Attention Is All You Need
Paper Link: Attention Is All You Need
1. Introduction¶
그 동안 LSTM(Long Short-term Memory, 1997)1 과 GRU(Gated Recurrent Unit, 2014)2 등의 RNN 계열은 언어 모델링, 기계번역 등의 문제와 같이 시퀀스 모델링(sequence modeling)을 하기에 최고의 알고리즘이었다.
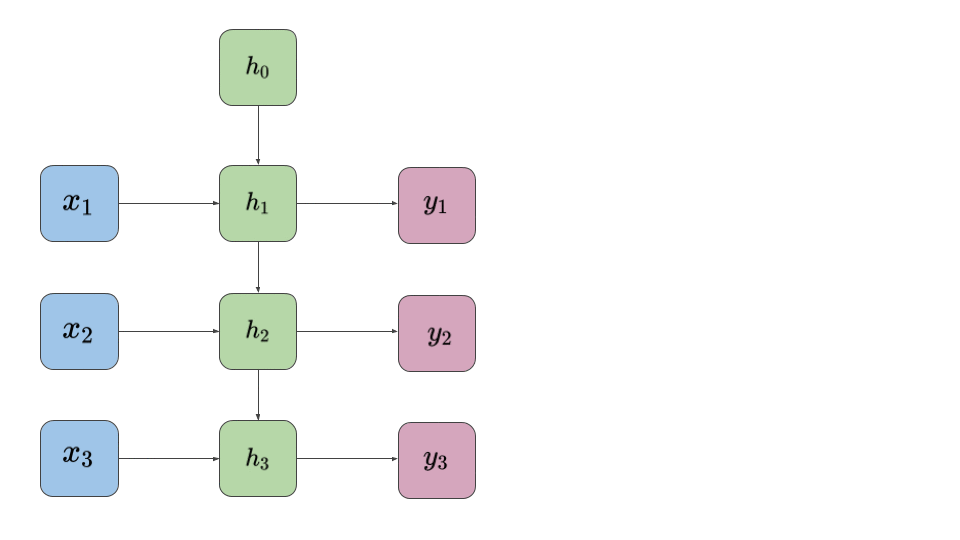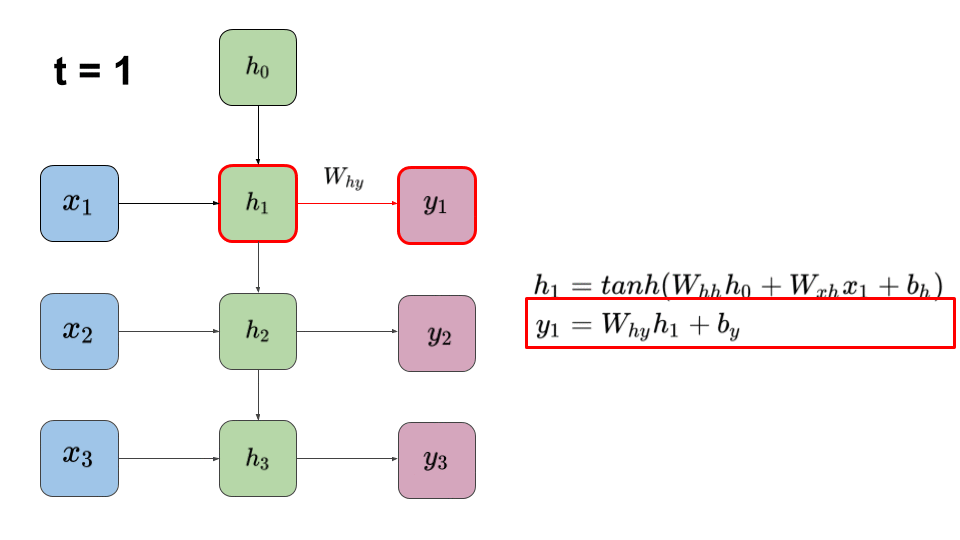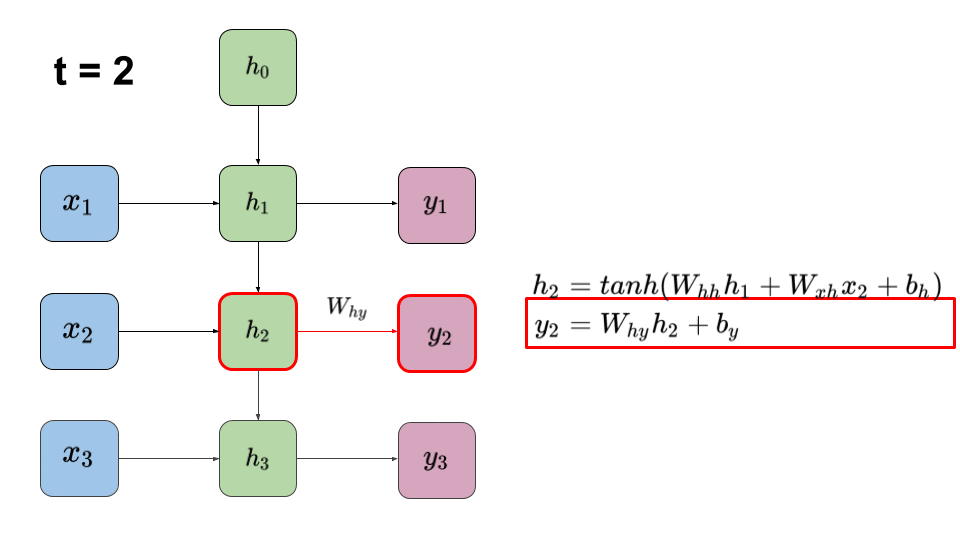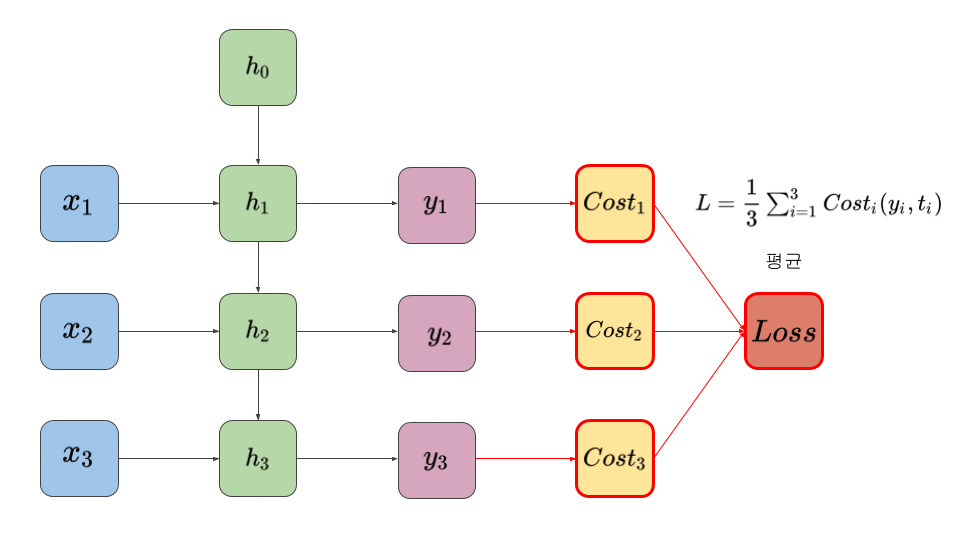
그림 1 처럼 이전 스텝의 은닉층 유닛인 \(h_{t-1}\) 를 현재 스텝의 은닉층 유닛 \(h_t\) 로 전달하면서 자연스럽게 시퀀스 데이터의 특징을 유지하지만, 아쉽게도 병렬 처리를 원천적으로 배제한다는 단점이 존재한다. 따라서 만약에 문장이 길어질 수록 훈련 속도가 현저하게 느려진다.
Input 과 Output 문장의 길이와 관계없이 의존성(dependencies)을 해결해주는 Attention 매커니즘은 시퀀스 모델링 혹은 변환 모델링(transduction modeling: 각기 다른 특성을 가진 입력-출력 데이터를 변환하는 문제들, 예를 들어 기계번역)에서 필수적인 요소가 됐다. 예시로 다음 논문들을 참고하면 좋다.
- Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau 20143
- Structured Attention Networks, Yoon Kim, 20174
- A Decomposable Attention Model for Natural Language Inference, Ankur P. Parikh, 20165
위 두 가지를 결합하여 저자들은 Attention 매커니즘만 활용하여 Input 과 Output 의 의존성을 글로벌하게 처리하고, 병렬화까지 가능한 Transformer라는 새로운 모델구조를 제안했다.
전체 모델구조¶
대부분의 신경망 시퀀스 변환 모델(transduction models)들은 대체로 Encoder 와 Decoder 로 구성된다. Encoder는 심볼로 표현된 입력 시퀀스(비연속적인 토큰들) \(x\) 를 연속 공간(Continuous Space) \(z\) 로 맵핑 후, \(z\) 를 바탕으로 출력 시퀀스 심볼인 \(y\) 를 얻는다. 출력 시퀀스는 이전 타임 스텝(\(t-1\)) 시퀀스를 입력으로 다음 타임 스텝(\(t\))을 출력하는 자기회귀(auto-regressive) 성격을 가진다. 수식으로 다음과 같다.

하지만 Transformer 에서는 한 타임 스텝마다 \(y\) 를 출력하지 않고 한번에 처리한다. 저자들이 제안한 전체적인 모델구조는 그림 2 와 같다(전체적인 느낌만 보고 다음으로 넘어가도록 한다).
Encoder¶
Encoder는 각기 다른 N 개의 "Encoder Layer"라는 층으로 구성되며, 각 층에는 두 개의 서브층(SubLayer)이 존재한다. 첫번째는 Self Attention을 수행하는 "Multi-Head Attention", 두번째는 일반적인 "Position-wise Feed Forward"로 구성되며, 각 서브층은 Residual Network6처럼 서브층의 입력과 출력을 결합하고, 그 결괏값을 다시 LayerNorm7 을 통과시켜 출력을 얻는다. 수식으로 다음과 같다.
Decoder¶
Decoder도 Encoder와 마찬가지로 각기 다른 N 개의 "Decoder Layer" 라는 층으로 구성된다. 다만, Encoder의 출력을 받아서 "Multi-Head Attention"을 수행하는 3번째 서브층이 추가된다. Self Attention을 수행하는 첫번째 "Multi-Head Attention"에서는 뒤에 있는 시퀀스정보로 부터 예측을 하지 않게 이를 가리게 된다. 따라서 \(i\) 번째 토큰은 \(i+1\) 번째 이후의 토큰을 참조하지 않게 됩니다. 나머지는 Encoder와 마찬가지로 잔차 연결(residual connection)을 수행하고 LayerNorm을 통과하게 된다.
이제부터 모델의 세부 사항을 살펴보면서 저자가 왜 이렇게 사용했는지, 의도가 무엇인지를 알아보려고 한다.
2. Scaled Dot-Product Attention¶
Attention¶
Transformer 에서 Attention은 query(Q) 와 key(K)-value(V) 세트를 입력으로 집중된 어떤 벡터를 출력하는 함수로 표현할 수 있다. 출력은 Q 와 K 간의 관계(Attention), 즉 Q 의 정보를 K 에 대조 했을 때, 어느 부분을 집중해서 볼 것인지를 계산하고 해당 관계를 V 와 결합하여 출력을 만든다. 수식으로 다음과 같다.
직관적으로 잘 안떠오르는데, 이게 어떤 느낌인지 알아보기위해 예를 들어보면 다음과 같다.
기계번역 문제¶
영어를 한국어로 번역하는 문제를 예로 들자면, 영어는 소스 문장, 한국어는 타겟 문장이 된다. query(Q), key(K), value(V) 관계는 그림 3 과같이 표현할 수 있다.

- query(Q): 한국어 문장 정보
- key(K)-value(V) 세트: 인코딩된 영어 문장 정보, key(K) 와 value(V) 는 같은 벡터
Q 는 우리가 알고 싶어하는 문제라고 생각할 수 있다. 명칭도 "query=질의" 그대로 "한국어로 변역하기 위해 영어 문장에서 집중적으로 봐야하는 단어는 어느 것인가?" 라는 질문을 인코딩된 영어 문장 정보인 K 한테 물어보게 된다. 그 방법은 이 다음에 소개하도록 하고, 그렇게 얻은 결과인 A 를 V 와 곱하여 그 단어를 집중적으로 보게한다. 그렇게 Attention의 결과물인 O 를 얻는다.
감성 분석 문제¶
꼭 Q, K-V 가 다른 성격을 가진 시퀀스가 아니어도 된다. 세 토큰 모두 하나의 시퀀스를 가르킬 수도 있으며, 이를 Self-Attention 이라고 한다. 예를 들어 감성 분석(Sentiment Analysis) 문제를 예로 들면, 모델은 문장을 읽고 이를 사전에 정의해 놓은 감성 카테고리로 판단하게 되는 데, 이때 Q, K, V 모두 같은 문장을 지정하여 그림 4처럼 Attention 을 사용할 수 있다.

Scaled Dot-Product Attention¶
Attention을 구하는 방법은 사실 다양하지만 Transformer 에서는 제일 기본적인 "Dot Product" 를 사용했으며, 그 수식은 다음과 같으며, 배치크기를 제외한 Q, K, V 의 크기를 표기해서 그림 5 와 같다.

여기서 주의할 점은 \(T_k\) 과 \(T_v\)가 같다는 점이다. 기계 번역을 예로 들면 소스 문장이 K-V 세트이기 때문에 같은 길이의 내용을 담고 있지만 각 토큰이 표현하고 있는 차원만 다를 뿐이다. Q 와 K 의 길이는 다를 수 있지만 차원 \(d_k\) 로 같다. 두 행렬은 행렬의 곱(matrix multiplication)을 통해서 크기가 \((T_q, T_v)\) 인 점수 행렬 A 를 만들어 낸다.
행렬 A 는 스케일링(Scaling), 마스킹(Masking) 후 Softmax 를 통해 확률값을 도출한다. 이 행렬의 뜻은 "문제를 해결하기 위해서 Q 의 토큰이 K 의 어떤 토큰을 가장 많이 참고해야하는가?" 를 뜻한다. 따라서 확률이 높게 부여된 토큰은 Q 의 해당하는 토큰과 연관성이 높다고 할 수 있다. 물론 이 모든 연산은 학습이 가능하도록 DAG(Directed acyclic graph)로 연결되어 있기 때문에 학습 스텝이 진행됨에 따라 풀고자하는 문제에 최적화된 확률을 계속 도출해낸다((Masking 은 차후에 다룬다).
스케일링 작업은 행렬 곱을 구한 A 를 \(\sqrt{d_k}\) 로 나누는데, 그 이유는 다음과 같다. 차원의 크기인 \(d_k\) 가 커질 수록 행렬의 곱의 수치는 점점 커지고 Softmax 수식에 의해서 그 확률 값 또한 커진다. 따라서 Softmax 의 경사(gradient) 값도 굉장히 작아지는데, 이를 막기위해서 \(\frac{1}{\sqrt{d_k}}\) 값을 곱해줘야한다.
왜 \(\sqrt{d_k}\) 를 나눌까? 평균이 0, 표준편차가 1인 랜덤한 값으로 Q 와 K 로 초기화시키고 확률로 표현된 행렬값 A 의 경사를 구해보면 \(d_k\) 가 커짐에 따라서 평균이 0, 분산이 \(d_k\) 를 따르는 분포가 된다. 이러한 시뮬레이션을 다음 코드를 통해 알아 볼 수 있다.
Simulation Code
import torch
import torch.nn as nn
def check_dotproduct_dist(d_k, sampling_size=1, seq_len=1, threshold=1e-10):
"""
to check "https://arxiv.org/abs/1706.03762" Paper page 4, annotation 4
-------------------------------
To illustrate why the dot products get large,
assume that the components of q and k are independent random variables
with mean 0 and variance 1.
Then their dot product has mean 0 and variance d_k
print("*** notice that the gradient of softmax is y(1-y) ***")
for d_k in [10, 100, 1000]:
check_dotproduct_dist(d_k, sampling_size=100000, seq_len=5, threshold=1e-10)
"""
def cal_grad(attn):
y = torch.softmax(attn, dim=2)
return y * (1-y)
q = nn.init.normal_(torch.rand((sampling_size, seq_len, d_k)), mean=0, std=1)
k = nn.init.normal_(torch.rand((sampling_size, seq_len, d_k)), mean=0, std=1)
attn = torch.bmm(q, k.transpose(1, 2))
print(f"size of vector d_k is {d_k}, sampling result, dot product distribution has\n")
print(f" - mean: {attn.mean().item():.4f}, \n - var: {attn.var().item():.4f}")
grad = cal_grad(attn)
g_sum = grad.le(threshold).sum()
g_percent = g_sum.item()/grad.view(-1).size(0)*100
print(f"count of gradients that smaller than threshod({threshold}) is {g_sum}, {g_percent:.2f}%")
attn2 = attn / torch.sqrt(torch.as_tensor(d_k).float())
grad2 = cal_grad(attn2)
g_sum2 = grad2.le(threshold).sum()
g_percent2 = g_sum2.item()/grad2.view(-1).size(0)*100
print(f"after divide by sqrt(d_k), count of gradients that smaller than threshod({threshold}) is {g_sum2}, {g_percent2:.2f}% \n")
print("*** notice that the gradient of softmax is y(1-y) ***")
for d_k in [10, 100, 1000]:
check_dotproduct_dist(d_k, sampling_size=100000, seq_len=5, threshold=1e-10)
시뮬레이션 결과:
*** notice that the gradient of softmax is y(1-y) ***
size of vector d_k is 10, sampling result, dot product distribution has
- mean: -0.0004,
- var: 9.9979
count of gradients that smaller than threshod(1e-10) is 193, 0.01%
after divide by sqrt(d_k), count of gradients that smaller than threshod(1e-10) is 0, 0.00%
size of vector d_k is 100, sampling result, dot product distribution has
- mean: -0.0028,
- var: 99.9868
count of gradients that smaller than threshod(1e-10) is 402283, 16.09%
after divide by sqrt(d_k), count of gradients that smaller than threshod(1e-10) is 0, 0.00%
size of vector d_k is 1000, sampling result, dot product distribution has
- mean: 0.0029,
- var: 999.6312
count of gradients that smaller than threshod(1e-10) is 1737479, 69.50%
after divide by sqrt(d_k), count of gradients that smaller than threshod(1e-10) is 0, 0.00%
해당 모듈(Module) 코드는 Link 에서 확인할 수 있다.
3. Sub Layers¶
Multi-Head Attention¶

첫번째 서브층(SubLayer) Multi-Head Attention 의 구조는 그림 6 과 같다. 연구자들은 \(d_{model}\) 크기의 Q, K, V 를 한 번 수행하는 것보다 \(h\) 개의 각기 다른 선형 투영(linear projection)을 시켜, 크기가 \(d_k\)(Q, K), \(d_v\)(V) 인 텐서를 사용해서 Attention 을 병렬로 수행하는 것이 더 유리한 것을 찾아냈다. 각기 다른 Attention 을 수행한 \(h\) 개의 출력값은 하나로 concatenate 후에 최종 선형결합을 통해 다시 \(d_{model}\) 크기로 돌아오는데 이를 수식으로 표현하면 다음과 같다.
W 는 선형결합을 위한 매겨변수이며 각각의 크기는 다음과 같다.
그렇다면 이렇게 큰 차원의 Q, K, V 를 선형 변환 후에 \(h\) 개의 Attention 을 나눠서 학습하게 했던 이유는 무엇 일까? 논문에서 이해한 것을 정리하면 다음과 같다.
일단 선형 변환된 Q, K, V 를 \(h\) 개로 나눠버리는데, 이는 각 토큰을 표현하고 있던 큰 차원의 뉴런들을 \(h\) 개의 블록으로 나눴다고 할 수 있다. 이렇게 위치가 상이한 각기 다른 표현 부분공간(representation subspaces) 블록들이 교차하면서(jointly) 정보를 얻게 된다. 이 말은 곧 \(h\) 개의 Attention Matrix 가 생기면서 Q 와 K 간의 토큰들이 더 다양한 관점으로 볼 수 있다는 말이다. 만약에 나누지 않았다면 단 하나의 Attention Matrix 를 생성하면서 이러한 효과를 뭉게버림으로, 선형 변환 층(linear projection)은 학습 과정을 반복하면서 최적의 \(h\) 개의 Attention Matrix 를 생성하는 역할을 학습하게 된다.
해당 모듈(Module) 코드는 Link 에서 확인할 수 있다.
Position-wise Feed-Forward Networks¶
또 다른 서브층으로써 완전 연결층(Fully Connect Layer)인 네트워크를 Encoder, Decoder 뒤에 하나씩 추가했다. 이 완전 연결층은 두 개의 선형변환과 ReLU 활성화 함수를 사용했으며 그 수식은 다음과 같다.
아마도 입력 텐서가 각 토큰의 위치별로 차원이 커졌다가 다시 원래 모양으로 줄어들어서 이름이 Position-wise 라고 붙여진 것으로 추정되는데, 차원의 크기가 다음과 같이 변하기 때문이다.
해당 모듈(Module) 코드는 Link 에서 확인할 수 있다.
4. Embeddings¶
Input 과 Output¶
Embedding 층과 Position Encoding 을 설명하기 전에 입출력이 어떻게 구성되어 있는지를 살펴봐야한다. 기계 번역 문제를 다시 예시로 들어보면, 다음과 같이 수치화된 문장들이 있다. 0 은 Padding 토큰으로써 데이터 처리를 위해 설정한 문장의 최대 길이에 맞춰서 넣은 인위적인 토큰이다.
즉, 위 행렬을 해석하면 현재 Input 데이터는 미니배치가 3, 문장의 최대 길이가 4인 데이터, Target 데이터는 미니배치가 3, 문장의 최대 길이가 4인 데이터다. 각 문장의 토큰들에 순서 인덱스를 부여하여 포지션(Position) 데이터를 얻고자하면 다음과 같다. Padding 은 인위적으로 넣은 데이터기 때문에 순서가 없어야 한다.
Decoder 의 경우 이전 타임 스텝(t-1)의 토큰들로 다음 타임 스텝(t)의 토큰을 예측하기 때문에 실질적으로 모델에 입력되는 데이터(trg_input)와 실제 예측해야하는 타겟 데이터(gold)는 다음과 같다. 즉, 예를 들어 1, 2, 3 포지션에 해당하는 타겟 값을 입력으로 주었을때 2, 3, 4 번 포지션에 해당하는 값을 예측하는 것이다.
토큰에 순서 정보인 포지션을 구하는 이유는 무엇일까? 그 해답은 RNN 의 구동원리에 있는데, RNN 을 Cell 단위로 만들면 다음 코드와 같다.
import torch
import torch.nn as nn
# create inputs tensor
batch_size = 2
seq_len = 10
input_dimension = 7
inputs = torch.rand(seq_len, batch_size, input_dimension)
# setting rnn cell
hidden_dimension = 6
rnn_cell = nn.RNNCell(input_size=input_dimension, hidden_size=hidden_dimension)
# RNN Layer
outputs = []
hidden = torch.zeros(batch_size, hidden_dimension)
for i in range(seq_len):
hidden = rnn_cell(inputs[i], hidden)
outputs.append(hidden)
outputs = torch.stack(outputs)
print(outputs.size())
# print: torch.Size([10, 2, 6])
RNN 의 특징 중 하나는 시퀀스 길이에 상관없이 한 스텝씩 처리하기 때문에 아주 긴 시퀀스도 처리를 할 수 있다. 그러나 이러한 특징은 이전 타입스텝의 정보를 다음 타임스텝에게 전달할 수 있지만 병렬 처리가 불가능 하다. 하지만 Transformer 의 목표중 하나는 시퀀스 데이터의 병렬 처리인데, 즉, 한 번에 지정된 길이의 시퀀스를 모두 모델에게 전달하고 Forward 하게 된다. 그렇다면 시퀀스의 각 토큰간 순서 관계 정보를 모델은 어떻게 알아낼 수 있을까? 바로 Position Encoding 을 통해서 각 토큰의 순서 정보를 Embedding 된 벡터와 결합하여 모델로 전달하게 된다.
Embedding¶
임베딩은 분절된 토큰들을 고정된 \(d_{model}\) 차원의 공간으로 표현해주는 방법이다. Decoder 의 출력층에는 선형변환 층과 Softmax 를 섞어서 예측 토큰의 확률을 구하는 기법을 사용했으며, 임베딩된 벡터에 \(\sqrt{d_{model}}\) 를 곱했다.
해당 모듈(Module) 코드는 Link 에서 확인할 수 있다.
Positional Encoding¶
Positional Encoding 은 상대적이거나 절대적인 위치정보를 부여하는 방법이다. 각 Position Encoding 의 차원의 크기는 더할 수 있게 임베딩된 텐서의 차원 크기인 \(d_{model}\)과 같고 수식은 다음과 같다.
결론을 말하자면 각 시퀀스의 순서 인덱서는 PE(Positonal Encoding) 테이블에서 각자의 위치를 조회후에 임베딩된 텐서와 결합하게 된다. pos 는 시퀀스의 위치정보, 예를 들어 텐서의 크기가 \(d_{model}\) = 1024 의 경우, 각 1024의 짝수(2i)에 위치한 값들은 sin 함수를 적용하고, 홀수(2i+1) 에 위치한 값들은 cos 함수를 적용한다. PE 테이블을 그리면 그림 7 과 같은데, 자세히 보시면 각 포지션에 해당하는 1 줄(1024 크기의 벡터)값은 모두 차별화 되어있다.

해당 모듈(Module) 코드는 Link 에서 확인할 수 있다.
5. Models¶
Masking¶
지금까지 미뤄온 Attention 의 마스킹(Masking)을 이야기 해보려 한다. 마스킹이 필요한 이유는 두 가지다.
-
Decoder 의 Self Attention
Decoder 에서는 이전의 타임 스텝(t-1)의 정보를 활용하여 다음 타임 스텝(t)의 정보를 예측하게 되는데 이를 자기회귀(auto-regressive)특성이라고 한다. 이러한 특성을 보존하기 위해서 이전 타임 스텝(t-1)을 입력으로 현재 타임 스텝(t)를 예측하려고 할 때, 다음 타임 스텝(t+1)의 정보를 참조하면 안된다. 따라서 이를 Scaled Dot-Product Attention 에서 마스킹을 통해, 음의 무한대(
-np.inf) 값을 주어서 Softmax 값을 0으로 만들어 준다.예를 들어
그림 8처럼 (검은색이 마스킹 위치) Decoder 의 입력 데이터 최대 길이가 4인 경우, Q 에서 0 번째 토큰은 1 번째 토큰을 예측해야 함으로 Self-Attention 시 K 의 1, 2, 3 번째의 토큰의 관계를 무시해야한다. Q 의 1 번째 토큰을 입력시 2 번째 토큰을 예측하게 되는데, 자기 자신을 포함한 그 이전의 정보를 참조 할 수는 있지만 미래의 2, 3 번째의 정보를 미리 참고하면 안된다.

-
실제 토큰의 길이
앞서 말했듯이 RNN 처럼 recurrance 하지 않기 때문에 최대 입력/출력 길이를 정해야한다. 따라서 실제 문장은 길이가 4인데도 설정한 최대 길이 때문에 그 길이만큼
Padding을 하게 되는데, Attention 계산시Padding은 인위적으로 넣은 토큰이기 때문에 이를 무시해야 한다.예를 들어 Decoder 에 들어가는 타겟 데이터의 최대 길이는 4이지만 실제 토큰의 길이가 3이라면 Attention Matrix 에 해당하는 마스킹은
그림 9와 같다. 여기서는 마지막 토큰이Padding토큰이기 때문에 Self Attention 시 마지막 토큰은 참조하지 않는다. Attention 코드(GitHub 참고) 구현하게 되면 3 번째 행은 Softmax 를 통과시nan값이 된다. 따라서 해당하는 값을 0으로 다시 마스킹하는 과정이 필요하다.

해당 모듈(Module) 코드는 다음과 같다. * Encoder Layer * Decoder Layer * Encoder * Decoder
Transformer Model¶
특이한 점이라면 마지막 예측 토큰을 출력하는 선형 변환 층(projection)을 임베딩 층으로 치환하는 방법이 있는데 이를 논문에서 Linear Weight Sharing이라고 했다. 또한, 문제에 따라서 Encoder층의 임베딩과 Decoder층의 임베딩을 공유 할 수도 있는데 Language Modeling 같은 문제가 그 예시라고 할 수 있다. 이를 논문에서 Embed Weight Sharing이라고 했다.
해당 모듈(Module) 코드는 Link 에서 확인할 수 있다.
6. Loss Function¶
Label Smoothing¶
Discrete한 분포를 예측하는 방법은 주로 Cross Entropy를 많이 사용하지만 논문에서는 Rethinking the inception architecture for computer vision8 논문에서 언급한 Label Smoothing 기법을 활용했다.
예측 확률 분포를 P, 정답/타겟 확률 분포(ground-truth distribution)를 Q라고 하겠다. \(x\) 를 입력으로 예측 확률 질량함수 p(y=k|x) 에서 구한 확률(Softmax)을 타겟 확률 질량함수 q(y=k|x)=1 처럼 만드는 것이 원래의 최종목표다. 이제부터 \(x\)를 생략해서 쓰겠다. Cross Entropy의 수식은 다음과 같다.
Cross Entropy 를 최소화 하는 것은 \(k\) 라벨에 해당하는 log-likelihood 의 기댓값을 \(q(k)\)로 최대화 하는 것과 같다. 그리고 Cross Entropy 는 Softmax 에 사용되는 예측값의 로짓(logit, \(z_k\))에 대해 미분을 구할 수 있는데, 그 미분값은 다음과 같으며 -1 과 1 사이의 치역을 갖는다.
정답 라벨(ground-truth label)이 \(y\)인 예시를 들어봅자. 논문에서는 라벨 \(y\)에 해당하는 로짓(\(z_y\)) 값이 다른 라벨 \(k\)의 로짓(\(z_k\)) 값에 비해 월등히 클 수록 2가지 문제가 생긴다고 한다.
- 오버피팅(over-fitting)이 될 가능성이 있다. 만약에 모델이 전체 확률 분포(모든 라벨)를 학습 시, 일반화(generalize)를 보장할 수 없다.
-
이러한 구조는 제일 큰 로짓 값과 상대적으로 작은 로짓 값의 차이를 점점 더 크게 만들도록 학습한다. 이는 미분 값을 항상 0에 가깝게 만들어 가중치 업데이트가 안된다. 다음 미분의 수식에서 확인 할 수 있듯이, 정답 라벨 \(y\) 의 로짓 값이 높을 수록, 그 확률은 1 에 가까워 경사(gradient)가 0에 가깝다.
\[\begin{aligned} \dfrac{\partial Loss}{\partial z_y} &= -q(z_y)\cdot\frac{1}{p(z_y)} \times p(z_y)\big(1-p(z_y) \big) \\ &= -q(z_y)+q(z_y)p(z_y) \\&= p(z_y) -1 \end{aligned}\]
결론적으로 말하면, 정답 라벨에 대해서 너무 확실한 예측을 내놓는 다는 것이다. 따라서 이러한 효과를 줄이기 위해서 해당 논문에서는 색다른 정답 확률 분포를 이야기 하는데, 기존의 q(k)의 분포는 다음과 같다.
이를 새로운 q'(k)로 치환하게 된다. \(\epsilon\)은 Smoothing을 위한 변수다.
u(k) 의 분포는 훈련데이터와 무관한 분포이며, 보통 u(k) = 1/K인 Uniform Distribution 을 사용한다. q'(k)와 같은 정규화의 한 방법으로 논문에서는 이를 Label-Smoothing Regularization (LSR) 이라고 제시했다.
LSR 의 목적은 원래 목표인 타겟 라벨을 맞추는 목적과 정답 라벨의 로짓(logit) 값이 학습과정에서 과도하게 다른 로짓 값보다 커지는 현상을 방지하는 것이다. 수식을 약간 변형하여 LSR 를 다른 관점에서 볼 수 있다.
LSR 은 기존에 Cross Entropy H(q, p)를 한 쌍의 H(q, p) 와 H(u, p)로 대체한 것이다. Smoothing Factor 인 \(\epsilon\)의 크기의 여부에 따라 정규화의 정도가 달라진다.
Transformer 에서도 해당 방법을 정규화 목적으로 \(K\) 는 타겟 단어장(vocab)의 크기, \(\epsilon\)=0.1 로 사용했다.
해당 모듈(Module) 코드는 Link 에서 확인할 수 있다.
7. Optimizer¶
Learning Rate Variation¶
논문에서는 Adam Optimizer 를 기반으로 다양한 학습률을 적용하여 사용했다. 학습률 변화의 수식은 다음과 같다.
해당 수식에 따르면 처음 warmup_steps 동안 학습률은 가파르게 상승하다가 차후에 천천히 하강하게 된다.

해당 모듈(Module) 코드는 Link 에서 확인할 수 있다.
8. Training Multi30k with Transformer¶
PyTorch의 torchtext에 있는 Multi30k 데이터 세트(영어-독일어 번역)로 테스트 해보았다. 큰 데이터는 아니기 때문에, NVIDIA GTX 1080 ti 로 약 36분 훈련시켰다. 기존의 RNN 으로 훈련시키는 것 보다 월등히 빨랐다. 모델에서 Attention에 대한 그림도 github에 올려두었으니 확인해보길 바란다.
