2026 · Under review
Trace2Map
에이전트 실행 기록을 다시 쓸 수 있는 절차 지도로 바꾸는 방법입니다.
Milestone-guided context management for tool-use agents.
긴 실행 기록을 그대로 다시 넣는 대신, 반복해서 쓸 수 있는 업무 지도로 압축했습니다. 에이전트는 필요한 지점만 찾아보며 다음 행동을 고릅니다.
Trace2Map converts raw execution traces into procedural maps so tool-use agents can navigate reusable process knowledge without carrying entire episodic histories.
원시 실행 기록을 살펴보고 재사용 가능한 절차 지식으로 추상화하는 데모입니다.
How raw execution traces can be inspected and abstracted into reusable process knowledge (SM).
01 · 배경 Background
과거 실행 기록에서 추출한 절차적 지식
Procedural Knowledge from Past Execution Traces
만약 서울에서 부산으로 차를 타고 가야 하는데, 지금 대전까지 와 있다면 어떻게 할 것인가? 먼저 현재 위치가 대전이라는 사실을 확인하고, 대전에서 부산까지의 지도를 보며 다음 길을 고를 것이다.
에이전트도 비슷한 문제가 있다. 과거 실행 기록을 메모리로 사용하려면 어떤 도구를 먼저 썼는지, 어떤 순서가 잘 맞았는지를 참고해야 하지만, 현재 상태에서 필요한 부분만 바로 꺼내기는 어렵다.
많은 연구[1-6]도 과거 실행을 요약하거나 규칙과 절차로 바꿔, 에이전트가 다음 실행에서 참고할 힌트로 사용한다.
Trace2Map은 같은 문제를 지도 관점에서 다시 본다. 실행 기록을 그대로 다시 읽히지 않고, 현재 작업에 맞는 길을 찾을 수 있는 절차 지도로 바꿨다.
Suppose you are driving from New York City to Boston, and you have already reached New Haven. What would you do next? You would first recognize your current location, then look at the map from New Haven to Boston and choose the next route.
Tool-use agents face a similar problem. To use past execution traces as memory, the agent needs to reuse which tools were called and which orders worked well, but it is hard to pull out only the part relevant to the current state.
Many related methods [1-6] also turn past executions into summaries, rules, or procedures that agents can use as hints for future runs.
Trace2Map reframes the same problem as navigation. Instead of replaying long traces, it compresses them into procedural maps so agents can find routes relevant to the current state.

02 · 방법 Method
마일스톤 중심의 실행 지도
Milestone-Guided Trace Graph
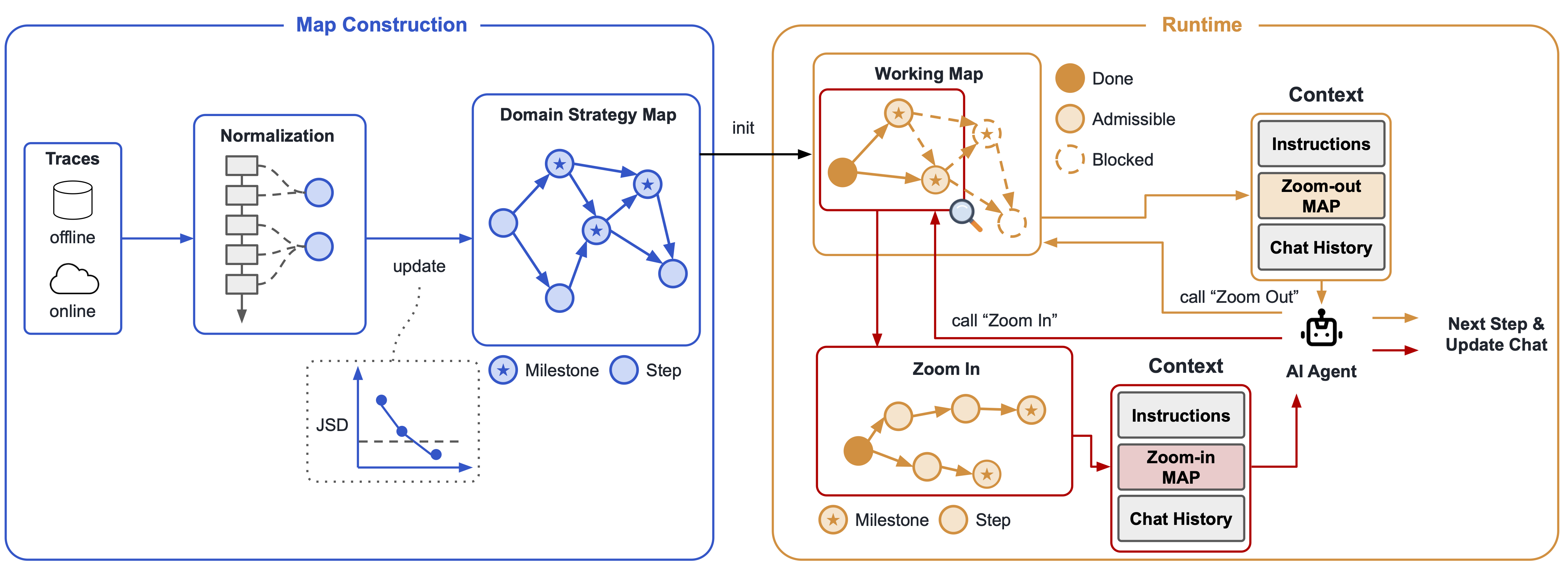
먼저 사용자와 에이전트 사이의 상호작용, 그리고 어시스턴트 에이전트가 수행한 도구 호출을 일정한 스텝으로 정규화했다. 그 스텝 사이의 전이를 모아 방향 가중 그래프를 만들고, fan-in/fan-out 구조와 PageRank, fan-flow, betweenness 같은 ranking signal로 마일스톤을 선택했다.
실행 중에는 Working Map이 현재 작업과 맞지 않는 갈래를 줄인다. 에이전트는 zoom-out으로 지금 상태에서 도달 가능한 마일스톤 흐름을 먼저 보고, 필요할 때 zoom-in으로 선택한 경로의 과거 실행 근거를 자세히 확인한다.
Trace2Map first normalizes user-agent interactions and tool calls made by the assistant agent into step nodes. It then builds a directed weighted graph from observed transitions and selects milestones using fan-in/fan-out structure and ranking signals such as PageRank, fan-flow, and betweenness.
During execution, the Working Map prunes branches that no longer match the current task. The agent uses zoom-out to inspect reachable milestone workflows from the current state, and zoom-in to retrieve detailed route evidence for a selected path when needed.
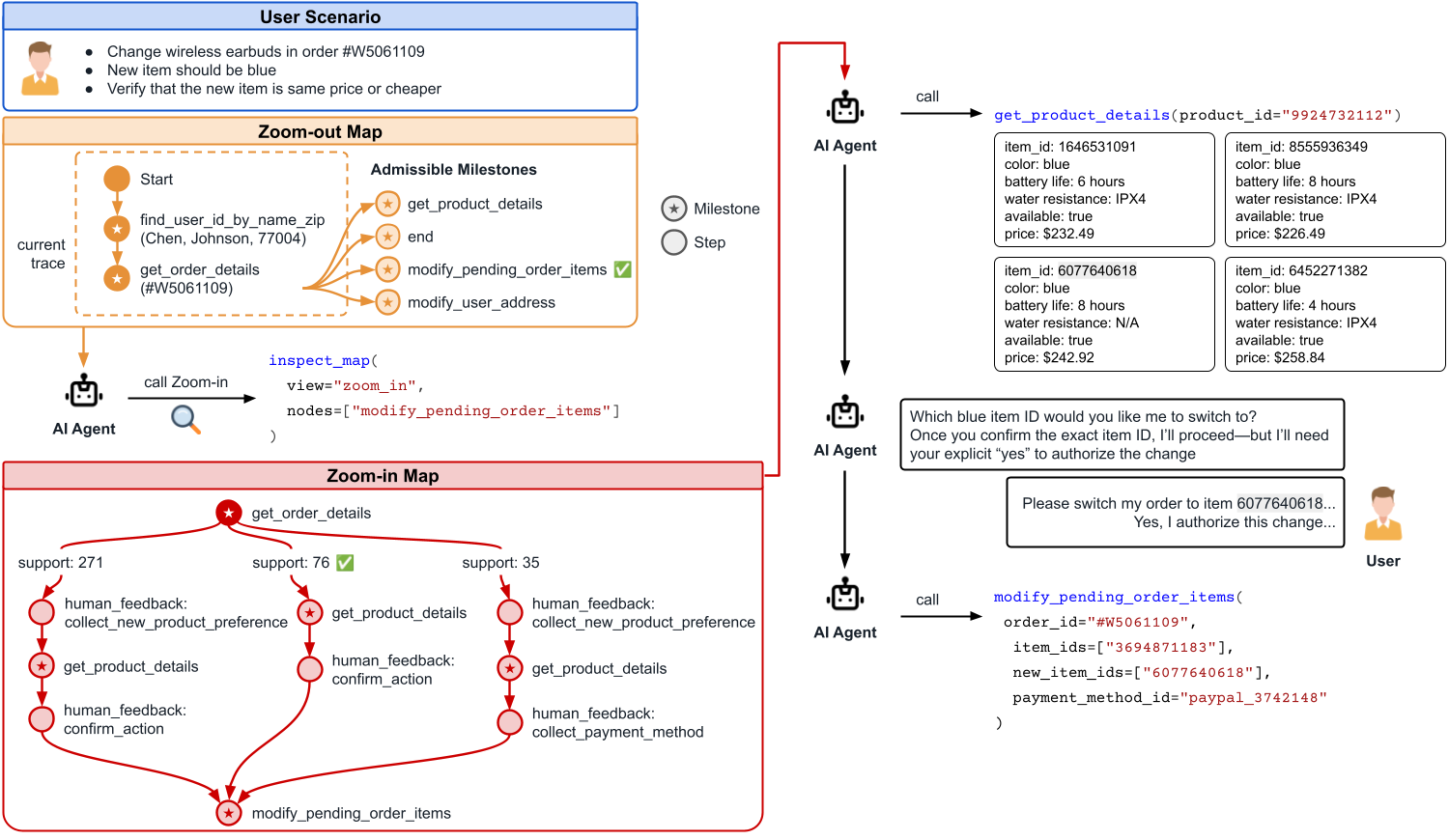
03 · 결과 Results
모델과 지도 선택에 따른 차이
Backend-Sensitive Map Guidance
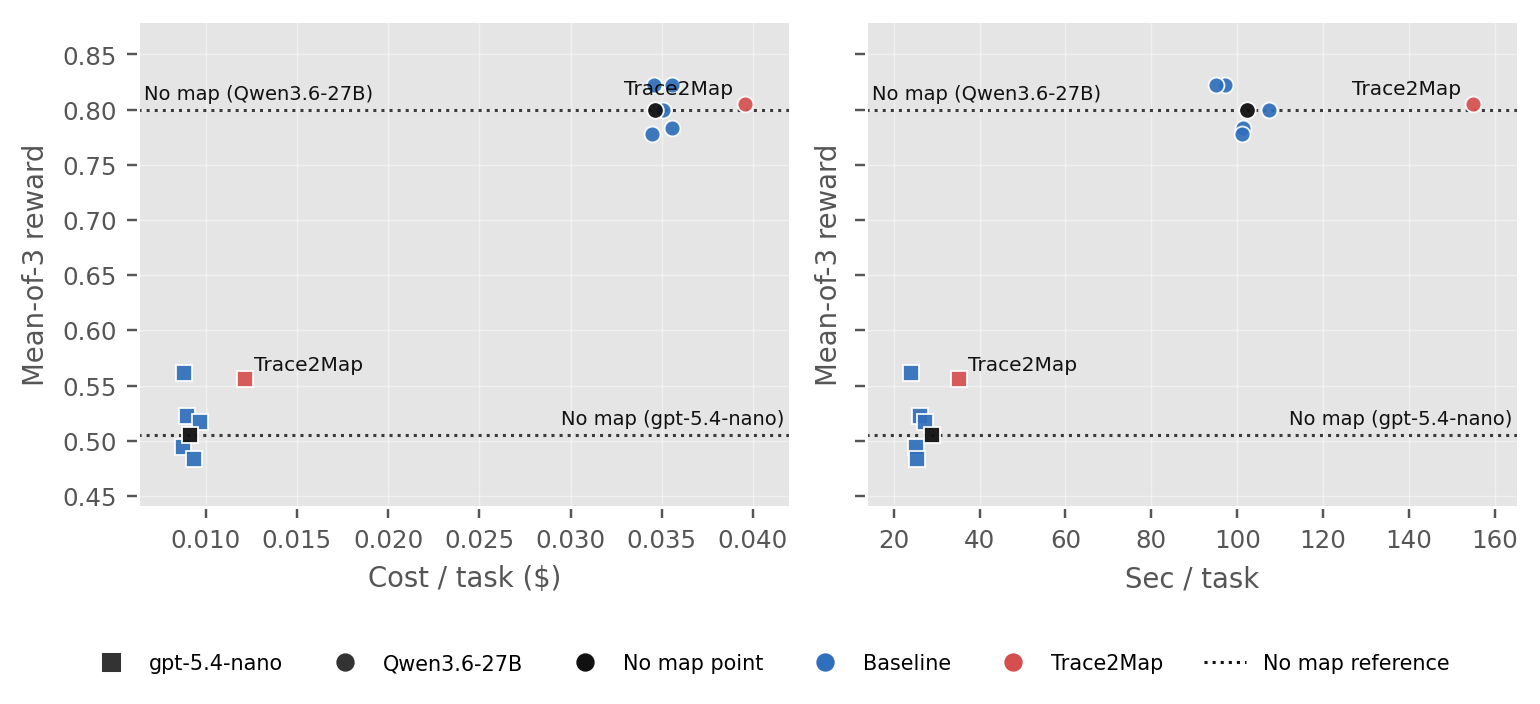
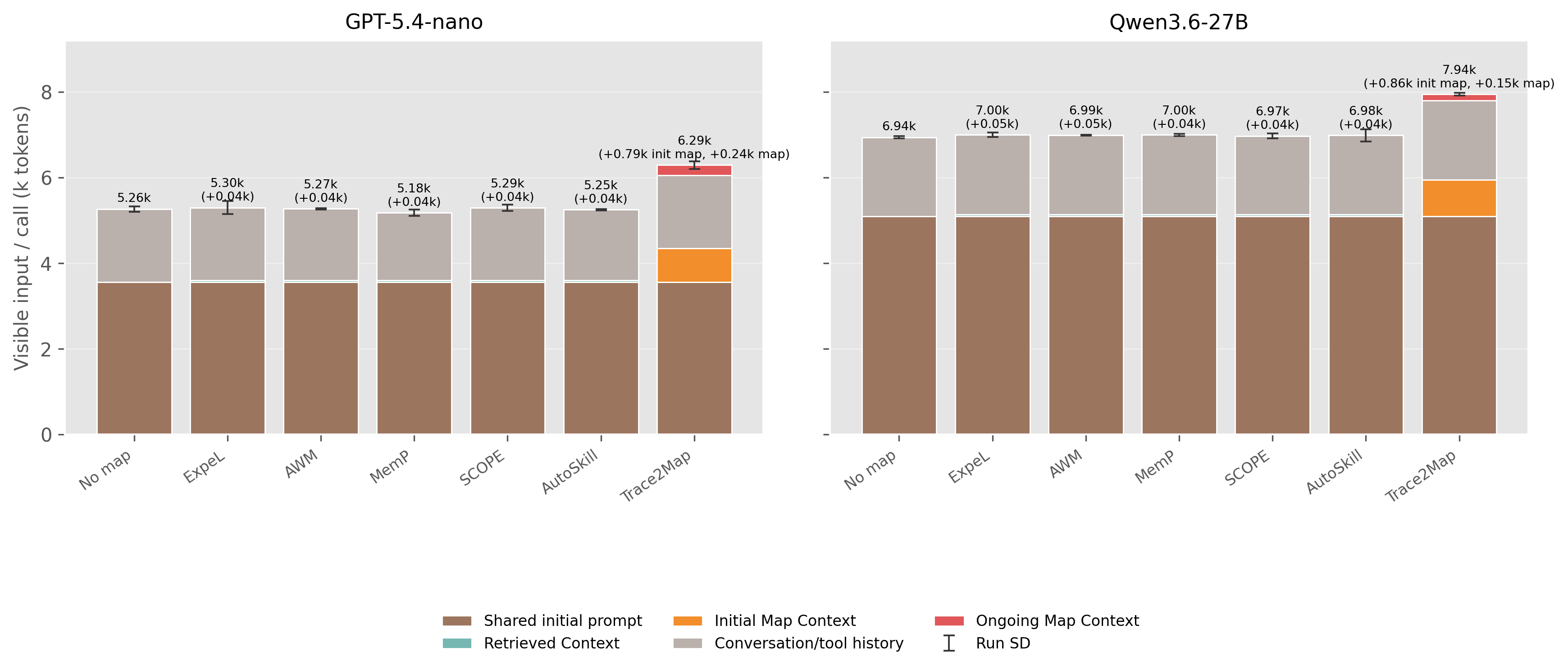
tau-bench[7]에서는 APIGen-MT[8] 실행 기록으로 지도를 만들고, airline과 retail 도메인에서 평가했다. 고정 PageRank 설정의 Trace2Map은 gpt-5.4-nano에서 지도 없음 0.506을 0.556으로 올렸고, Qwen3.6-27B에서는 0.800에서 0.806으로 거의 비슷했다. 그래서 이 결과는 Trace2Map이 항상 이긴다는 증거라기보다, 절차 지도가 언제 보상과 비용의 균형을 바꾸는지 보여주는 분석에 가깝다.
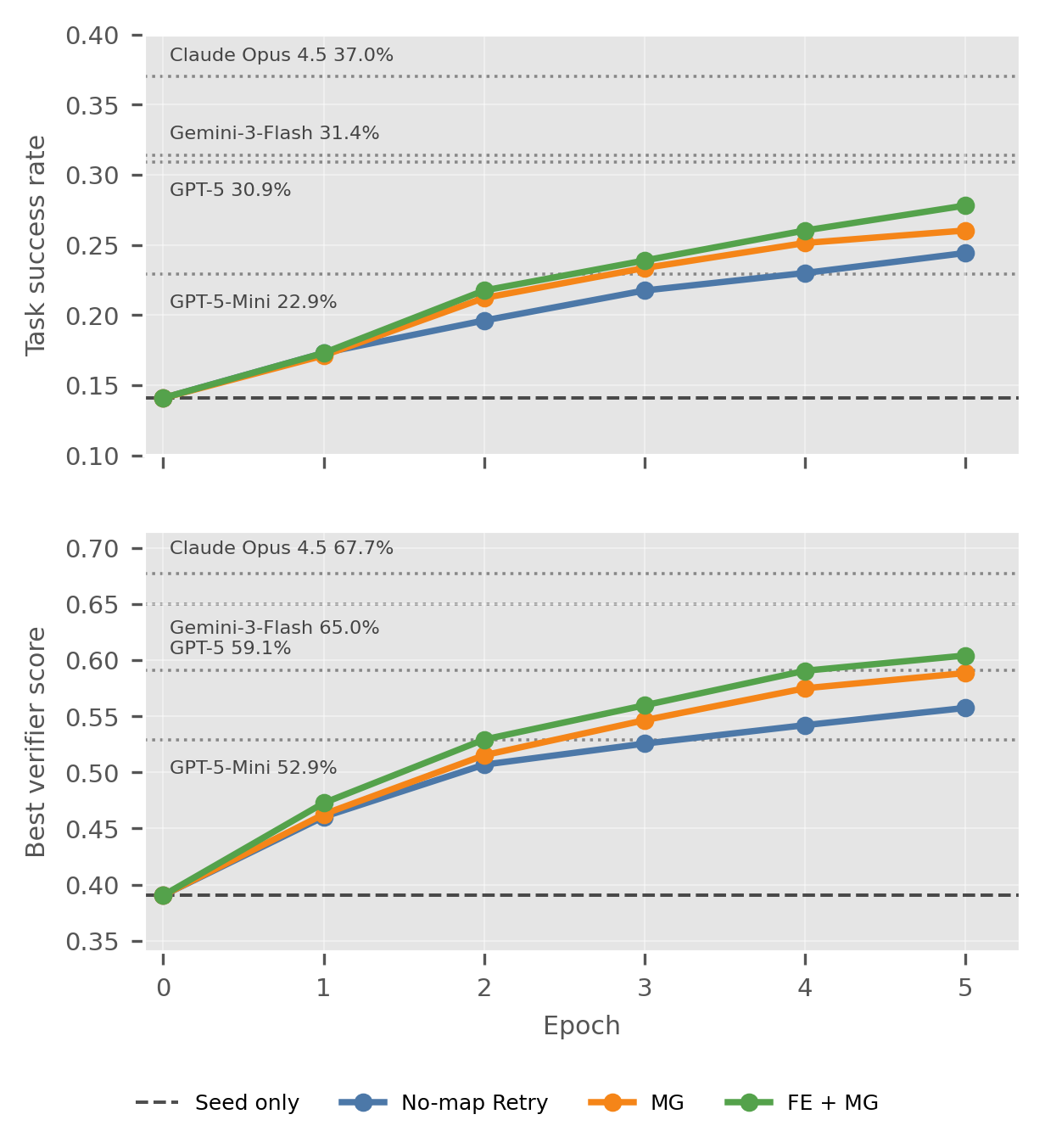
EnterpriseOps-Gym[9]에서는 지도가 한 번 만든 고정 메모리로 끝나지 않고, 새 실행이 쌓이면서 갱신되는 상황을 봤다. 성공 기록은 검증된 경로로 추가하고, 실패 기록은 어디서 갈라졌는지를 찾는 근거로 썼다. 실패 기록 추출과 지도 안내를 함께 썼을 때 해결 범위가 13.9% 늘었고, 이는 Trace2Map이 누적되는 절차 지식의 인터페이스가 될 수 있음을 보여준다.
비용 분석에서는 Trace2Map을 공짜 성능 향상으로 보지 않는 것이 중요했다. 지도는 현재 workflow와 도달 가능한 다음 workflow를 프롬프트에 넣기 때문에, 불확실성을 줄일 때는 도움이 되지만 토큰과 지연 시간도 늘어난다. gpt-5.4-nano에서는 작업당 비용이 $0.0092에서 $0.0121로, 시간은 29.0초에서 35.1초로 늘었다. Qwen3.6-27B에서는 $0.0346에서 $0.0396로, 102.2초에서 154.9초로 늘었다. 논문에서 보고한 비용은 실행 중 보이는 문맥과 생성 토큰 기준이며, 오프라인 지도 구축 비용은 포함하지 않았다.
In tau-bench [7], Trace2Map builds maps from APIGen-MT [8] traces and evaluates them in airline and retail tasks. With the fixed PageRank setting, it improved gpt-5.4-nano from 0.506 without maps to 0.556, while Qwen3.6-27B moved only from 0.800 to 0.806. The result is therefore best read as a reward-cost characterization, not as evidence that one map design always dominates.
In EnterpriseOps-Gym [9], the map is not just a fixed offline memory. It grows as new executions arrive. Successful traces add validated routes, while failed prefixes identify divergence points for later retries. Combining failure extraction with map guidance improved solved-task coverage by 13.9% relative, suggesting that Trace2Map can act as an interface for cumulative procedural knowledge.
The cost analysis treats Trace2Map as context management rather than a free accuracy gain. The map inserts current workflows and reachable future workflows into the prompt, which can reduce uncertainty but also adds tokens and latency. For gpt-5.4-nano, cost per task increased from $0.0092 to $0.0121 and runtime from 29.0s to 35.1s. For Qwen3.6-27B, cost increased from $0.0346 to $0.0396 and runtime from 102.2s to 154.9s. The reported token usage covers inference-time context and generated tokens, not offline map construction.
- gpt-5.4-nano: 지도 없음 0.506 → Trace2Map 0.556
- Qwen: 지도 없음 0.800 → PageRank 0.806, 중심성 기준 0.850
- EnterpriseOps-Gym 해결 범위 13.9% 증가
- 지도 문맥은 토큰과 지연 시간을 늘리므로 보상-비용 균형이 핵심
- gpt-5.4-nano: no-map 0.506 -> Trace2Map 0.556
- Qwen: no-map 0.800 -> fixed PageRank 0.806, betweenness 0.850
- EnterpriseOps-Gym solved-task coverage improved by 13.9% relative
- Map context adds tokens and latency, so the key issue is reward-cost balance
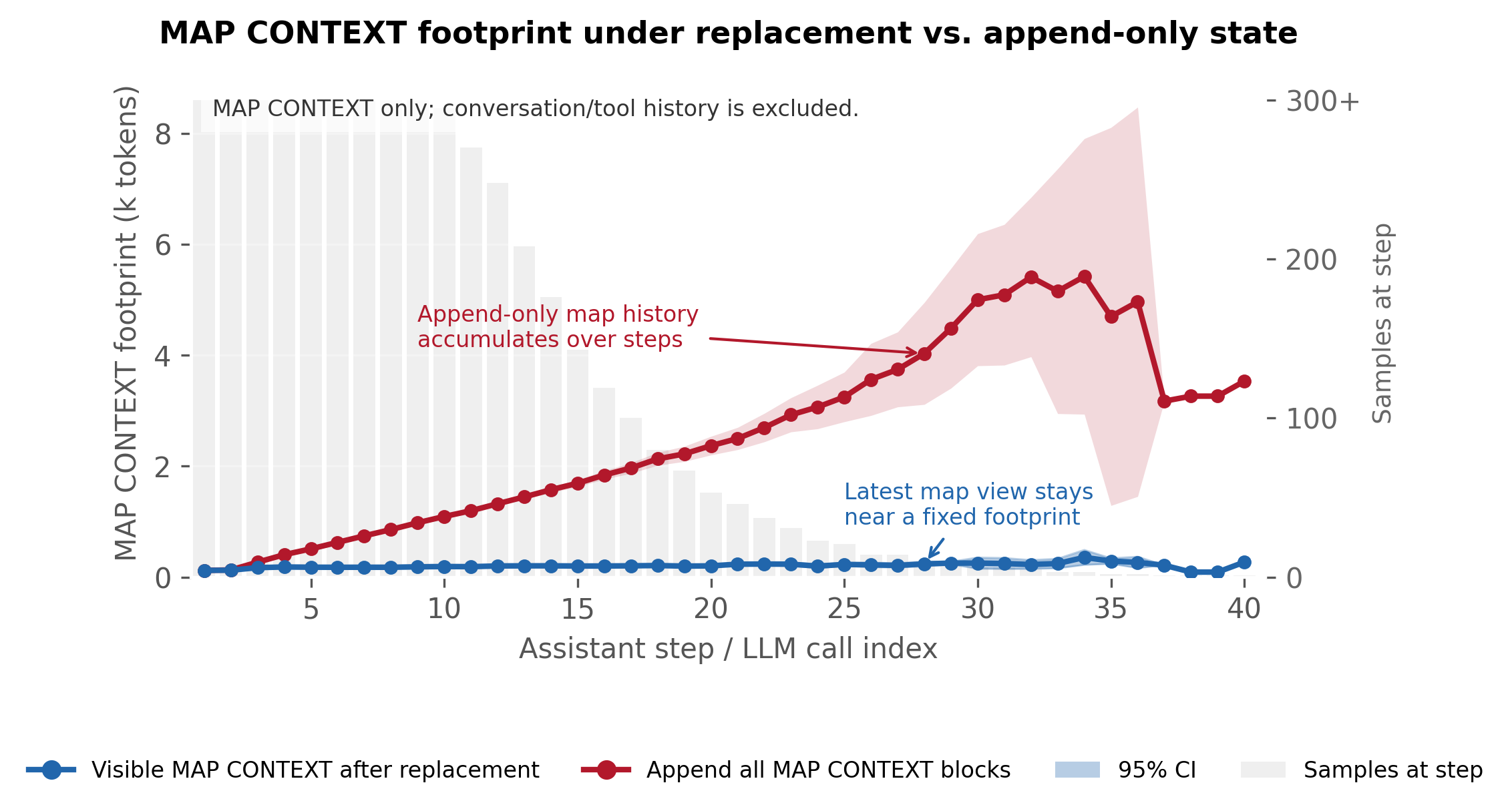
04 · 시사점 Reflection
실행 기록을 문맥으로 다루기
Trace Reuse as Context Management
첫 번째 시사점은 trace reuse가 단순한 memory 문제가 아니라 context management 문제에 가깝다는 점이다. 과거 trace를 저장하거나 요약하는 것만으로는 부족하다. 현재 agent state에서 어떤 부분을 보여줄지, 얼마나 자세히 보여줄지, 언제 보여줄지가 핵심이다.
두 번째로, raw trace에는 지식이 있지만 그대로는 action에 잘 연결되지 않는다. trace는 과거에 무슨 일이 있었는지를 보여주지만, agent가 필요한 것은 지금 이 상태에서 다음으로 가능한 절차가 무엇인지다. Trace2Map은 이 차이를 지도 형태로 메운다.
세 번째로, map은 turn 수를 줄이는 shortcut이라기보다 failure를 rescue하는 장치에 가깝다. Trace2Map은 더 짧게 푸는 방법이 아니라, No Map이 놓친 branch를 회수하거나 multi-step workflow를 끝까지 유지해서 추가 성공을 만든다.
네 번째로, 좋은 guidance는 답을 주는 것이 아니라 procedural coverage를 유지하게 돕는다. lookup, confirmation, state-changing action처럼 순서가 중요한 절차를 agent가 놓치지 않도록 잡아주는 것이 핵심이다.
마지막으로, 모델마다 map을 쓰는 방식이 다르다. GPT 계열은 zoom-in을 열어 local route evidence를 확인하는 경향이 있고, Qwen은 zoom-in 호출은 적지만 visible frontier를 보고 바로 tool을 호출하는 경향이 있다. 그래서 map 사용량을 inspect_map 호출 수만으로 판단하면 안 된다. Trace2Map의 주장은 항상 더 잘 푼다는 것이 아니라, 과거 trace를 navigable context로 바꾸어 특정 procedural uncertainty에서 failure를 줄인다는 데 있다.
The first lesson is that trace reuse is closer to a context-management problem than a simple memory problem. Storing or summarizing past traces is not enough. The key question is what to expose, how much detail to expose, and when to expose it given the agent's current state.
Second, raw traces contain knowledge, but they do not directly connect to action. A trace tells the agent what happened before, while the agent needs to know which procedures remain possible from the current state. Trace2Map bridges this gap by turning traces into a navigable map.
Third, the map is less a shortcut for reducing turns and more a mechanism for rescuing failures. Trace2Map does not simply make tasks shorter. It recovers branches that a no-map agent misses and helps preserve multi-step workflows until completion.
Fourth, good guidance is procedural coverage, not an answer shortcut. The map helps the agent preserve structures such as lookup, confirmation, and state-changing action, especially in complex tasks where a single missed branch can break the workflow.
Finally, models use maps differently. GPT-style backends tend to open zoom-in views to inspect local route evidence, while Qwen uses zoom-in less often and appears to act from the visible frontier. Therefore, map use should not be measured only by inspect_map calls. The stronger claim is not that Trace2Map always wins, but that it turns traces into navigable context and reduces specific failures under procedural uncertainty.
References
References
- Shinn, Noah, et al. “Reflexion: Language Agents with Verbal Reinforcement Learning.” Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 8634–8652.
- Zhao, Andrew, et al. “ExpeL: LLM Agents Are Experiential Learners.” Proceedings of the AAAI Conference on Artificial Intelligence, AAAI Press, 2024.
- Wang, Zora Zhiruo, Jiayuan Mao, Daniel Fried, and Graham Neubig. “Agent Workflow Memory.” arXiv, 2024.
- Fang, Runnan, et al. “MemP: Exploring Agent Procedural Memory.” arXiv, 2025.
- Pei, Zehua, et al. “SCOPE: Prompt Evolution for Enhancing Agent Effectiveness.” arXiv, 2025.
- Yang, Yutao, et al. “AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution.” arXiv, 2026.
- Yao, Shunyu, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. “τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.” arXiv, 2024.
- Prabhakar, Akshara, et al. “APIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay.” NeurIPS Datasets and Benchmarks Track, 2026.
- Malay, Shiva Krishna Reddy, et al. “EnterpriseOps-Gym: Environments and Evaluations for Stateful Agentic Planning and Tool Use in Enterprise Settings.” ICLR Workshop on Lifelong Agents: Learning, Aligning, Evolving, 2026.