing, and California Housing. Classification tasks use accuracy, where higher is better; regression tasks use MSE, where lower is better.
PolyFIT outperformed the simple linear model on both classification and regression. According to the paper summary, it improved over linear models by about 5% on average for classification and 56% on average for regression.
PolyFIT did not outperform the black-box model on every dataset, but it exceeded XGBoost on Titanic and California. This suggests that using interaction knowledge from a black-box model can help build interpretable models that still capture complex patterns.
The user study also showed that explainability is not simply “simpler is always better.” Linear models were not always the easiest or most helpful, and the perceived usefulness of explanations varied by dataset and task.
- SHAP interaction value로 특징 간 상호작용 추출
- Feature Interaction Tree를 이용해 다항식 항을 선택
- 선형 모델보다 높은 성능, 블랙박스보다 읽기 쉬운 surrogate 모델 지향
- Extracted feature interactions with SHAP interaction values
- Selected polynomial terms through a Feature Interaction Tree
- Aimed for surrogate models that outperform linear models while remaining interpretable
04 · 시사점 Reflection
인터페이스가 바꾸는 통계 판단
Interface-Driven Statistical Judgment
이 연구의 시사점은 해석 가능한 모델이 반드시 아주 단순한 모델이어야 하는 것은 아니라는 점이다. 선형 모델은 읽기 쉽지만, 중요한 상호작용을 놓치면 사용자가 실제 의사결정에 쓰기 어렵다.
블랙박스 모델에서 얻은 지식을 그대로 설명으로 내놓는 것도 위험하다. PolyFIT은 그 지식을 사람이 읽을 수 있는 다항식 구조로 옮겨 보려는 시도였다. 즉 블랙박스와 투명 모델 사이의 중간 지대를 탐색한 것이다.
설명가능성 평가도 단순하지 않았다. 사용자 실험 결과는 데이터셋, 과제 유형, 설명 방식에 따라 달라졌다. 따라서 “성능이 낮으면 설명이 쉽고, 성능이 높으면 설명이 어렵다”는 단순한 trade-off 곡선만으로는 부족하다.
한계는 좋은 다항식 모델을 어떻게 고를지 아직 완전히 정해지지 않았다는 점이다. 상호작용 항이 많아지면 성능은 좋아질 수 있지만, 식이 복잡해져 다시 읽기 어려워진다. 더 많은 실제 데이터와 다양한 사용자 과제에서 검증이 필요하다.
PolyFIT은 고위험 의사결정에서 바로 블랙박스를 쓰기 어려운 상황, 교육용 설명가능 AI 도구, 탐색적 모델링, BI의 예측형 분석처럼 성능과 해석을 함께 봐야 하는 곳에 적용할 수 있다.
The main lesson is that interpretable models do not have to be extremely simple. Linear models are easy to read, but if they miss important interactions, they may be less useful for decision-making.
Directly explaining a black-box model is also risky. PolyFIT explores a middle ground: taking knowledge from the black box and translating it into a polynomial structure that humans can inspect.
The user study also shows that explainability is not one-dimensional. Results varied by dataset, task type, and explanation method, so the simple “higher performance means lower explainability” curve is not enough.
The limitation is model selection. Adding more interaction terms can improve performance, but it can also make the polynomial harder to read. More real-world datasets and user tasks are needed to understand this balance.
PolyFIT applies to settings where black-box models are difficult to deploy directly: high-stakes decision support, educational XAI tools, exploratory modeling, and predictive BI features where performance and interpretation have to be considered together.