Hybrid Ranking Network for Text-to-SQL
Abstract¶
Hybrid Ranking Network for Text-to-SQL1 제안. 문제를 column-wise ranking, decoding 그리고 column-wise 결과물을 SQL 룰에 따라서 모으는 것으로 나눴다.
1. Introduction¶
Relational database는 실제 세상에서 널리 사용되고 있다. SQL은 많이 사용되고 있으나 보통 이를 마스터하기엔 어렵다. 자연어를 통해서 데이터베이스와 소통하는 방법을 오랫동안 연구되어 왔다. 이를 일반화 하면 "Natural Language Interface to Databases(NLIDBs)"2 라는 분야다.
최근에 딥러닝 기반의 방법들이 이를 해결해보고자 했는데 이를 "NL-to-SQL" 혹은 "Text-to-SQL"이라고 하는데, 이 논문에선 Text-to-SQL 문제를 WikiSQL3 데이터로 실험한 것에 대해서만 다룬다.
- 제약 조건: 테이블의 내용을 알고 각 질의(Question)는 하나의 테이블만 해당함
WikiSQL데이터에서 이전에 제안된 연구들은 여러 난관이 있었다.
- NL question과 table schema 정보를 어떻게 조합(fuse) 할 것인가?
- 실행가능하고 정확한 SQL문을 어떻게 생성할 것인가?
- pre-trained language model을 어떻게 활용할 것인가?
이 논문의 동기는 3번 문제였으나 이전의 다른 접근 방법들(Hwang et al, 2019; He et al, 2019)이 language model의 힘을 이끌어 내지 못한다는 점을 주장한다.
- Encoding 단계에서 전체 테이블 스키마를 자연어 질의와 합쳐서 BERT에 전달한다.
- Decoding 단게에서 각 칼럼의 hidden representation을 필요로 한다. 이때 칼럼 토큰들을 adhoc pooling을 하게 된다. 이 ad-hoc pooling이 정보손실을 야기하고 불필요하게 복잡도를 올린다.
따라서 이러한 문제를 해결하기 위해 하나의 칼럼만 인코딩하는 방법을 선택했다. 그리고 Decoding 단게에서 multiple sub-tasks를 수행하게 된다. - Sub-Tasks: SELECT & WHERE column ranking, condition operator 그리고 condition value span 진행
그리고 Decoder가 SQL문을 바로 생성하는 것은 아니기 때문에, 직관적인 룰을 사용하여 결과를 합친다. 이를 통해 다음과 같은 효과를 얻을 수 있다.
- 먼저, question과 column pair 형태가 BERT 혹은 RoBERTa와 sentence pair training task와 유사하기 때문에 효율적으로 이용할 수 있다.
- 둘째, 하나의 칼럼을 인코딩에 사용하기 때문에 [CLS] 토큰 벡터에는 모든 정보(question과 column)를 포함하고 있다. 따라서 더 이상 추가 pooling 혹은 더 복잡한 layer를 추가할 필요가 없다.
2. Related Work¶
생략
3. Approach¶
3.1 Input Representation¶
질문 \(q\) 와 column 후보 \(c_1, c_2, \cdots, c_k\) 가 주어졌을 때, 입력 정보쌍를 다음과 같이 구성할 수 있다.
여기서 \(\phi_{c_i}\)는 column \(c_i\)의 타입 정보(string, real, integer 등), \(\text{Concat}\)함수는 blank space로 토큰을 하나의 string으로 합친다. 따라서, 입력은 tokenizer에 의해서 다음과 같이 토큰화 된다.
여기서 \(x_1, x_2, \cdots, x_m\)은 \(\text{Concat}(\phi_{c_i}, t_{c_i}, c_i)\)을 토큰화 한 것, \(y_1, y_2, \cdots, y_n\)는 질문 \(q\)에 대해 토큰화 한 것이다.
3.2 SQL Query Representation and Tasks¶
이 논문에서 SQL은 nested 구조가 아니기 때문에 다음과 같은 폼을 가진다(WikiSQL 데이터 세트의 제약조건).
"sql" : {
"select": [(agg1, scol1), (agg2, scol2), ...],
"from": [table1, table2, ...],
"where": [(wcol1, op1, value1), (wcol2, op2, value2), ...]
}
SQL를 2개의 Task(Object)으로 분류 할 수 있다.
1. 구체적 칼럼이 필요한 Task: aggregation operator, value text span
2. 구체적 칼럼이 필요하지 않은 Global Task: select_num(SELECT 구문의 갯수), where_num(WHERE 조건문의 갯수)
각 칼럼-질문 입력쌍 \((c_i, q)\)에 대해서 1번 목적은 sentence pair classification과 question answering task로 도식화 할 수 있다. 그 전에 각 토큰에 해당하는 벡터를 다음과 같이 표현한다.
구체적 칼럼이 필요한 Task
- aggregation operator \(a_j\): \(P(a_j \vert c_i, q) = \text{softmax}(W^{agg}[j, :] \cdot h_{\text{[CLS]}})\)로 정의한다. Training 때, SELECT 구문에 속하지 않는 칼럼은 mask out 한다.
- condition operator \(o_j\): \(P(o_j \vert c_i, q) = \text{softmax}(W^{op}[j, :] \cdot h_{\text{[CLS]}})\)로 정의한다. Training 때, WHERE 구문에 속하지 않는 칼럼은 mask out한다.
- value start & end index: \(P(y_j=\text{start} \vert c_i, q) = \text{softmax}(W^{\text{start}} \cdot h_j^q)\)와 \(P(y_j=\text{end} \vert c_i, q) = \text{softmax}(W^{\text{end}} \cdot h_j^q)\)로 정의한다. Training 때, WHERE 구문에 속하지 않는 칼럼에 대해서 시작과 끝 인덱스는 0으로 세팅한다(BERT QA 세팅과 비슷).
구체적 칼럼이 필요하지 않은 Global Task
- \(P(z \vert c_i, q)\): Sentence pair classification
- \(P(c_i \vert q)\): 칼럼과 질문의 유사도, 계산 방법은 다음 세션에서 소개
- SELECT 구문의 개수 \(n_s\)에 대해서는 \(P(n_s \vert q) = \sum_{c_i} P(n_s \vert c_i, q) P(c_i \vert q)\)로 정의
- WHERE 구문의 개수 \(n_w\)에 대해서는 \(P(n_w \vert q) = \sum_{c_i} P(n_w \vert c_i, q) P(c_i \vert q)\)로 정의
3.3 Column Ranking¶
각 질문 \(q\)에 대해서 \(\mathcal{S}_q\)를 SELECT 구문과 연관된 칼럼, \(\mathcal{W}_q\)를 WHERE 구문과 연관된 칼럼이라고 하면, 쿼리문에 나온 칼럼들을 \(\mathcal{R}_q \doteq \mathcal{S}_q \cup \mathcal{R}_q\) 로 정의할 수 있다. 마지막으로 후보 칼럼 집합을 \(\mathcal{C}_q = \lbrace c_1, c_2, \cdots, c_k \rbrace\)이라고 정의 할 수 있으며, 당연하게도 \(\mathcal{R}_q \subseteq \mathcal{C}_q\) 관계가 성립된다.
이에 따라 3개의 Ranking Tasks를 정의할 수 있다.
1. SELECT-Rank: \(q\) 와 연관된 쿼리에서 SELECT 구문에 포함된 칼럼 \(c_i \in C_q\)을 랭킹, \(c_i \in \mathcal{S}_q\)
2. WHERE-Rank: \(q\) 와 연관된 쿼리에서 WHERE 구문에 포함된 칼럼 \(c_i \in C_q\)을 랭킹, \(c_i \in \mathcal{W}_q\)
3. Relevance-Rank: \(q\) 와 연관된 쿼리에서 SQL 쿼리 포함된 칼럼 \(c_i \in C_q\)을 랭킹, \(c_i \in \mathcal{R}_q\)
BERT는 ranking tasks에서 강력한 파워를 보여준다. Qiao et al, 2019에서 \(w \cdot h_{\text{[CLS]}}\)를 ranking score로 간주해서 fine-tuning을 하게 된다. 그러면 각 Ranking Tasks에서 Ranking Score는 다음과 같이 정의 할 수 있다.
-
SELECT-RankScore \(P(c_i \in \mathcal{S}_q \vert q)\)에서 가장 가능성이 높은 후보를 선택한다. 다만 SELECT 구문의 칼럼 갯수 \(n_s\)를 유지하기 위해서 다음과 같이 결정할 수 있다.- 특정 threshold 보다 높은 확률을 가진 칼럼 후보만 선택
-
3.2에서 제안한 \(n_s\)를 직접 예측하기
\[\hat{n}_s = \underset{n_s}{\arg \max} P(n_s \vert q) = \sum_{c_i \in \mathcal{C}_q} P(n_s \vert c_i, q) P(c_i \in \mathcal{R}_q \vert q)\]이번 논문에서는 2번째 방법을 사용했다.
-
WHERE-RankScore \(P(c_i \in \mathcal{W}_q \vert q)\) 도 마찬가지로 직접 \(n_w\)를 예측 한다.\[\hat{n}_w = \underset{n_w}{\arg \max} P(n_w \vert q) = \sum_{c_i \in \mathcal{C}_q} P(n_s \vert c_i, q) P(c_i \in \mathcal{R}_q \vert q)\]
3.4 Training and Inference¶
Training 단계에서 labeled samples를 먼저 \(n_i\) column-question samples 로 바꾼다.
SQL 쿼리 레이블 \((q\_i, \mathcal{C}\_{q\_i})\)은 column-question samples와 함께 3.2와 3.3의 Task를 수행하게 되며, 이 문제의 Optimization Object는 모든 샘플에 대해서 \((c\_{q\_1}, q\_1), (c\_{q\_2}, q\_2), \cdots, (c\_{q\_n}, q\_n)\), 모든 Task의 cross-entropy loss를 줄이는 것이다.
Inference 단계에서는 각 Task의 class labels를 예측한다. 그리고 다음 스텝으로 쿼리문이 만들어진다.
select_num\(n_{s}\) 과where_num\(n_w\)를 예측한다.-
\(c_i \in \mathcal{C}\_q\) 의 랭킹을 통해
SELECT-RankScore를 구하고 상위 \(\hat{n}\_s\) 개의 칼럼(\(\hat{sc}\_1, \hat{sc}\_2, \cdots, \hat{sc}\_{\hat{n}\_s}\)) 을 선택한다 따라서 SELECT 구문은 다음과 같으며, \(\hat{agg}\_i\) 는 예측된 \(\hat{sc}\_i\) (\(i = 1, 2, \cdots, \hat{n}\_s\))의 aggregation operator다\[[(\hat{agg}_1, \hat{sc}_1), (\hat{agg}_2, \hat{sc}_2), \cdots, (\hat{agg}_{\hat{n}_s}, \hat{sc}_{\hat{n}_s})]\] -
\(c\_i \in \mathcal{W}\_q\)의 랭킹을 통해
WHERE-RankScore를 구하고 상위 \(\hat{n}\_w\) 개의 칼럼(\(\hat{wc}\_1, \hat{wc}\_2, \cdots, \hat{wc}\_{\hat{n}\_w}\)) 을 선택한다 따라서 WHERE 구문은 다음과 같으며, \(\hat{op}\_i, \hat{val}\_i\) 는 예측된 \(\hat{wc}\_i\) (\(i = 1, 2, \cdots, \hat{n}\_s\))의 condition operator와 value text다.\[[(\hat{wc}_1, \hat{op}_1, \hat{val}_1), (\hat{wc}_2, \hat{op}_2, \hat{val}_2), \cdots, (\hat{wc}_{\hat{n}_s}, \hat{op}_{\hat{n}_s}, \hat{val}_{\hat{n}_s})]\] -
\(\hat{\mathcal{T}} = \lbrace \hat{t}\_1, \hat{t}\_2, \cdots, \hat{t}\_{n\_t} \rbrace\)를 모든 예측된 칼럼 \(\hat{sc}\_i, \hat{wc}\_i\)의 테이블 집합이라고 정의하면, FROM 구문은 \([\hat{t}\_1, \hat{t}\_2, \cdots, \hat{t}\_{n_t}]\)에 해당된다.
3.5 Execution-guided decoding¶
Neural Network 모델은 입력 질문, column-value 관계에서 추출된 syntactic과 semantic 정보로 SQL 쿼리를 예측한다. 하지만, 런타임에서 좋은 예측을 못내고 있는데 그 이유는 다음과 같다. 1. 데이터베이스의 값과 칼럼들은 이산적인 관계를 가지며 특별한 제약도 없다. 따라서 매핑된 칼럼들은 값이나 성격이 수시로 바뀔 수 있다. 훈련된 모델은 최신 데이터베이스 정보를 놓쳐서 예전 정보를 기반으로 예측할 가능성이 있다. 2. 각 Task에 해당하는 모델의 출력들은 독립적으로 예측한 것이다. 따라서 말이 안되는 조합을 생성할 수 도 있다. string-type의 칼럼에 aggregation operator, greater-than이라는 condition operator를 예측하는 등을 예로 들 수 있다. 이런 케이스들은 가능성을 원천적으로 제거해야한다.
이러한 이슈를 해결하기 위해 Wang et al. 20184 에서는 Execution-guided decoding(EG)를 제안했다. 이 논문에서는 SQL 쿼리문 생성시, 만약 데이터베이스 엔진이 런타임 에러가 나거나 빈 출력을 반환 시, 수정을 해주는 아이디어를 제안했다.
Execution Guided Decoding 알고리즘은 다음과 같다.

4. Experiment¶
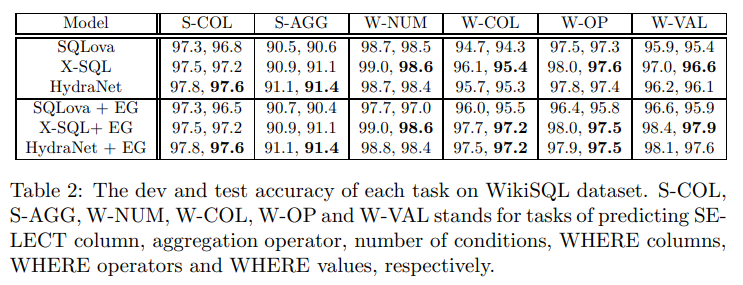
Logical form accuracy를 봤을 때, WikiSQL 데이터 세트에서 우수함을 보인다.
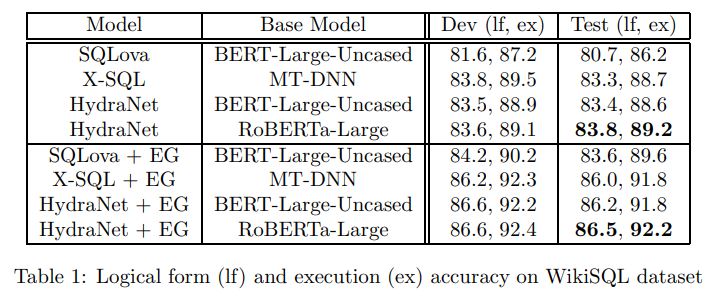
Execution accuracy에서 볼 수 있듯이, HydraNet은 generalization에서도 더 우수함을 보였다.