Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
Abstract¶
1. Introduction¶

- Text-to-SQL semantic parsing 문제는 자연어 발화(NL utterances)를 실행가능한 관계형 데이터베이스 쿼리(relational DB queries)로 매핑하는 문제다.
- 모델은 훈련때 보지 못한 관계형 데이터베이스에서 질문의 의도를 파악하고 정확한 쿼리를 만들어야 한다.
- 지금까지 다른 연구들은 3가지 디자인 원칙으로 진행되고 있다.
- 질문과 스키마 표현들이 서로 연관(문맥화 contextualized)되어 있다.
- BERT나 RoBERTa와 같은 Pre-trained Language Models이 변화무쌍한 자연어에 대해 일반화를 잘 할 수 있고, 장기적인 의존성을 포착하여 구문 분석 정확도를 크게 높일 수 있다.
- 데이터베이스를 더 많이 학습 할수록 모델의 스키마에 대한 이해도는 높아진다.
- 스키마와 질의에서 나오는 단어를 잘 연결하기 위해서, BRIDGE는 anchor text를 포함한 하이브리드 시퀀스를 만든다. Anchor text는 DB와 자연어 질의에 공동으로 등장한 단어들이다.
2. Model¶
2.1 Problem Definition¶
- 자연어 질의를 \(Q\), 관계형 데이터베이스의 스키마를 \(S = <\mathcal{T}, C>\), 해당하는 SQL을 \(Y\)로 정의함
- 스키마\(S\)는 테이블 \(\mathcal{T} = \{t_1, \cdots, t_N\}\), 필드 \(C = \{c_{11}, \cdots, c_{1\vert T_1 \vert}, \cdots, c_{n1}, \cdots, c_{N\vert T_N \vert} \}\)로 정의된다. 이 중에 몇개는 primary key, foreign key가 할 수 있고, 각 필드는 고유한 데이터 타입이 있다. \(\tau \in \{ \text{number}, \text{text}, \text{time}, \text{boolean}, \text{etc.} \}\)
- DB Contents를 고려한 모델(현실적이지는 않을듯..)
2.2 Question-Sechema Serialization and Encoding¶
-
테이블과 필드는 각각 스페셜한 토큰 \([T]\)와 \([C]\)를 가지고 있음, 자연어 질의와 스키마는 \([SEP]\) 토큰으로 분리되어 있음
\[X = [CLS], Q, [SEP], [T], t_1, [C], c_{11}, \cdots, c_{1\vert T_1 \vert}, [T], t_2, [C], c_{21}, \cdots, c_{N\vert T_N \vert}\] -
\(X\)는 BERT로 인코딩하고 bi-directional LSTM를 통과해서 base 인코딩된 \(\mathbf{h}_X \in \Bbb{R}^{\vert X\vert \times n}\)을 얻는다. 그리고 질의 \(Q\) 부분은 다른 bi-directional LSTM을 통해 \(\mathbf{h}_Q \in \Bbb{R}^{\vert Q \vert \times n}\)를 얻고, \([T], [C]\)를 사용해 \(\mathbf{h}_X\)의 일부로 각 테이블와 필드에 해당하는 인코딩을 얻는다.
- dense look-up features(임베딩)로 스키마 메타 데이터를 학습한다. 스키마 메타 데이터란 primary key(\(f_{pri} \in \Bbb{R}^{2\times n}\)), foreign key(\(f_{for} \in \Bbb{R}^{2\times n}\)), 데이터 타입(\(f_{type} \in \Bbb{R}^{\vert \tau \vert \times n}\))을 말한다.
-
메타 데이터 피처들은 feed-forward(\(g(\Bbb{R}^{4n} \rightarrow \Bbb{R}^{n}\))를 통과해서 최종 인코딩을 구한다.
\[\begin{aligned}\mathbf{h}_{S}^{t_i} &= g([\mathbf{h}_{X}^{p}];\mathbf{0};\mathbf{0};\mathbf{0}])\\\mathbf{h}_{S}^{c_{ij}} &= g([\mathbf{h}_{X}^{q}];\mathbf{f}_{pri}^{u};\mathbf{f}_{for}^{v};\mathbf{f}_{type}^{w}])\\ &= \text{ReLU}(W_g[\mathbf{h}_{X}^{q}];\mathbf{f}_{pri}^{u};\mathbf{f}_{for}^{v};\mathbf{f}_{type}^{w}] + \mathbf{b}_g)\\ \mathbf{h}_S &=[\mathbf{h}^{t_1}, \cdots, \mathbf{h}^{t_\vert\mathcal{T}\vert}, \mathbf{h}^{c_{11}}, \cdots, \mathbf{h}^{c_{N\vert{T_N}\vert}}] \in \Bbb{R}^{\vert S \vert \times n} \end{aligned}\] -
\(p\)는 \(X\)에서 테이블 \(t_i\)에 해당하는 \([T]\)의 인덱스, \(q\)는 \(X\)에서 \(c_{ij}\)에 해당하는 \([C]\)의 인덱스, \(u, v, w\)는 각각 \(c_{ij}\)에 해당하는 특성 인덱스다.
2.3 Bridging¶
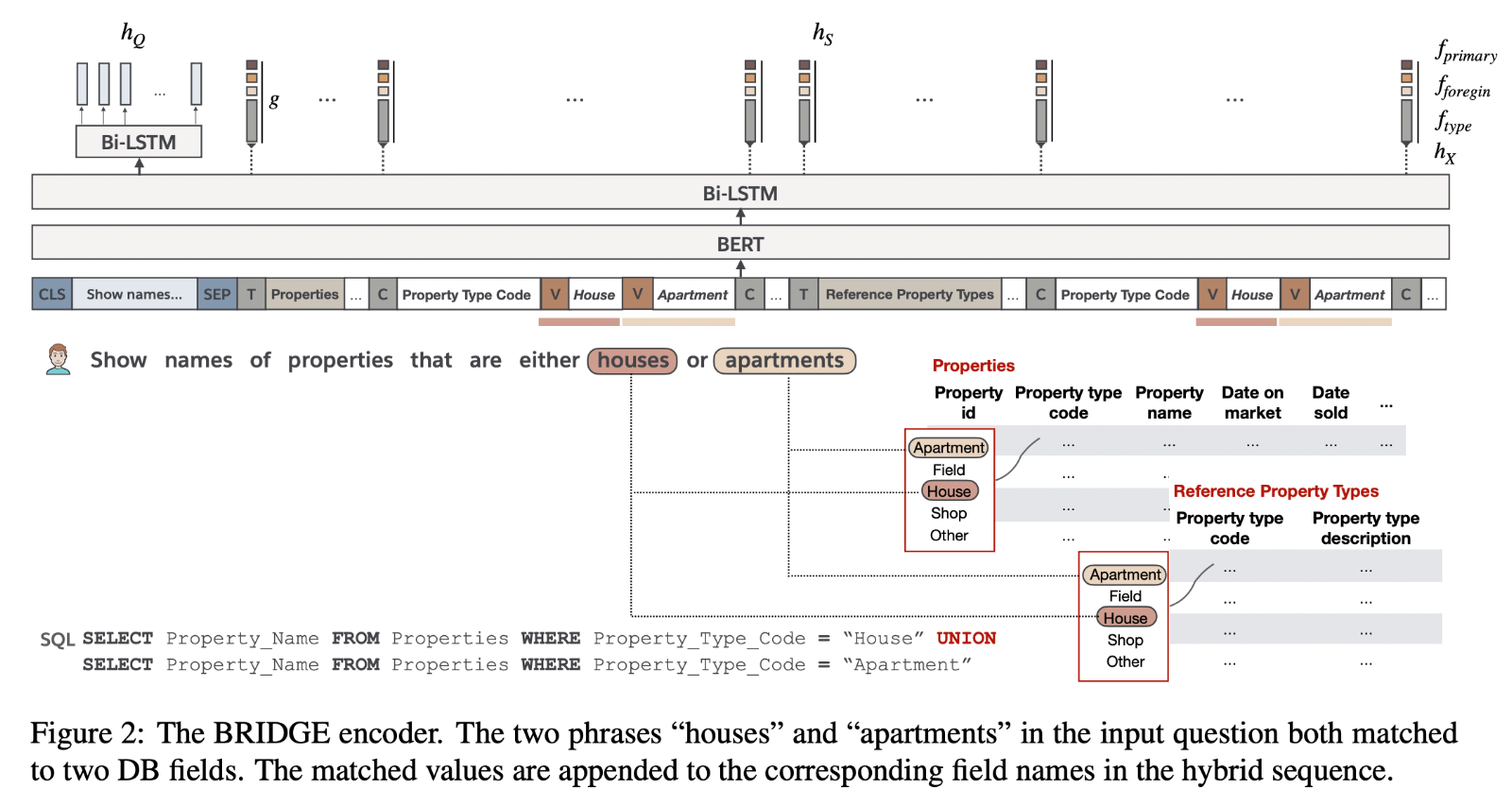
- 필드의 실제값에 접근하지 않으면 해당 필드가 질의에 해당하는 단어와 연관이 있는 지를 알 수가 없다. 따라서 anchor text를 이용해 이 연관성을 연결하려고 한다.
- \(Q\)와 데이터베이스의 필드 값(picklist)의 string match를 통해 매칭된 값이 \(X\)에 들어가게 되며, \([V]\) 토큰으로 분리된다. 만약에 값이 두 개 이상이 되면 값을 concatenate 한다. 여러 테이블에서 같은 필드가 들어가도 그대로 두었음(resolve ambiguity목적: 어떤 모호성?)
- 이러한 과정을 'bridging'이라고 함
2.4 Decoder¶
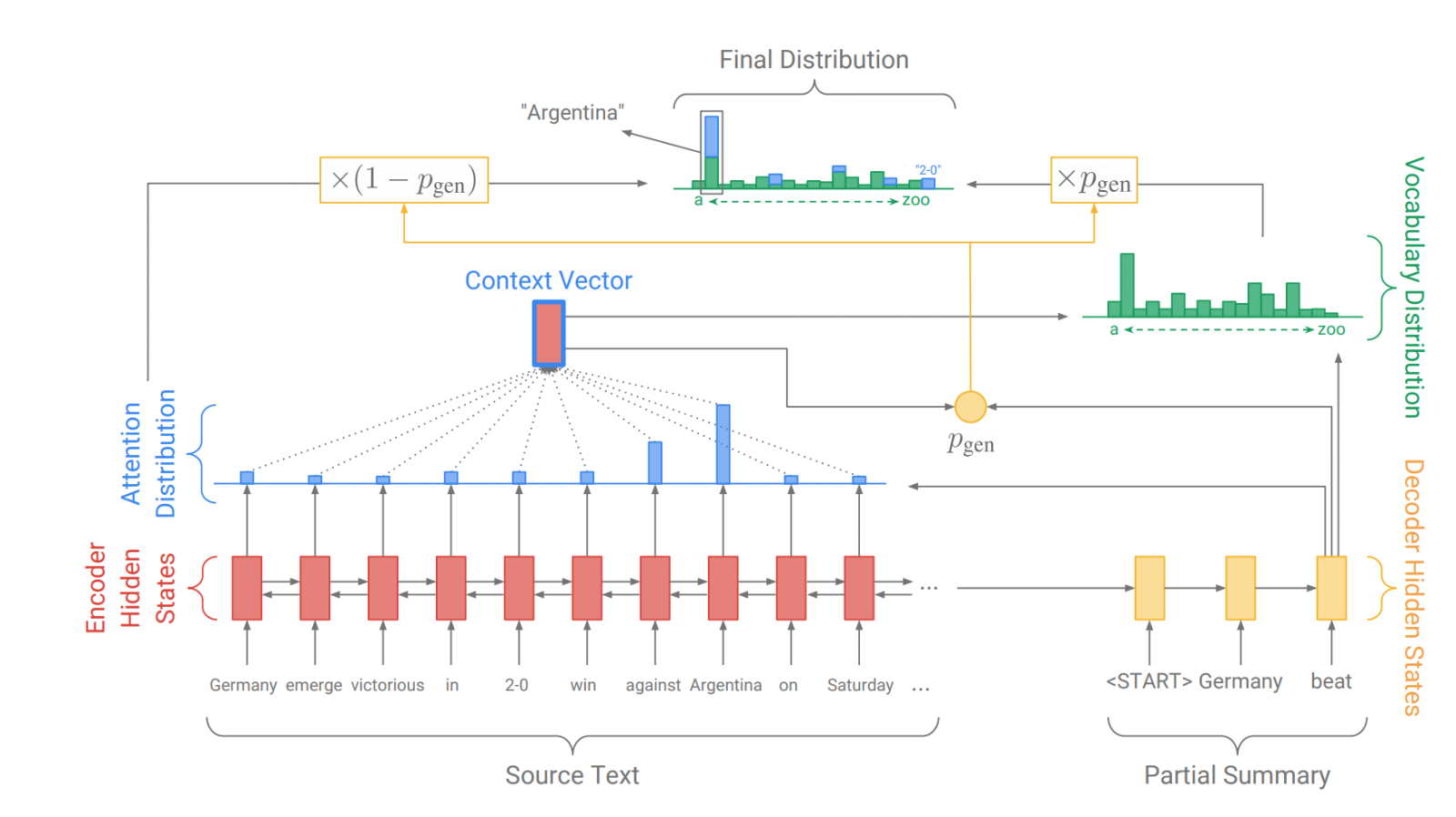
- LSTM 기반 point-generator3와 multi-head attention을 사용, init-hidden은 마지막 질의 인코더의 hidden state 사용
-
매 스텝 마다 단어장(\(V\))에서 토큰 생성하거나, 질의 \(Q\)의 토큰 혹은 스키마 \(S\)의 요소를 복사한다(Copy Mechanism). 스텝(\(t\)), decoder 상태(\(s_t\)), encoder representation를 \([\mathbf{h}_Q;\mathbf{h}_S]\in\Bbb{R}^{(\vert Q \vert + \vert S\vert)\times n}\), \(H\)를 head 개수로 정의한다면, 수학적으로 다음과 같다.
\[\begin{aligned}e_{tj}^{(h)} &= \dfrac{s_tW_U^{(h)}(\mathbf{h}_jW_v^{(h)})^T}{\sqrt{n/H}} ;\quad \alpha_{tj}^{(h)} =\text{softmax}\{e_{tj}^{(h)}\} \\ z_{t}^{(h)} &= \sum_{j=1}^{\vert Q\vert + \vert S \vert} \alpha_{tj}^{(h)}(\mathbf{h}_j W_V^{(h)});\quad z_t = [z_{t}^{(1)}; \cdots ;z_{t}^{(H)}] \end{aligned}\] -
단어장에서 토큰을 생성할 확률은 다음과 같다.
\[\begin{aligned} p_{gen}^t &= \text{sigmoid}(s_t W_{gen}^{s} + z_t W_{gen}^{z} + b_{gen}) \\ p_{out}^t &= p_{gen}^t P_V(y_t) + (1-p_{gen}^t) \sum_{j:\tilde{X}_j=y_t} \alpha_{tj}^{(H)} \\ y_t &= [e_{t-1} ; (1-p_{gen}^t) \cdot \zeta_{t-1} ] \in \Bbb{R}^{2n} \end{aligned}\]- \(P_V(y_t)\)는 decoder LSTM의 출력 확률, \(\tilde{X}\)은 \(X\)에서 질의 단어 토큰, \([T], [C]\)만 담은 시퀀스이며, 총 길이에서 \(\vert Q \vert + \vert S \vert\)를 뺀 값이다.
- \(p_{gen}^t\)은 토큰이 스텝 \(t\)에서 복사될 확률, \(e_{t-1} \in \Bbb{R}^n\)는 스텝 \(t-1\)일 때 단어장 생성된 토큰 임베딩이거나 테이블, 필드 혹은 질의 토큰중 복사된 벡터이다.
-
\(\zeta_{t-1}\in \Bbb{R}^n\)는 스텝 \(t-1\)일 때 encoder 히든 상태의 가중합인 selective read 벡터다. 여기서 \(K=\sum_{j:\tilde{X}=y_{t-1}} \alpha_{t-1, j}^{(H)}\)로 normalization term이며, \(\tilde{X}\)의 다른 포지션에서 \(y_{t-1}\)가 동일하게 나올 수 있기 때문이다.
\[\zeta(y_{t-1}) = \sum_{j=1}^{\vert Q \vert + \vert S \vert} \rho_{t-1, j}\mathbf{h}_j ; \quad \rho_{t-1,j} = \begin{cases} \dfrac{1}{K} \alpha_{t-1,j}^{(H)} & \tilde{X} = y_{t-1} \\ 0 & \text{otherwise} \end{cases}\]
2.5 Schema-Consistency Guided Decoding¶
Generating SQL Clause in Execution Order¶
-
Written order 대신 execution order 순으로 decoding
-
Lemma 1: \(Y_{exec}\)가 execution order SQL이라면 모든 \(Y_{exec}\)의 테이블 필드는 항상 테이블 뒤에 나타난다.
-
Lemma 1로 인해서 binary attention mask \(\xi\)를 적용할 수 있다. 처음에는 0으로 초기화하나, 테이블 \(t_i\)가 디코딩 되었을 때, \(\{ c_{i1}, \cdots, c_{i\vert T_i \vert} \}\) 토큰에 해당하는 \(\xi\)를 1로 준다. 이로인해 decoder가 search space 조금이라도 줄였다.
\[\tilde{\alpha}_t^{(H)} = \alpha_t^{(H)} \cdot \xi\] -
Lemma 2 Token Transition: \(Y\)가 실행가능한 SQL이라면, 모든 \(Y\)의 테이블 혹은 필드는 SQL 예약어 토큰 뒤에 등장할 수 밖에 없다. \(Y\)에서 모든 value 토큰은 항상 SQL 예약어 토큰 혹은 value 토큰뒤에 나타난다.
- 이러한 휴리스틱한 방법을 사용해 후보군을 줄여갔다.
3. Related Work¶
- 논문 참고
4. Experiment Setup¶
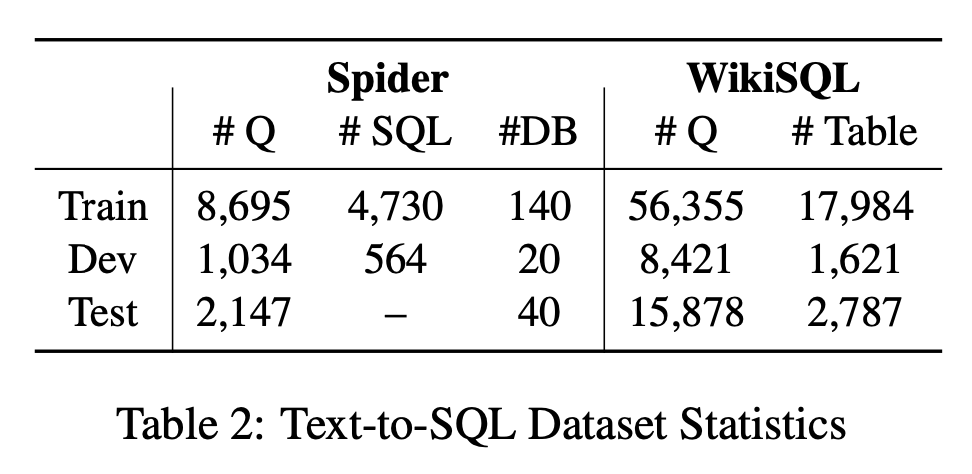
4.1 Dataset¶
4.2 Evaluation Metrics¶
- Exact Match(EM): 예측한 SQL 문구와 ground truth와 정확하게 일치하는 지 본다. 이는 의미적으로 일치하는 SQL이 표면적으로 ground truth와 다르다는 점에서 성능 하한으로 볼 수 있다.
- Exact Set Match (E-SM): 예측된 SQL를 구조적으로 일치하는지 확인, 방법은 예측한 SQL 구문의 집합을 순서와 관계없이 ground truth와 비교한다.
- Execution Accuracy (EA): 예측한 SQL이 target 데이터 베이스에서 실행 결과를 ground truth SQL을 실행 시켰을 때의 결과와 얼마나 일치하는지 보는 것이다. 이는 성능 상한으로 볼 수 있다.
4.3 Implementation Details¶
Anchor Text Selection¶
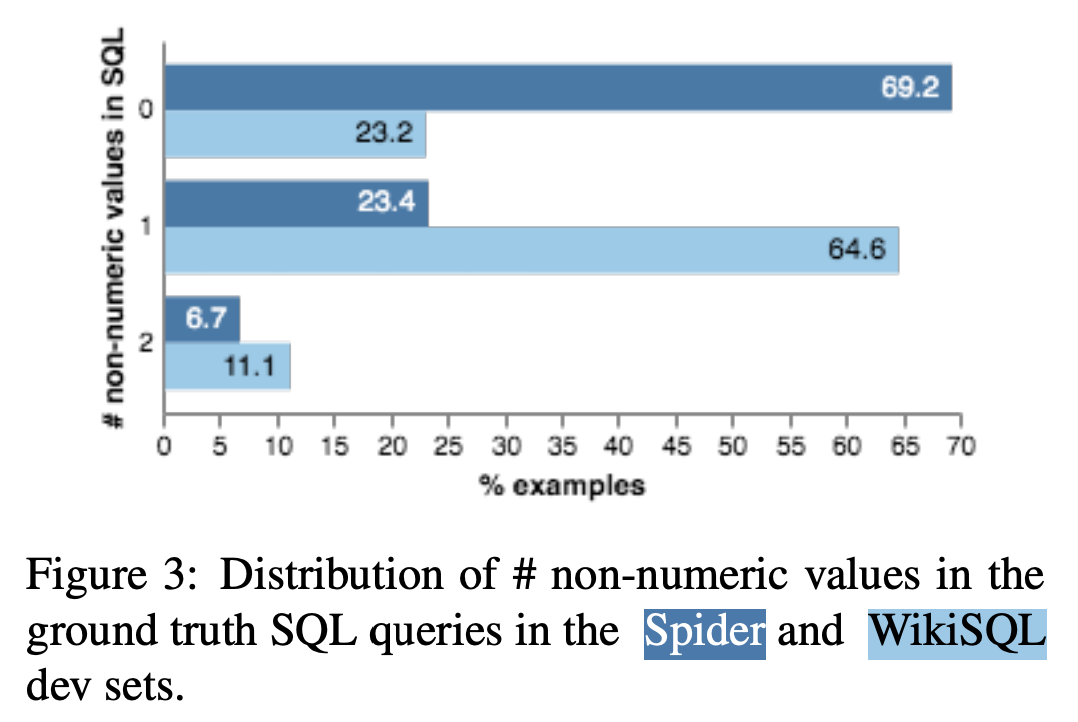
- 알고리즘을 사용해 각 필드에서 k개의 매칭을 고름
- Figure 3에서 보듯이, SQL에서 숫자가 없는 비율은 Spider=69.2%, WikiSQL=23.2% 이기 때문에 단어와 매칭되는 bridging 방법은 매우 유용하다고 주장
Training¶
- 논문 참고
5. Results¶
5.1 End-to-end Performance Evaluation¶
5.1.1 Spider¶
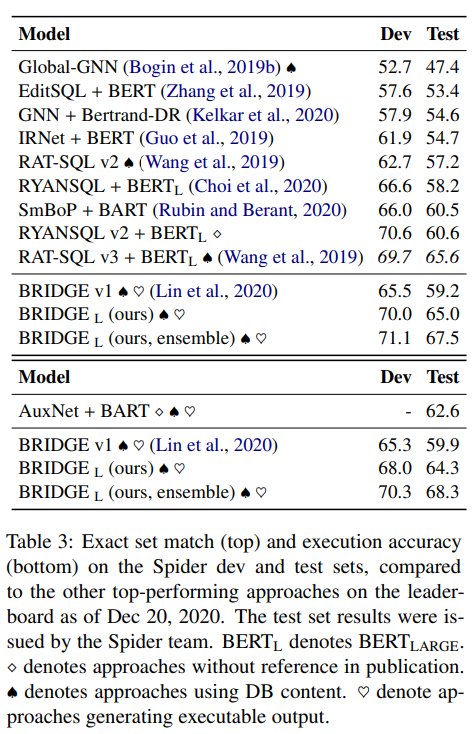
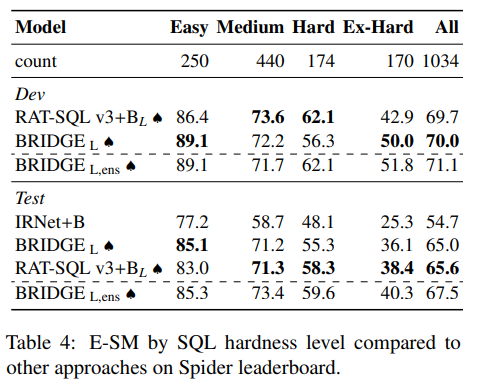
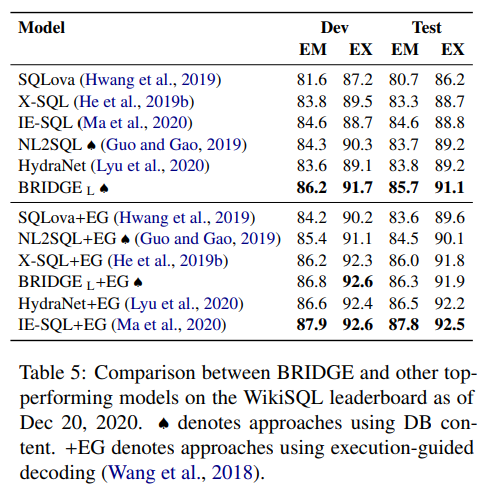
5.1.2 WikiSQL¶
5.2 Ablation Study¶
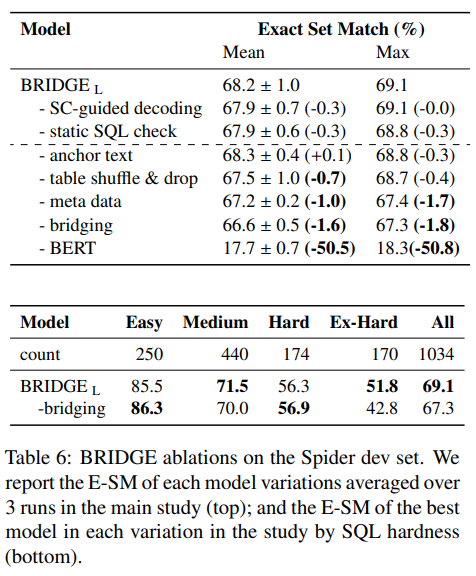
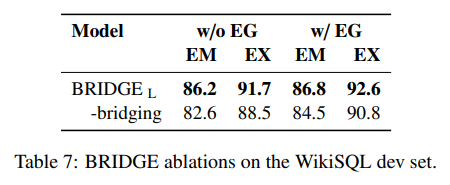
- decoding search space를 줄이는 전략이 어느정도 효과적
- bridging 하는 것과 그렇지 않은 것은 ex-hard에서 성능향상을 불러왔다.
- 메타 데이터를 인코딩하는게 도움이 됨
- BERT 레이어에서 질의와 anchor text에 등장한 단어와 연관이 있는 것을 확인 할 수 있었다.
5.3 Error Analysis¶
5.3.1 Manual Evaluation¶
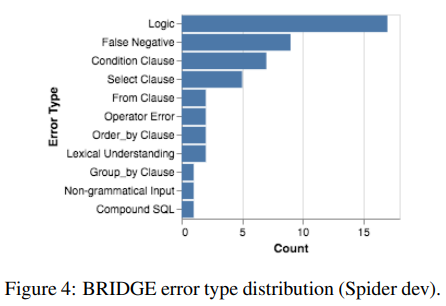
5.3.2 Qualitative Analysis¶

- Logic Error: 보통 모델이 훈련 세트에서 학습했던 것을 dev에서 틀리는 경우가 많음
- Lexcial Understanding: 보지 못했던 단어가 등장하는 경우 자주 나옴
- Common Sense: continuous learning이 솔루션이 될 수 있음
- Robustness: 주로 논리가 복잡하지 않은 경우에도 발화의 정보를 노골적으로 무시하는 모델과 관련
Demo¶
코드를 실행하여 결과가 어떤지 살펴보았다. 아래는 테이블 정보다.

Good Case¶
Query: how many people is in this company?

Query: show me all unique company headquaters

Bad Case¶
Query: what is the most market value headquarter name and who is working in there?
SELECT company.Market_Value_in_Billion, people.Name FROM employment
JOIN people ON employment.People_ID = people.People_ID
JOIN company ON employment.Company_ID = company.Company_ID
WHERE people.Name = "aquater aname"
ORDER BY company.Market_Value_in_Billion DESC LIMIT 1

Query: what is the average age of empolyees?
