Explaining Explanations: An Overview of Interpretability of Machine Learning¶
Paper Link: Explaining Explanations: An Overview of Interpretability of Machine Learning
1. Introduction¶
- 설명가능한(explainable) 모델은 해석(interpretable) 이 가능하지만 그 반대는 아니다.
- 설명가능한 시스템(explanatory system)는 머신러닝, 인간과 컴퓨터 상호 작용(Human-computer interaction), 크라우드 소싱, 교육분야, AI 윤리, 기술정책 등 다양한 분야에서 연구되고 적용되고 있다.
- 이 논문에서는 explainable AI 시스템의 전반적인 정의와 분류법을 소개한다.
Section 2: explanation, interpretability, explainability 에 대해서 정의한다.Section 3: 고전적인 AI 접근 방법(causal modeling, constraint reasoning, intelligent user interfaces, planning)을 복습하지만 설명 가능한 딥러닝 모델에 집중할 것이다.Section 4: explanation, interpretability, explainability 의 중요한 차이점에 대해서 이야기 한다.Section 5: 이 설명들을 통해 무엇이 설명되고 있는가(what is explained by these explanations)에 대한 새로운 분류법을 제시한다. (해석이 잘 안됨...)
2. Background and Foundational Concepts¶
A. What is an Explanation?¶
철학적인 문헌에서 "설명을 구성하는 것은 무엇인가"에 대해 많은 논쟁이 있었다. 그중 관심있는 부분은 "어떤 설명이 좋은 설명인가" 혹은 "설명의 진짜 정의는 무엇인가"다. 어떤 사람들은 좋은 설명은 질문에 달려있다고 말한다. 많은 논문이 설명의 기원, 이론 그리고 언어의 토대를 다루고 있다. 그러나 우리의 연구에서 대부분 중요하고 관심있었던 작업은 "왜"라는 질문(Why Questions)이다. 특별히 "어떤 알고리즘에서 알고싶은 것이 무언인가"를 "왜"라는 질문으로 했을 때, 더 이상 질문을 할 수 없을 때까지 질문에 답변을 받을 수 있는 특정 시기를 정량적으로 표현할 수 있다. "왜"라는 질문에는 두 의미가 있는데, "왜(why)" 그리고 "왜 그래야하는가(why should)"이다. 다른 Explainable planning 문헌과 마찬가지로, 철학자들은 "왜 그렇게 하지 말아야 하는지(why-shouldn't)" 질문과 "왜 그렇게 해야 하는지(why-should)" 질문이 실제로 우리가 원하는 "설명성 요건(explainability requirements)"을 제공할 수 있지에 대해 궁금해 한다.
어떤 설명이 가장 좋은 설명인지도 철학자들 사이에서 많은 논쟁이 있다. 많은 사람이 말하기를 그것은 추론(inference)이라고 하는데, 학자들 사이에서 많은 논쟁이 있다. 많은 사람이 말하기를 그것은 추론(inference)이라고 하는데, 귀추법(abductive reasoning)을 사용해서 모든 가능성있는 결과에 대해 설명하는 것과 비슷한 관점이다.
B. Interpretability vs. Completeness¶
설명(explanation)은 두 가지 방식으로 평가될 수 있다.
-
해석가능성(Interpretability)
해석가능성의 목표는 내적 시스템이 사람이 알 수 있는 방법으로 구성되는 것이다. 이 목표의 키 요소는 인지, 지식, 인간의 편향이다. 해석가능한 시스템은 사람이 유저에게 이해가능한 쉬운 언어로 구성되고 의미있는 설명(descriptions)을 제공해야한다.
-
완전무결성(completeness)
완전무결성의 목표는 시스템의 동작을 정확하게 묘사하는 것이다. 설명(explanation)은 시스템의 행동이 더 많은 상황에서 예측 가능해야 완전성이 생긴다. 딥 뉴럴 네트워크를 장착한 컴퓨터 프로그램을 설명할 때, 시스템에서 모든 수학적 연산과 파라미터를 볼 수 있어야 가장 완벽하고 완전한 설명이라고 할 수 있다.
설명가능한 AI 가 직면한 문제는 완전무결성과 해석가능성을 동시에 만족하는 설명을 만드는 것이 어렵다는 것이다. 정확한 설명은 사람에게 쉽게 해석가능하지 않고, 반대로 해석가능한 설명은 가끔 정확한 예측 파워를 내지 못한다.
Herman은 단순히 인간의 기준으로 해석가능한 시스템을 평가하는 것을 경계해야한다고 했다. 그 이유는 사람의 평가는 설명을 조금더 간단하게 만들려는 강력하고 구체적인 편향을 불러일으키기 때문이다. 그는 사람 평가에 의존하면, 연구자들이 투명한 시스템 보다는 설득력 있는 시스템을 만들려고 할 것이라 우려했다. 그는 해석가능한 시스템을 만들때 다음과 같은 윤리적인 딜레마를 제기했다.
- 비윤리적으로 유저에게 더 좋은 설득력을 보이기위해서 설명을 조작하는 경우는 언제인가?
- "투명성 및 윤리"와 "해석가능성에 대한 욕망" 사이의 밸런스를 어떻게 조절할 것인가?
단순화된 설명의 한계를 유저가 이해하지 못함을 이용해 복잡한 시스템에 단순화된 설명을 제시함으로써 신뢰를 얻으려는 행위은 비윤리적이라고 생각하며, 바람직하지 않은 속성을 숨기도록 그 설명이 최적화되어 있다면 더 나쁘다고 보고 있다. 이러한 설명은 본질적으로 오해의 소지가 있으며,유저에게 위험하고 근거없는 결론을 내리는 결과를 초래할 수 있다.
이러한 함정을 피하기 위해서 설명(explanations)은 해석가능성과 완전무결함 사이의 트레이드 오프를 허용해야 한다. 단순한 묘사(descriptions)만을 제공하는 것보다 약간의 해석가능성을 대가로 시스템이 자세하고 완전무결한 묘사를 할수 있게 해야한다. 설명 방법은 트레이드 오프의 하나의 점으로 평가될 것이 아니라, 최대 해석가능성부터 최대 완전무결함의 곡선상에서 어떻게 변화하는 가를 봐야한다.
C. Explainability of Deep Networks¶
딥 네트워크의 연산에 대한 설명은 네트워크의 데이터 처리(processing) 를 설명하거나, 네트워크 내부에서 데이터의 표상(representation) 을 설명하는 것이다. 처리(processing)에 관한 설명은 "왜 해당 입력이 특정 출력으로 이어지는가?"을 대답하는 것이고 프로그램의 실행 추적을 설명하는 것과 같다. 표상(representation)에 관한 설명은 "네트워크가 어떤 정보를 포함하고 있는가?"를 대답하는 것이고, 프로그램의 내부 데이터 구조를 설명하는 것과 같다.
해석가능성에 대한 세번째 접근방법은 자신의 행동에 대한 해석을 단순화하도록 설계된 구조를 가진 설명-생산(explanation-producing) 시스템 을 만드는 것이다. 이런 구조는 데이터의 처리, 표상 혹은 사람이 시스템을 쉽게 이해하는 관점에서 설계될 수 있다.
3. Review¶
급격한 하위 분야의 확장 그리고 불투명한(opaque) 시스템의 정책 및 법적 파장 때문에, 해석가능성에 대한 연구가 급격이 늘어나고 있다. 모든 분야의 논문을 다루기 어렵기 때문에, 심층 신경망 아키텍처에 대해 집중하고, 다른 분야의 논문를 간단히 강조하려한다.
A. Explanations of Deep Network Processing¶
보통 심층 네트워크에서는 큰 숫자의 연산을 통해서 결론을 내린다. 예를 들어, 이미지 분류에서 유명한 구조인 ResNet 에서는 이미지 한장을 분류하기 위해 대략 5천만개의 학습된 파라미터와 100억 회의 부동소수점 연산(floating point operations)을 실행한다. 따라서 이러한 프로세스를 설명하기 위해 직면하는 근본적인 문제는 복잡한 연산들을 줄이는 방법을 찾아야한다는 것이다. 이는 기존 모델과 비슷하게 행동하는 프록시(proxy) 모델 을 만들거나, 가장 연관있는 연산을 강조하는 돌출 맵(salience/saliency map) 을 만드는 것이다.
-
[Paper Links] -
선형 프록시 모델(Linear Proxy Models, LIME)
프록시 모델 접근 법은 Ribeiro에 의해 잘 설명되어 있다. LIME 을 통해 블랙박스 시스템은 입력의 작은 변화로 인한 행동이 추적되어 설명이 가능하며, 그런 다음 데이터는 전체 모델을 위한 단순 프록시 역할을 하는 지역적 선형 모델(local linear model)을 구성하기 위해 사용된다. Ribeiro는 다양한 모델 유형과 문제 영역을 거쳐 의사결정에 가장 큰 영향 미치는 입력 영역(regions)을 식별하는데 사용될 수 있음을 보여주고 있다. LIME과 같은 프록시 모델은 예측가능(predictive)하다. 오리지널 시스템에 대한 충성도(faithfulness)에 따라 실행되고 평가될 수 있기 때문이다. 예를 들어, LIME 모델에서 0이 아닌 차원의 개수를 세는 것처럼 모델의 복잡도에 따라서 측정될 수 있다. 프록시 모델은 복잡성(complexity)과 충성도(faithfulness)의 사이를 정량화된 관계를 제공하기 때문에, 방법들은 서로 벤치마킹될 수 있어서 프록시 모델 접근법을 더 매력적으로 만드는 요소다.
-
의사결정 나무(Decision Trees)
프록시 모델의 다른 대안 방법으로써 의사결정 나무가 있다. 신경망을 의사결정 나무로 분해하려는 시도는 1990년대부터 최근까지 많은 확장을 거쳤다. 주로 shallow networks에 집중하고, 심층 신경망의 프로세스를 생성하는 것을 목표로 하고있다. CRED 알고리즘의 히든 층을 많이 확장시킨 DeepRED가 그 예시다. DeepRED는 의사결정 나무를 간략화하기 위해 여러 전략을 사용했다. RxREN을 사용해서 불필요한 입력을 다듬고, 트리(a parsimonious decision tree)를 생성하기 위한 통계적 방법인 C4.5 알고리즘을 적용했다. 비록 DeepRED는 원래 네트워크와 비슷한 트리를 생성해냈지만, 그 구조가 꽤나 크고 시행 또한 상당한 시간과 메모리를 차지하기 때문에 확장성이 떨어졌다.
[Paper Links]
또 다른 의사결정 나무 방법은 ANN-DT 인데 샘플링 기법을 사용해서 트리를 만든다. 최근접이웃 방법을 사용한 트리 확장 훈련에 샘플링 기법이 사용되는 것이 키 아이디어다.
-
자동 규칙 추출(Automatic-Rule Extraction)
자동 규칙 추출은 의사결정을 요약하기 위한 잘 연구된 또 다른 접근 방법이다. Andrews 는 기존의 규칙 추출 기술을 정리하고 각 규칙에 대한 힘, 반투명성 그리고 퀄리티와 함께 다섯개 차원의 규칙 추출방법에 대한 분류법을 제시했다.
-
[Paper Links] -
(하단 원문 생략)
Decompositional approaches work on the neuron-level to extract rules to mimic the behavior of individual units. The KT method [28] goes through each neuron, layer-by-layer and applies an if-then rule by finding a threshold. Similar to DeepRED, there is a merging step which creates rules in terms of the inputs rather than the outputs of the preceding layer. This is an exponential approach which is not tangible for deep neural networks. However, a similar approach proposed by Tsukimoto [29] achieves polynomial-time complexity, and may be more tangible. There has also been work on transforming neural network to fuzzy rules [30], by transforming each neuron into an approximate rule.
Pedagogical approaches aim to extract rules by directly mapping inputs to outputs rather than considering the inner workings of a neural network. These treat the network as a black box, and find trends and functions from the inputs to the outputs. Validity Interval Analysis is a type of sensitivity analysis to mimic neural network behavior [31]. This method finds stable intervals, where there is some correlation between the input and the predicted class. Another way to extract rules using sampling methods [32], [33]. Some of these sampling approaches only work on binary input [34] or use genetic algorithms to produce new training examples [35]. Other approaches aim to reverse engineer the neural network, notably, the RxREN algorithm, which is used in DeepRED[21].
Other notable rule-extraction techniques include the MofN algorithm [36], which tries to find rules that explain single neurons by clustering and ignoring insignificant neurons. Similarly, The FERNN [37] algorithm uses the C4.5 algorithm [24] and tries to identify the meaningful hidden neurons and inputs to a particular network. Although rule-extraction techniques increase the transparency of neural networks, they may not be truly faithful to the model. With that, there are other methods that are focused on creating trust between the user and the model, even if the model is not “sophisicated.”
비록 규칙 추출 기술은 신경망의 투명성을 증가시켰으나, 그 규칙이 완전히 모델과 일치하지는 않았다.
-
-
돌출 맵(Salience Mapping)
돌출 맵 접근법은 occlusion procedure 로 예시를 많이 드는데, 네트워크에서 돌출 맵 접근법은 occlusion procedure 로 예시를 많이 드는데, 네트워크에서 입력을 반복적으로 넣으면서 네트워크 출력에 어느 부분이 영향을 줬는지 맵을 만든다. 입력 경사(gradient)를 계산하면서 자연스럽게 돌출 맵을 효율적으로 만들 수 있다. 그러나 이런 미분값들은 중요한 정보를 놓칠 수 있기 때문에, 경사 이외에 다른 정보도 전달할 수 있는 다른 접근 방법도 고려한다. 그 예로써 LRP, DeepLIFT, CAM, Grad-CAM, Integrated gradients, SmoothGrad 를 들수 있다.
[Paper Links]- Localization Recall Precision (LRP): A New Performance Metric for Object Detection
- Learning Important Features Through Propagating Activation Differences
- Learning Deep Features for Discriminative Localization
- Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
- Axiomatic Attribution for Deep Networks
- SmoothGrad: removing noise by adding noise
각 기술은 네트워크에서 뉴런들이 강력하게 활성화 되는 활성화 구역과 출력에 가장 많은 영향을 끼치는 민감도 구역 사이에서 균형을 맞추고 있다. 위 방법들을 비교한 것은 Ancona의 문헌에서 확인 할 수 있다.
B. Explanations of Deep Network Representations¶
비록 네트워크의 개별 연산숫자는 방대하나, 심층 신경망의 구조는 작은 서브컴포넌트로 잘 정리할 수 있다. ResNet 에서는 100개의 층으로 구성되어 있고 각 픽셀 정보를 64개에서 2048개의 채널로 연산한다. 심층 신경망 표상의 설명 목적은 이런 병목 현상(bottlenecks)을 통해 데이터 흐름의 구조와 역할를 이해하는 것이다. 이는 세밀하게 나눔으로써 달성할 수 있다. 표상(representations)은 레이어(layer), 유닛(unit), 벡터(vector) 로 나눠서 이해할수가 있다.
-
레이어(Layers)의 역할
레이어는 원래 학습된 네트워크의 문제로부터 다른 문제를 해결하는 능력을 테스트함으로써 이해할 수 있다. 예를 들어, Razavian은 ImageNet 데이터를 이용해 학습한 이미지 객체 분류 네트워크의 내부 레이어가 특정 피쳐 벡터(feature vectors)가 다른 어려운 이미지 프로세싱 문제에 재사용할 수 있다는 것을 확인했다. 심지어 심층 벡터(deep representations, 학습된 피쳐벡터를 가르킴)를 SVM과 같은 간단한 모델에 적용하여 전체 네트워크를 훈련 시키지 않고 SOTA(State Of The Art)를 달성했다.
이렇게 네트워크로부터 한 층을 사용하여 새로운 문제를 해결하는 방법을 전이 학습(transfer learning)이라고 한다. 이는 어마어마한 실용적인 시사점을 주는데, 새로운 데이터 세트와 네트워크의 개발없이 다른 새로운 문제들을 해결할 수 있다는 점이다. Yosinksi는 다른 맥락에서 전달 학습 능력을 정량화하기 위한 프레임워크를 설명했다.
[Paper Links]
-
개별 유닛(Individual Units)의 역할
레이어에 포함된 정보는 더 깊에 개별 뉴런과 개별 합성곱 필터로 나눌 수 있다. 개별 유닛의 역할은 개별 유닛의 반응을 최대화 하는 입력 패턴을 시각화(visualization) 함으로써 질적으로 이해할 수 있고, 개별 유닛이 전이 문제를 해결하는 능력을 테스트 함으로써 양적으로도 이해할 수 있다. 시각화는 경사를 이용한 입력 이미지 최적화, 최대 활성화 되는 이미지를 샘플링, 혹은 같은 이미지를 만드는 생성 네트워크를 훈련 시킴으로써 만들 수 있다. 예시로 개별 유닛들이 분할(segmentation) 문제(넓은 범위의 라벨링된 시각화 개념구역을 분할)를 해결하는 능력을 측정하는 네트워크 해부(network dissection) 방법이 있다. 개별 유닛의 새로운 개념을 포착하는 능력을 정량화 함으로써, 네트워크 해부 방법은 네트워크의 개별 유닛이 담긴 정보를 특징지을 수 있다.
CNN 시각화에서 유닛 표상(unit representations)에 대한 이해를 도울 수 있는 문헌이 있다.
-
[Paper Links] -
(하단 원문 생략)
A review of explanatory methods focused on understanding unit representations used by visual CNNs can be found in [52], which examines methods for visualization of CNN representations in intermediate network layers, diagnosis of these representations, disentanglement representation units, the creation of explainable models, and semantic middle-to-end learning via human-computer interaction.
네트워크 가지치기(pruning of networks) 또한 개별 뉴런의 역할을 이해하는 방법 중 하나다. 특별히 큰 네트워크는 최적화에 도움이 되는 초기화(initializations)과 함께 작은 서브네트워크로 구성되어 성공적으로 훈련 시킨다. 해당 문헌은 설명이 용이한 더 작은 네트워크로 같은 문제를 훈련 시킬 수 있는 전략이 존재한다는 것을 증명했다.
-
-
표상된 벡터(Representation Vectors)의 역할
개별 유닛을 특징 짓는 것과 유사하게 개별 유닛의 선형 결합(linear combination)으로 구성된 벡터 공간에서 다른 방향들을 특징 짓고 있다. CAVs(Concept Activation Vectors)는 사람이 해석할 수 있는 개념과 일치하는 방향을 식별하고 탐색하는 신경망 표상의 해석을 위한 프레임워크다.
C. Explanation-Producing Systems¶
훈련 가능한 네트워크 아키텍처의 일부로 명시적 어텐션(attention)을 포함시키는 방법과 같이, 용이한 설명을 위한 네트워크를 만드는 접근법도 있다. 어텐션은 분리된 표상(disentangled representations)을 학습을 하도록 훈련 시키거나, 직접 생성가능한 설명(generative explanations)을 만들도록 훈련 시킬수도 있다.
-
어텐션 네트워크(Attention Networks)
어텐션 기반의 네트워크는 특정 함수를 학습하는데, 함수는 입력 혹은 내부 피쳐가 네트워크 다른 부분의 정보를 조정하는 것을 볼 수 있게 가중치를 제공한다. 어텐션 기반의 접근법은 비연속적인 순서로 된 문장을 처리하는 기계번역 모델에서 주목할 만한 성공을 거두었다. 그리고 세분화된 이미지(fine-grained image) 분류 분야, VQA(visual question answering) 분야에서도 적용할 수 있다.
[Paper Links]
비록 어텐션을 컨트롤 하는 유닛들이 사람이 읽을 수 있는 해석을 만드는 것을 목적으로 훈련하는 것은 아니지만, 어떤 네트워크를 통과하는 정보맵을 확실히 보여준다. 이는 설명의 일종의 형태로 사용될 수 있다는 뜻이다. 사람의 어텐션 데이터 세트가 만들어지기도 했는데 이는 어텐션 시스템이 얼마나 사람의 어텐션과 유사한지 평가할 수 있다.
[Paper Links]
어텐션뿐만 아니라 다른 흥미로운 설명을 추출 하는 접근 방법도 있다. 어떤 행동에 부합한 설명을 가지는 네트워크를 만드는 목적으로 어텐션을 명시적으로 훈련 시키는 것이다. Ross 에 의해 제시한 이 기술은 네트워크의 입력에 대한 민감도가 "right for the right reasons"에 부합하는 네트워크를 만들도록 적용 및 측정된다. 이 방법은 네트워크가 내부 추론을 학습할 수 있게 사용될 수 있다. 또한, 이전 사례(instances)에서 발견하지 못한 문제를 새로운 방법으로 스스로 해결하는 일련의 모델 학습에 사용될 수 있다.
-
분리된 표상(Disentangled Representations)
분리된 표상 속에는 의미있고 다양한 독립적인 요소를 설명하는 개별 차원이 있다. 잠재 요소(latent factor) 를 분리하는 문제는 PCA(Principal Component Analysis), ICA(Independent Component Analysis), NMF(Nonnegative Matrix Factorization) 방법으로 해결해왔다. 심층 신경망으로 분리된 표상 학습 시킬수 있다. 그중 하나는 정보이론적 측도(information-theoretic measures)로 입력 확률분포를 네트워크로 학습하는 VAE(Variational Autoencoding)가 있다. Beta-VAE 또한 분리된 요소를 잘 볼수 있는 요소중에 하나다. InfoGAN 은 잠재 요소를 최대한 분리되는 목적으로 학습한다. 순방향 네트워크가 유닛의 분리를 유도하도록 특별한 손실 함수를 제안하고 있다. 이는 CNN에서 개별 유닛들이 해석하기 어려운 패턴의 혼합물 대신 일관성있는 유의미한 패치들을 찾는데 사용될 수 있다. 분리된 유닛으로 네트워크의 추론을 해명할 수 있는 그래프와 의사결정 나무를 만들 수 있다. 캡슐 네트워크(capsule networks)와 같은 아키텍처는 네트워크의 정보를 분리되고 높은 레벨의 개념을 나타내는 조각으로 정리할 수 있다.
[Paper Links]- Auto-Encoding Variational Bayes
- beta-VAE: Learning Basic Visual Concepts with a Constrained...
- Interpretable Convolutional Neural Networks
- Growing Interpretable Part Graphs on ConvNets via Multi-Shot Learning
- Unsupervised Learning of Neural Networks to Explain Neural Networks
- Dynamic Routing Between Capsules
-
설명 생성(Generated Explanations)
마지막으로, 심층 네트워크는 시스템의 훈련 일부로 포함해서 인간이 이해가능한 설명을 생성하도록 설계할 수 있다. 설명 생성은 VQA 분야와 세분화된 이미지 분류 문제에서 시스템의 일부로 많이 시연됐다. 두 문제의 시스템에서 "왜냐면(because)"이 들어간 문장을 합성 하면서 자연어로 된 결정(decision)을 설명했다. 해당 설명의 생성기(generator)는 사람이 쓴 설명이 포함된 큰 데이터 셋을 학습했고, 사람이 사용하는 언어로 결정들을 설명했다.
시각적 관점과 텍스트 설명이 동시에 포함된 복합적 설명(multimodal explanations)을 생성할 수도 있다. 이 시스템은 2016 VQA 챌린지에서 우승한 모델에 기반해서 일부를 추가하고 단순화 해서 만들었다. QA문제와 내부 어텐션 지도 이외에 시스템은 추가로 설명에 대한 시각적 포인트를 최적화 시킨 두번째 어텐션 맵 그리고 긴 형태의 설명 생성기를 함께 훈련 시켰다. 두 설명 점수 모두 훌륭하게 작동했다. 흥미로운 것은 가독성 있는 설명의 생성은 네트워크의 출력 결과에 의존한다는 것이다. 즉, 네트워크가 이미 결정을 내린 후에 설명이 생성된다는 점이다.
4. Related Work¶
A. Interpretability¶
이전에 해석가능성에 대해서 분류법과 모범 사례를 정의해보려는 시도가 있었다.
해당 논문의 동기도 본 논문과 비슷하게 해석가능성 분야의 수요가 급격하게 커졌기 때문이다. 그리고 해석가능성에 대한 명확한 정의와 평가기준이 없었다. 저자는 해석가능성을 "사람에게 이해가능한 형태로 설명하는(표현하는) 능력" 으로 정의하고, 다양한 설명가능성에 대한 정의를 제안했다. 그리고 "해석은 설명의 평가를 발견하는 행동이다"라는 개념에 수렴하게 된다. 저자들은 일종의 해석가능한 머신러닝의 정의와 이를 측정할 방법에 합의했다. 해당 논문에 영감을 받아서 해석가능성보다는 설명가능성 관점에서 분류법을 다뤄보기로 한다.
이 논문의 주요 공헌은 해석가능성 평가를 위한 모드의 분류법(a taxonomy of modes)을 제안한 것이다. 응용 프로그램 기반(application-grounded), 사람 기반(human-grounded) 그리고 기능 기반(functionally grounded) 이다. 저자들은 불완전한 문제제기 혹은 최적화 과정에서 평가가 제외 됐을 때 해석가능성이 요구된다고 말하고있다. 그들의 문제제기는 유저와 최적화 문제 사이를 단절 시키는 모델의 불완전성이기 때문에 평가의 접근법들이 중요하다.
-
응용 프로그램 기반(application-grounded)
첫 번째 접근법인 응용 프로그램 기반 방법은 실제 작업과 실제 사람을 포함하는 것이다. 이 평가는 인간이 만들어낸 설명이 특정 작업에서 다른 인간에게 얼마나 도움이 될 수 있는지를 측정한다. 의사가 진단 시스템을 평가하는 경우를 예시로 들 수 있다.
-
사람 기반(human-grounded)
두 번째 접근법인 사람 기반 방법은 간단한 문제에 적용되는 사람의 평가 방식을 사용하는 것이다. 이 방법은 응용 프로그램을 테스트할 타겟 커뮤니티를 찾기 어려울 때 주로 사용한다. 또는, 특별한 최종 목표가 실현되기 어려운 경우, 예를 들어 안전 이슈가 중요한 문제에서 오류를 찾아내는 것 등 문제에서도 사용될 수 있다.
-
기능 기반(functionally grounded)
마지막 방법인 기능 기반 방법은 인간의 주체없이 평가된다. 이 실험 설정에서는 해석가능성에 대한 어떤 공식적인 정의를 증명하기 위해 프록시 또는 단순화된 작업을 사용한다. 저자들은 프록시의 선택이 이 접근법에서 내재된 도전이라는 것을 인정한다. 해석 가능한 모델을 선택하는 것과 모델 행동을 더 잘 표현할 수 있는 덜 해석가능한 프록시 방법을 선택하는 것 사이에는 미묘한 트레이드-오프가 있다. 저자들은 이 점을 인정하고 의사결정 나무를 좋은 해석 가능한 모델로 간략하게 언급한다.
그런 다음 저자들은 해석가능성 연구에서 개방된 문제, 모범 사례 및 향후 작업에 대해 논의하고, 해석가능성의 발견을 위한 데이터 중심 접근법을 크게 권장했다. 해석가능성의 정의에 대한 이러한 공헌이 있음에도 불구하고, 우리는 모델이 제공하는 설명에 각기 다른 초점을 맞춰 정의하고, 각 설명들이 어떻게 평가되어야 하는지를 포함하여 우리만의 분류법을 구별했다.
B. Explainable AI for HCI¶
이전에 설명가능한 AI에 관련된 어떤 논문은 설명가능한 시스템에 관해 상당한 데이터 중심 문헌 분석을 수행했다.
[Paper Links]
이 논문에서 저자들은 기존의 AI 해석가능성 주장을 뛰어넘어, 대신 실제 사용자들에게 효과적이고 실용적인 시스템을 만드는 방법에 초점을 맞췄다. 저자들은 AI 시스템은 "디자인에 따라서 설명가능하다."라고 주장하면서 세 가지 기여로 이를 제시하고 있다. 설명가능한 AI 연구와 관련된 289 개의 핵심 논문과 12,412 개의 인용 논문에 대한 데이터 중심 네트워크 분석(data-driven network analysis), 네트워크 분석을 이용한 동향 관찰, 그리고 설명가능성과 관련된 HCI 연구의 모범 사례 및 향후 연구에 대한 제안이 그 3 가지다.
논문은 대부분 문헌 분석에 중점을 두기 때문에, 저자들은 관련 연구분야에서 설명가능한 인공지능(XAI), HCI의 명료성(intelligibility) 및 해석가능성(interpretability), 연구주제의 동향 분석 방법 등 크게 세 가지 분야만 부각시킨다.
이 논문의 주요 기여는 저자들이 만든 인용 네트워크가 포함된 설명가능한 연구의 상당한 문헌 분석이다. "intelligible", "interpretable", "transparency", "glass box", "black box", "scrutable", "counterfacutals" 그리고 "explainable" 등 키워드의 변형을 문헌에서 검색 및 취합하고, 289 개의 핵심 논문과 12,412 개의 인용 논문을 정리했다. 네트워크 분석을 통해 저자들은 28개의 중요한 클러스터와 9개의 연구 커뮤니티를 발견했다. 이와는 대조적으로, 우리의 연구는 해석가능한 머신러닝과 설명 할 수 있는 딥러닝을 이용한 분류기 연구에 초점을 맞추고 있다.
같은 코어 논문과 인용 논문의 요약(abstracts) 데이터를 사용하여 LDA 기반의 토픽모델링을 시행한 결과, 저자들은 가장 크고, 중심적이며, 잘 연구된 네트워크가 지능과 주변 시스템(intelligence and ambient systems)이라는 것을 발견했다. 우리의 연구에서 가장 중요한 서브 네트워크는 설명가능한 AI 다. FAT(Fair, Accountable and Transparent) 알고리즘과 iML(Interpretable Machine Learning) 서브 네트워크 그리고 설명 서브 네트워크에 관한 이론들이 이에 해당한다.
특히, 저자들은 FATML과 해석가능성의 차이점을 이야기하고 있다. FATML은 사회적 이슈에 초점을 맞추고 있는 반면, 해석가능성은 방법에 초점을 맞춘다. 설명의 이론은 인과 관계(causality)와 인지 심리학(cognitive psychology)을 반사실적 추론(conterfactual reasoning)과 인과 설명(causal explanations)의 공통 부분으로 결합시킨다. 이 두 가지는 우리의 분류 분석에서 중요한 요소들이다.
우리는 이들의 논문 마지막에서 언급한 두 가지 동향이 흥미로웠다(머신러닝 생산 규칙(ML production rules)과 엄격하고 사용 가능한 지식에 대한 로드맵). 저자들은 해석가능성이 적용된 고전적인 AI 방법들의 부족을 지적하며, 현재의 연구에서는 그러한 방법들의 광범위한 적용을 장려한다. 본 논문은 주로 설명가능성에서 HCI 연구 어젠다를 정하는 데 초점을 맞췄지만, 우리 연구와 관련된 많은 논점을 제기한다. 특히, 문헌 분석은 심리학 및 사회과학에서 하위 주제와 하위 학문을 발견했는데, 아직 우리의 분석과 관련이 있는 것으로 확인되지는 않았다.
C. Explanations for Black-Box Models¶
최근 블랙박스(black-box) 모델을 설명하는 조사에서는 이해하기 힘든(opaque) 알고리즘을 사용한 주요 문제의 분류를 제공하기 위한 분류법을 소개했다. 조사된 대부분의 방법은 신경망을 기반으로한 알고리즘 이기 때문에 우리의 연구와 연관이 있다.
[Paper Links]
저자들은 이해하기 힘든 머신러닝 모델에 기초한 의사결정 시스템을 설명하는 방법에 대해 개요를 제공한다. 그들의 분류법은 세세하고, 설명 접근법에 근거해 작은 구성요로 구별된다. 그들은 각 설명 방법에 대해 네 가지 특징을 이야기 했다.
- 당면한 문제의 종류
- 블랙박스를 여는 데 사용되는 설명 능력(The explanatory capability used to open the black box)
- 설명되는 블랙박스 모델의 유형
- 블랙박스 모델에 전달된 입력 데이터의 종류
그들은 주로 직면하는 문제의 유형에 따라 설명 방법을 나누고, 다음과 같은 네 가지 설명 방법 그룹을 식별한다.
- 블랙박스 모델 설명 방법
- 블랙박스 결과 설명 방법
- 블랙박스 검사 방법
- 투명박스 설계 방법
그들의 분류 특징과 문제 정의를 사용하여, 그들은 채택된 설명 기능의 유형, 블랙 박스 모델 "개방여부" 및 입력 데이터에 따라 방법을 토론하고 추가로 분류했다. 이들의 목표는 주요 블랙박스 설명 아키텍처를 검토하고 분류하는 것이다. 따라서 이들의 분류는 유사한 문제와 접근방식을 식별하는 지침이 될 수 있다. 우리는 이 연구가 설명 방법의 설계 공간을 탐색하는 데 유용하고 의미있는 기여를 하고 있다는 것을 발견했다. 우리의 분류는 덜 세분화되어 있다. 구현 기법을 세분화하기 보다는 설명 능력의 초점과 각 접근방식이 설명할 수 있는 것을 조사하며, 다양한 유형의 설명가능성(explainability) 방법이 어떻게 평가될 수 있는지를 이해하는 데 중점을 둔다.
D. Explainability in Other Domains¶
설명가능한 계획법(Explainable Planning)은 planning 커뮤니티에 있던 모델 기반 표상을 활용하는 새로운 학문이다. 수년 전 몇가지 핵심 아이디어가 계획 인식 분야에서 제안됐다.
[Paper Links]
설명가능한 계획법은 계획 알고리즘과 인간의 문제-해결력 사이의 차이를 인정하면서, 사용자와의 의사소통을 위한 친숙하고 일반적인 기반을 촉구한다. 이 논문에서, 저자들은 설명이 대답할 수 있는 다양한 유형의 질문의 개요와 예를 제공한다. 예를 들어, " 왜 A 행동을 했니?" 혹은 "왜 B 행동을 하지 않았니(DIDN'T)?", "왜 C 행동을 하지 못했니(CAN'T)?" 등등. 또한 저자들은 계획을 자연어로 표현하는 것은 계획을 설명하는 것과 같지 않다고 강조한다. 설명 요청은 "질문자가 시스템에서 사용할 수 있어야 하며 질문자가 가지지 않았다고 믿는 지식의 일부를 밝혀내기 위한 시도"이다. 이 질문은 결론에서 이야기한다.
설명 자동 생성(Automatic explanation generation)은 스토리를 이야기 할 수 있는 컴퓨터와 기계와 밀접해 있다. John Reeves의 논문에 따르면, 그는 이야기를 읽고, 특징을 요약하고, 믿음을 추론하며 그리고 갈등과 해결을 이해하기 위해 THUNDER 프로그램을 만들었다.
[Paper Links]
다른 연구에서는 스토리 이해를 하는 데 필요한 구조를 나타내는 방법을 검토한다.
[Paper Links]
Genesis Story-Understanding 시스템은 상위 개념 패턴(higher-level concept patterns)과 상식 규칙(commonsense rules)을 이용하여 스토리를 이해하고, 사용하고, 구성하는 작업 시스템이다. 설명 규칙은 누락된 원인 또는 논리적 연결을 제공하는 데 사용된다.
인간-로봇 상호작용과 스토리텔링의 교차점에는 언어화(verbalization)가 있다. 즉, 인간과 로봇의 상호작용에 대한 설명을 생성한다.
[Paper Links]
유사한 접근방식은 사례 기반 모델 또는 설명 일관성을 사용하는 유괴 추론에서 찾을 수 있다.
[Paper Links]
설명 자동 생성은 새로운 사상을 상상하거나 통계적 접근법을 통한 지식의 격차를 메우는 방법으로 뇌와 인지과학에서도 잘 연구된 분야다.
[Paper Links]
5. Taxonomy¶
3가지 다른 카테고리로 접근법을 나눌 수 있다.
- 비록 의사결정 프로세스를 대표 하지는 않지만, 어떤 논문은 방출된 선택에도 적용할 수 있는 정당성의 척도(degree of justification)를 제공하는 설명을 제안한다. 이는 사람이 믿을 만한 정확하고 합리적 시스템의 구축을 위한 설명 요구에 대한 응답(근거)로 사용될 수 있다. 이런 시스템은 보통 데이터의 처리를 모방(emulate)하여 시스템의 입력과 출력 사이의 연결관계 이끌어 낸다.
- 설명의 두 번째 목적은 네트워크 내부의 데이터 표현을 설명하는 것이다. 이것들은 네트워크의 내부 작동에 대한 통찰력을 제공하며, 네트워크 내에서 활성화된 데이터에 대한 설명이나 해석을 용이하게 하는데 사용될 수 있다. 이는 프로그램의 내부 구조를 설명하는 것과 달리, 특정 중간 표현(intermediate representations)이 왜 특정 선택으로 이어졌는 지에 대한 정보를 얻을 수 있다.
- 마지막 설명의 유형은 설명-생성 네트워크다. 이런 네트워크는 스스로 설명을 할 수 있게 구축하며, 불투명한 서브시스템의 해석을 단순화하도록 설계되었다. 처리 및 표현, 혹은 다른 부분이 정당하고 이해하기 쉬운 부분은 서브시스템의 투명성을 높이는 방법은 두 가지 단계다.
우리가 제시하는 분류법은 광범위한 기존 접근법 집합이 주어졌을 때, 머신러닝 시스템의 해석가능성 및 완전무결성의 다양한 척도를 달성하려고 할 때 유용하다. 그러나 동일한 문제를 해결한다고 주장하는 두 가지 뚜렷한 방법이 실제로 매우 다른 질문에 답하고 있을 수 있다. 우리의 분류법은 기존 접근법에 근거하여 문제 공간을 세분화하여 기존 분류보다 더 세밀하게 하려고 한다.
우리는 다음 표에 리뷰한 방법들에 대한 카테고리를 분류했다.
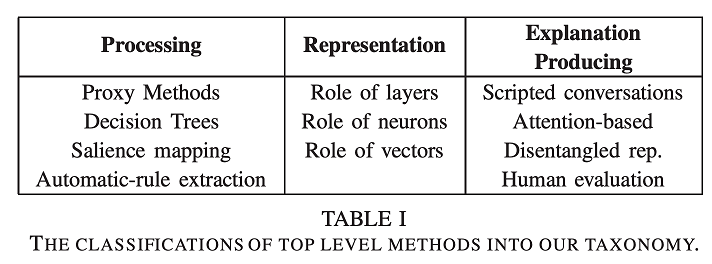
주목할 점은 처리(processing)과 해설을 만들어내는(explanation-producing) 역할이 표현(representation)보다 더 많다는 것이다. 우리는 이러한 차이가 "표현에 기반한 모델(representation-based models)은 평가하기 어렵다"라는 사실에 기인한다고 믿는다. 유저-스터디 기반 평가가 항상 적절한 것은 아니다. 특정 표현을 추가하고 제거하는 방법으로 더 좋은 퍼포먼스를 측정하는 수치적 방법은 사용하기 힘들다.
우리의 분류법의 역할은 여러 카테고리를 걸쳐 연구와 평가를 촉진하는 것이다. 해석의 목적[74]과 유저와의 연결[75]을 평가하는 다른 설명적, 해석적 분류법 대신에, 우리는 집중적으로 방법에 대한 평가를 하려고 한다. 이 방법이 네트워크의 데이터 처리를 설명하는지, 네트워크 내부의 데이터 표현을 설명하는지, 혹은 그 방법을 스스로 설명하는 아키텍쳐인지를 볼 것이다. 이를 통해 그 방법에 대한 추가적인 메타 예측과 통찰력를 얻으려고 한다.
[Paper Links]
우리는 하위범주를 생성하는 설명 분류법을 신경망 아키텍쳐와 시스템을 디자인하는 하나의 방법으로써 제시하려고한다. 또한 표준화된 평가 지표의 부족을 강조하고, 향후 분류학의 영역 교차 연구를 제안하려고 한다.
6. Evaluation¶
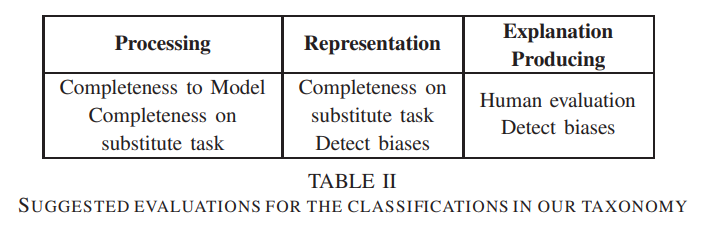
비록 심층 신경망을 위한 설명을 3 가지로 나눴지만, 셋다 같은 평가기준을 가지지 않는다. 조사된 작업의 대부분은 다음 유형의 설명 중 하나라고 할 수 있다.
- 원래 모델과의 완전무결성 비교. 프록시 모델은 설명된 원래 모델에 얼마나 근접했는지에 따러 직접 평가할 수 있다.
- 대체 문제(task)에서 측정했을 때의 완전무결성. 어떤 설명은 모델의 의사결정을 직접적으로 설명하지 않는다. 하지만 다른 어떤 속성을 대신 측정할 수 있다. 예를 들어 모델 민감도는 무차별 측정 보다는 모델의 민감도를 잘 보여주는 돌출 설명(salience explanation)으로 평가할 수 있다.
- 편향(bias)이 있는 모델을 탐지하는 능력. 특정 현상의 민감도(예를 들어, 입력에 대한 특정패턴의 존재 등)를 나타내는 설명은 모델관련 편향의 존재여부를 나타내는 능력을 통해 검증 될 수 있다.
- 사람의 평가. 사람은 설명이 사람의 기대와 얼만큼 일치하는지를 판단하여, 설명을 평가할 수 있다. 사람의 평가는 "인간이 원래 모델의 행동예측을 할 수 있다"라는 관점 혹은 "사람에게 모델의 편향이 들어나면서 도움이 된다"라는 점에서 완전무결성 혹은 대체-작업의 완전무결성을 평가할 수 있다.
따라서 두 번째 테이블에서 볼 수 있듯이, 해석가능성과 완전무결성 사이의 트레이드 오프가 프록시 모델의 단순성과 정확성 사이의 균형을 뜻하지는 않는다. 중요한 모델의 편향을 찾아내는 능력 측면에서 다른 작업에 대한 설명 혹은 설명의 평가를 통해서 트레이트 오프를 절충할 수 있다. 각 세 가지 유형의 설명 방법은 완전무결성을 평가할 수 있는 설명을 제공할 뿐만 아니라 모델의 모든 세부 결정을 설명하는 것 보다 더 쉽다.
-
Processing
처리 모델(Processing models)은 에뮬레이션 기반 방법이라고 볼 수 있다. 프록시 방법은 기존 모델을 향한 충실도(faithfulness, 기존 모델에 얼마나 비슷한지)를 통해 평가 된다. 이러한 지표중 몇 개는 다음 논문에 소개되어 있다.
이 논문의 주요 꼭지는 모델의 완전무결성 평가는 지역적이여야 한다는 것이다. 만약 모델이 전역적으로(globally) 복잡한 심층 신경망이더라도 일부 행동을 근사함으로써(approximating) 지역적 설명을 할 수 있다. 그러므로 처리 모델 설면은 설명의 "복잡성(complexity)"(근본적으로 길이를 최소화)과 "지역적 완전무결성(local completeness)"(실제 분류기와 관련된 해석가능한 표현의 오류)을 최소화 하려는 것이다.
민감한 지역을 강조하는 돌출 방법(Salience methods)도 정성적으로 평가된다. 비록 이들은 기존 방법의 출력을 직접적으로 예측하지 않지만, 원래 의도는 모델 민감도를 설명하기 위한 것이기 때문에 충실성(faithfulness)을 평가할 수 있다. 예를 들어 다음 논문에서는 다양한 버전의 일부가 가려진 입력 이미지를 모델에 전달하고 테스트하는 폐쇄(occlusion) 실험을 진리로 둔다.
이 실험은 입력의 어느 부분이 모델의 출력 결과를 가장 많이 변화시키는지에 대해 강력하지만 연산적으로 비효율적인 방법으로 결정한다. 폐쇄성 기반 민감도(occlusion-based sensitivity)와 상관관계가 있는 돌출 맵을 얼마나 밀접하게 만들어 냈는가를 통해 각 돌출 방법(Salience methods)을 평가된다.
-
Representation
표현 기반 방법은 다른 전이학습과 관련된 작업의 테스트를 통해 표상(representation) 일부의 역할을 특징화(characterize)할 수 있다. 예를 들어 전이 문제(transfer problem)에서 입력 피쳐의 역할을 할 수 있는 표상 층이 있다. 그리고 Network Dissection representation 와 CAV(Concept Activation Vectors) 두 방법은 모두 사람이 이해할 수 있는 특정 개념으로 감지하거나 상호 연관 짓는 능력에 따라 측정된다.
개별 표상의 일부가 특징화 되면 설명력을 테스트 할 수 있다. 그들의 활성화 값이 얼만큼 충실하게 특정 네트워크의 편향을 보여주는지를 평가하면서 실행할 수 있다. 예를 들어 CAV(Concept Activation Vectors)는 클래스를 결정짓는 두 가지 다른 유형의 시그널을 담은 데이터로 여러 버전의 구조가 같은 네트워크를 훈련시키면서 이를 평가하게 된다(데이터: 이미지와 다양한 신뢰도를 이름으로 한 클래스 텍스트). CAV의 네트워크 충실도는 두 가지 방법을 통해 식별될 수 있다. 하나는 텍스트 라벨에 의존하는 분류기가 텍스트와 연관되어 높은 CAV 벡터 활성화 값을 보이는가, 다른 하나는 텍스트 라벨에 의존하지 않는 분류기가 낮은 CAV 벡터값을 보이는 것이다.
-
Explanation Producing
설명 생산 시스템은 얼마나 유저의 기대와 잘 부합되는 지에 따라 평가된다. 예를 들어 네트워크 어텐션은 사람의 어텐션과 비교할 수 있다. 그리고 분리된 표상(disentangled representations)은 잠재된 변수를 가지고 있는 합성된 데이터를 통해 잠재 변수가 복구되었는 지를 확인함으로써 테스트 할 수 있다. 마지막으로 시스템은 명시적으로 사람이 읽을 수 있는 설명을 생성함으로써 테스트 세트 혹은 사람의 평가에서도 똑같이 동작 하는지 확인한다.
설명 생산 시스템에서 설명력을 평가하기 어려운 점중에 하나는 시스템 자체가 설명을 만들어 내야 하기 때문에, 반드시 설명의 평가와 함께 시스템에 대한 평가를 병행해야 한다는 것이다. 불합리해 보이는 설명은 시스템이 정보를 합리적인 방법으로 처리하지 못했거나, 설명 생성기가 합리적인 설명을 작성하지 못했음을 통해 나타낼 수 있다. 반대로, 비록 시스템이 불합리한 규칙을 이용해 의사결정을 내리더라도 의사결정 과정에 충실하지 못한 설명 체계는 합리적인 설명을 생산할 수 있다. 합리성에만 의존하는 설명의 평가는 이러한 차별점을 놓칠 수도 있다. 모델과 사용자간의 공백을 메우도록 돕는 여러 유저-학습 디자인을 요약한 논문이 있다.
7. Conclusions¶
심층 신경망 커뮤니티에서 보여진 공통적인 관점은 대형 DNN 모델의 완전한(투명한) 설명을 위해 필요한 해석가능성과 이론적 이해 수준이 여전히 부족하다는 점이다. 예를 들어서, Yann LeCunn은 NIPS에서 Ali Rahimi의 "Test of Time" 발표에 대한 대답으로, "엔지니어링의 산물은 항상 이론적인 이해보다 선행되어 왔다." 라고 이야기했다. 그러나, 우리는 기계 학습 시스템이 회의적인 대중들 사이에서 더 넓은 수용을 얻기 위해서는, 그러한 시스템이 그들의 결정에 대해 만족스러운 설명을 제공하거나 허용할 수 있는 것이 중요하다고 주장한다. 심층 네트워크 처리(deep network processing)의 설명, 심층적인 네트워크 표현(deep network representation)에 대한 설명, 시스템 수준의 설명 생산에 대한 노력으로 이루어진 발전은 유망한 결과를 낳았다.
그러나 우리는 설명가능성의 다른 측면을 다루기 위해 취해진 다양한 접근방식이 고립되어 있다는 것을 발견했다. 더 효율적인 설명을 달성하기 위해 다른 범주의 기술을 합병하는 접근 방법과 같은 설명가능성 공간에 대한 작업은 상대적으로 적은 주의를 주고도 특정 범주의 기술의 발전을 야기했다. 설명의 목적과 유형이 주어졌을 때, 어떤 설명 측정기준이 제일 좋은 것인지 알기가 명확하지 않다. 우리는 표적 설명(the targeted explanation)의 목적과 완전무결성에 맞는 다양한 측정기준을 사용하길 권장한다. 커뮤니티에서 다양한 분야의 여러 아이디어를 합치고 함께 작업하고 배우면서, 시스템 설명의 전반적인 상태 눈에 띄게 향상될 것이다. 그 결과로 행동 추정(behavioral extrapolation)을 제공하고, 딥러닝 시스템의 신뢰를 구축하고, 심층 네트워크 연산의 유용한 인사이트 등 시스템 행동의 이해와 증진을 가능케한다.