Feature Visualization
Feature Visualization1 논문을 보면서 정리한다는게 통째로 번역을 해버렸다(물론 부족한 번역이지만...). 하지만 배운 점이 많았는데 그중에 하나로 attribution 방법과 상당히 다른 방향을 지향한다는 점이다. 링크된 페이지를 방문하면 interactive하게 결과물을 보면서 감상할 수 있다.
기회가 되면 다른 논문인 The Building Blocks of Interpretability2도 한번 쭉 보면서 정리해보겠다.
Introduction¶
인간이 신경망을 해석 할 수 있어야한다는 인식이 점차 커지고 있는 가운데 neural network interpretability 분야가 점점 발전하고 있다. 특히 비전분야에서 feature visualization 와 attribution 두 가지 방법이 많이 연구되고 있다.

Feature Visualization by Optimization¶
Reference: Visualizing higher-layer features of a deep network3
신경망은 대체로 입력에 대해 미분가능하다. 따라서 모델의 특정 행동(내부 뉴런값 혹은 마지막 층의 출력값등)의 원인이 입력의 어떤 부분인지 보고 싶다면 도함수를 사용해 점진적으로 목표에 다다르도록 조정 할 수 있다.
Optimization Objectives¶

목적에 따라서 전혀 다른 해석을 가질 수 있다.
- 특정 위치의 한 뉴런 혹은 전체 채널: Neuron, Channel
- 특정 층: Layer/DeepDream
- 특정 클래스: Class Logits, Class Probability
Why visualize by optimization?¶
optimization 기법은 모델이 정말로 무엇을 보고 있는지 알 수 있는 강력한 방법이다. 왜냐면 모델의 특정 행동을 일이키는 원인과 단순히 연관된(correlate)것을 분리할 수 있기 때문이다.
또한 optimization 기법은 유연하다는 장점이 있다. 예를 들어서 뉴런들어 어떻게 결합되어 표현(jointly represent)되는지 보고 싶다면, 추가 뉴런이 활성화되기 위해 특정한 예가 어떻게 달라져야 하는지 알아 볼 수 있다. 이런 유연함은 네트워크 피처가 어떻게 훈련과정에서 발전하는지를 보여주는 시각화에 도움이 된다.
장점도 있는 반면 어려운 점들도 있다. 다음 섹션에서는 다양한 시각화 기법들을 이해해본다.
Diversity¶
optimization을 통해 예시를 만들때 주의해야할 점은 전체 그림을 생성하는지의 여부다. 왜냐면 이런 특별한 예시들은 피처 표현의 한 단면만 보여주기 때문에, 인지의 오해를 불러 일으킬 수 있다.
데이터 세트로부터 예시를 생성하면 각기 다른 방면으로 활성화된 뉴런의 전체 스펙트럼을 볼 수 있다.
아래 그림을 예로 들어 본다. Positive optimized는 특정 뉴런 A을 최대화하게 optimization 과정을 거친 이미지라면, Maximum activation example은 데이터 세트 이미지를 모델에게 입력으로 넣어서, 우리가 optimization을 진행한 뉴런 A을 제일 크게 만드는 이미지만 골라내는 것이다.
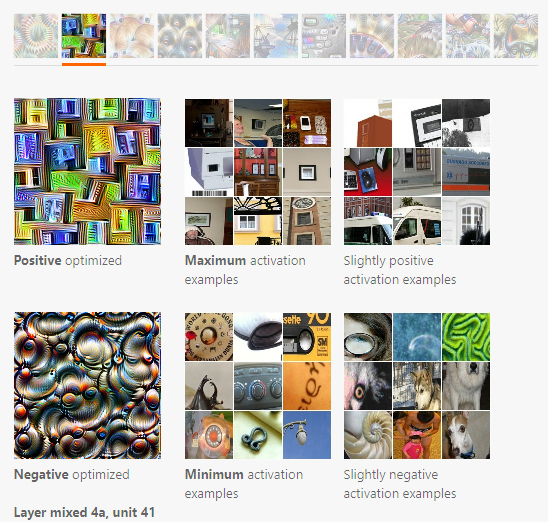
Achieving Diversity with Optimization¶
- Understanding Intra-Class Knowledge Inside CNN(Wei et al. 2015)4 에서는 전체 훈련데이터세트의 활성화 값을 기록하면서, 이들을 클러스터링하고, 클러스터링된 중심값(cluster centroids)으로 부터 optimization하면서, 클래스 간("intra-class")의 다양성을 증명했다.
- Multifaceted feature visualization: Uncovering the different types of features learned by each neuron in deep neural networks(Nguyen et al. 2016)5 에서는 하나의 뉴런이 아닌 다양한 방면을 표현하는 피처로부터 optimization을 시작함으로써 다양성을 증명한다.
- 최근 연구인 Plug & play generative networks: Conditional iterative generation of images in latent space(Nguyen et al. 2017)6 에서는 generative model를 결합해서 다양한 예시를 샘플링한다. generative model 접근법이 꽤 잘 되는 편인데, learned priors에서 이를 더 다루기로 한다.
diversity를 이루는 방법은 "diversity" 항을 목적함수에 추가함으로써 심플하게 달성할 수 있다. diversity 항은 다양하게 구성할 수 있으며, 그 예시로 다른 클래스 데이터와의 cosine similarity를 패널티로 부여하여 달성 할 수 있다. 다른 예로는 style transfer7에서 보여준 피처로하여금 다른 스타일을 강제하는 방법이 있다.
add 'diversity' term?

artistic style transfer로부터 영감을 얻음. Gram matrix \(G\)의 채널들로부터 계산을 시작한다. \(G_{i,j}\)는 flatten된 필터 \(i\)와 필터 \(j\)의 dot product다.
\(G_{i,j} = \sum_{x,y} \text{layer}_n\text{[x, y, i]} \cdot \text{layer}_n\text{[x, y, j]}\)
여기서 diversity term을 계산할 수 있다. the negative pairwise cosine similarity of pairs of visualizations.
\(C_{\text{diversity}} = - \sum_{a} \sum_{b\neq a} \dfrac{\text{vec}(G_a) \cdot \text{vec}(G_b)}{\Vert\text{vec}(G_a)\Vert \Vert\text{vec}(G_b)\Vert}\)
이 후에 \(C_{\text{diversity}}\)를 optimization 목적함수에 패널티 항으로 추가하여 학습한다.
낮은 차원의 뉴런들에서 diversity 항은 표현된 피처(feature representations)의 다양한 방면을 보여줄 수 있다.

다양한 피처 시각화는 무엇이 뉴런을 활성화하는지 자세히 들여다 볼 수 있게 해준다. 특히 데이터 세트로 본다면, 어떤 입력이 뉴런을 활성화 시키는지 더 다양하게 관찰하고 예측 할 수 있다. 예를 들어 다음 한 장의 optimization결과를 살펴본다.

위 그림을 개의 머리 부분이 뉴런을 활성화 시킨 것으로 보인다. 그림의 일부를 보자면 개의 눈과 아래로 향하는 곡선으로 추측할 수 있다. 그러나 어떤 부분에서는 눈이 포함 안될 때도 있고, 아래로 향하는 곡선뿐만 아니라 위로 향하는 곡선도 있다. 따라서 이 뉴런이 활성화하는 것이 주로 모피 텍스처에 관한 것으로 가설을 세울 수 있다.

이 가설을 데이터 세트 예제를 통해 생성한 결과로 비교해 보면, 대체로 가설이 맞는 것으로 나타난다. 개의 털과 비슷한 질감의 색상과 텍스처를 활성화 했다는 점을 주목해야한다.
다양함의 효과는 더 높은 층의 뉴런에서 두드러진다. 뉴런을 통해 다양한 물체 종류를 시뮬레이션 할 수 있다. 예를 들어, 다음 그림과 같이 다양한 종류의 볼들이 생성된 것을 볼 수 있다.

이러한 접근법에도 단점이 있다. 예시를 다르게 만드려는 강압적인 방법 때문에 오히려 연관이 없는 물체가 생성 될 수도 있다. 추가로 optimization을 통해서 예시를 다르게 생성하는 것은 부자연스러운 방법이다. 예를 들어, 위 그림의 경우, 누군가는 다른 공들은 제외하고 깨끗한 축구공의 예시를 보고 싶었을 것이다. 데이터 세트에 기반한 기법들(Wei et al. 2015)은 이와 다르게 조금 더 자연스럽게 피처를 분리할 수 있지만, 각기 다른 데이터들이 어떻게 모델에서 동작하는 지를 이해하는 것에 크게 도움이 안될 수 있다.
또 다른 근본적인 문제가 있다면, 다양함은 일관된 예시를 보여줄 수도 있지만 그렇지 않을 수 도 있다는 점이다. 아래 예시는 두 동물의 얼굴 그리고 차체의 결과다. 이러한 결과들로부터 우리는 뉴럴넷을 이해하는데 있어서, 하나의 뉴런이 꼭 정확한 의미론적(semantic) 단위는 아니라는 것을 알 수 있다.

Interaction between Neurons¶
만약에 뉴런이 뉴럴넷을 이해하는데 적절하지 않은 방법이라면, 도대체 무엇이 적절한 방법일까? 실제로 뉴럴넷에서는 여러 뉴런의 조합으로 이미지를 표현한다. 이에 도움이 되는 해석방법은 지리적(geometrically)으로 조합하는 것이다.
예를 들어 활성화 공간(activation space)이라는 것을 정의해 보자, 그렇다면 개별 활성화된 뉴런은 활성화 공간의 기저 벡터(basis vectors)로 생각할 수 있다. 반대로, 활성화된 뉴런들의 조합들이 곧 활성화 공간이 된다.
선형 대수에서 기저(basis)란?
https://ko.wikipedia.org/wiki/기저_(선형대수학)
선형대수학에서, 어떤 벡터 공간의 기저(基底, 영어: basis)는 그 벡터 공간을 선형생성하는 선형독립인 벡터들이다. 달리 말해, 벡터 공간의 임의의 벡터에게 선형결합으로서 유일한 표현을 부여하는 벡터들이다.
이러한 프레임은 "활성화 공간의 벡터"로서 "뉴런"과 "뉴런의 조합"개념을 통합한다. 그러면 다음과 같은 질문을 할 수 있다. "특정 방향을 가지는 기저 벡터들이 다른 방향을 가지는 기저 벡터들보다 더 나은 해석가능함을 나타낼 수 있을까?"
Intriguing properties of neural networks(Szegedy et al. 2014)8에서 저자들은 랜덤한 방향도 충분히 기저 벡터들의 방향만큼 의미가 있다는 것을 주장했다.
Intriguing properties of neural networks
Reference: https://3ffr3s.github.io/2020-02-10-Intriguing_properties_of_neural_networks/
이전 연구에서는 이미지 데이터 집합 \(I\)에 속한 이미지 \(x\)가 주어졌을 때, 단일 피처의 activation을 최대화하는 입력 \(x^{'}\)을 찾았다. \(e_i\)는 \(i\)번째 hidden unit에 관련된 natural basis vector를 뜻한다. 예: \(e_i = 1 \text{ if i-th neuron else } 0\)
하지만 저자들은 랜덤한 벡터 \(v \in \Bbb{R}^{n}\) 로 해도 비슷한 해석이 가능하다는 것을 밝혀냈다.
Mnist에 대한 실험 결과:

ImageNet에 대한 실험결과:

여러 분석을 통해 뉴럴넷 \(\phi(x)\)의 특성을 살펴보는데 natural basis vector가 random vector와 큰 차이가 없다는 것을 뜻한다. 입력 분포의 특정 부분 집합에 대해서 불변성(invariance)을 띄는 \(\phi\)의 능력을 설명할 수 있지만, 나머지 도메인에 대해서 \(\phi\)의 행동을 설명 할 수가 없다.
Network Dissection: Quantifying Interpretability of Deep Visual Representations(Zhou et al.)9에서는 랜덤한 방향보다 basis vector의 방향이 더 해석가능하다고 밝혔다.
우리의 실험에서는 두 가지 주장에 대체로 일치한다. 랜덤한 방향은 어느 때에는 더 해석가능하지만, basis 방향보다는 약간의 낮은 수치를 기록하고 있다.
Dataset examples and optimized examples of random directions:

우리는 활성화 공간에서 뉴런에 대해 약간의 산수를 통해 조금 더 흥미로운 방향을 정의할 수 있다. 예를 들어, "검정과 하양"을 "모자이크" 뉴런에 더하면, 검정고 하얀 모자이크를 얻을 수 있었다. 마치 Word2Vec의 의미론적 단어 임베딩과 비슷하다.
Jointly optimizing two neurons:

위 그림의 예시는 뉴런들이 조건부 결합으로 표현된 이미지다. 이 둘 사이에 보간법을 적용해 뉴런들의 상호작용을 더 잘 이해하게 만들 수있다. 생성 모델(generative models)에서 latent space에 보간법을 적용하는 것과 비슷하다.
생성모델에서 latent space애 보간법 적용하는 방법
간단히 0.1만큼 선형 보간법을 적용한다면 다음과 같다.
import numpy as np
def interpolate_points(p1, p2, n_steps=10):
"""
p1, p2: shape of (hidden_dim) vector
"""
# interpolate ratios between the points
ratios = np.linspace(0, 1, num=n_steps)
# linear interpolate vectors
vectors = list()
for ratio in ratios:
v = (1.0 - ratio) * p1 + ratio * p2
vectors.append(v)
return np.array(vectors)
정확히 말하자면, 전체 optimization의 목적은 개별 채널의 목적함수의 선형 보간과 같다. 보간법을 더 잘 하기 위해서, 낮은 활성화 층과 비슷하도록 작은 alignment 목표를 추가한다. 더 쉽게 optimization을 달성하기 위해서, 분리되고 공유된 이미지의 매개변수 조합을 사용했다(랜덤하게 주어도 되지만).

이 부분은 뉴런들이 어떻게 상호작용하는지 알아가는 시작 단계일 뿐이다. 우리도 어떻게 의미있는 방향을 선택하는지 아니면 실제로 의미가 있는 방향이 존재하는 지를 아직 모르겠다. 방향을 찾는 것과 별개로 방향들간에 서로 어떻게 작용하지에 대한 의문도 있다.
The Enemy of Feature Visualization¶
불행하게도, 단순히 최적화를 한다고해서 피처를 시각화 할 수 없다. 단순 최적화를 하면 어떤 착시 현상 - noise로 가득차고, 무의미한 고주파 패턴(high-frequency patterns)만을 얻을 것이다.
Optimization results with noise:
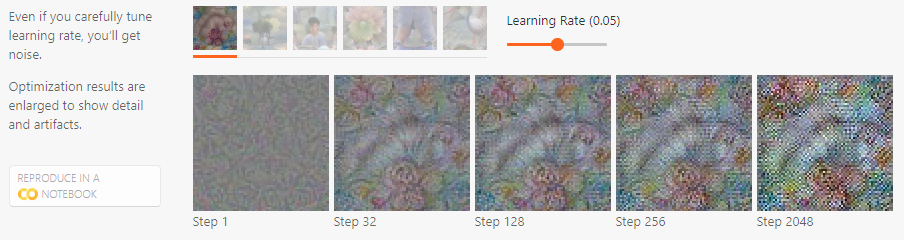
이는 실제 생활에서 일어나지 않을 법한 패턴이다. 만약에 충분이 오랬동안 최적화를 진행한다면, 일부 뉴런이 특출나게 어떤 것을 탐지해내지만, 이미지는 고주파 패턴으로 도배될 것이다. 이러한 패턴들은 Intriguing properties of neural networks(Szegedy et al. 2014)10에서 언급한 적대적 예시의 현상(phenomenon of adversarial examples)으로 보인다.
왜 이런 고주파 패턴 현상이 발생하는지 100% 이해할 수는 없지만, strided convolutions 과 pooling 연산에서 이러한 현상을 야기시킨다는 것을 발견할 수 있었다(Deconvolution and checkerboard artifacts11 글 참고 - up sampling시 resize-convolution 활용: interpolation 후에 Conv Layer 통과).
Reason why causes the hight frequency patterns:
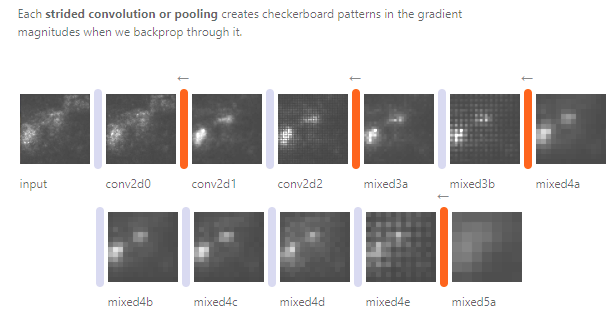
고주파 패턴을 통해 우리는 최적화 기반의 시각화에서 제약으로부터 자유로울수록 매력적이지만, 이는 양날의 검이기도 하다는 것을 알 수 있다. 아무런 제약이 없다면 적대적 예시를 결과로 얻을 것이다.
The Spectrum of Regularization¶
고주파 노이즈를 다루는 것이 곧 이 분야에서 주요 과제가 되었다. 유용한 시각화 결과를 얻기 위해서, 학습된 사전 분포(prior), 정규항(regularizer)이나 제약(constraint)등이 추가되어야 한다.
정규화(regularization)는 최근 피처 시각화 연구에서 확인 할 수 있는 주요 포인트다. 이를 하나의 스펙트럼으로 나눌 수 있을 것이다. 극단적으로 아예 정규화를 하지 않으면, 적대적 예시를 얻고, 너무 강한 정규화를 하게 되면 오해를 부르는 연관성을 야기할 수 있다.
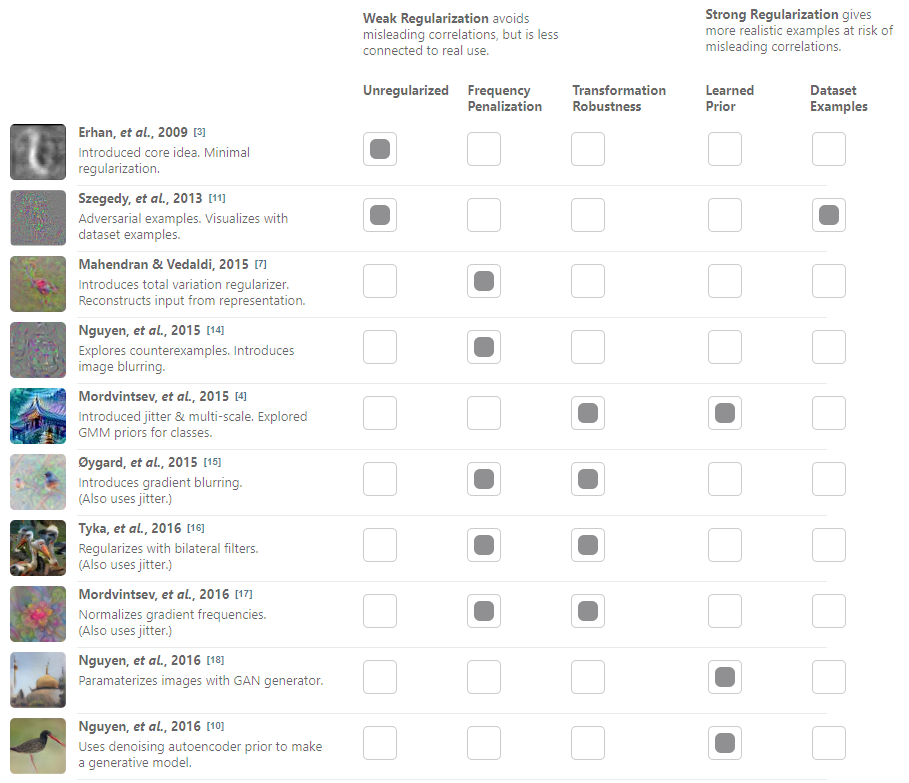
Three Families of Regularization¶
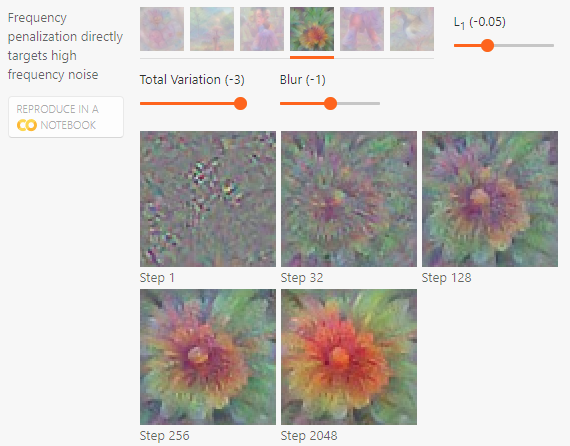
Frequency penalization¶
Frequency penalization는 고주파 노이즈를 직접 없에는 것을 목표로 한다. 명시적으로 근접 픽셀(total variation, Mahendran, Vedaldi, 201412)에 패널티를 부여하거나, 암묵적으로 이미지를 각 최적화 스텝마다 블러 처리를 하는 방법(Nguyen et al. 201413)등이 있다. 안타깝게도 이러한 접근법들은 노이즈가 더해진 엣지같은 높은 주파수를 가지는 피처를 억제한다(즉, 엣지를 없엔다). 이는 bilateral filter를 활용하면 약간 해소할 수 있다(M. Tyka. 201614).
블러 처리에 대한 주석
푸리에 공간에서 블러 처리를 한다면, 스케일링된 L2 정규항을 목적함수에 추가하는 것과 같다. 즉, 주파수에 기반해 각 푸리에 요소에 패널티를 부여하는 것과 같다.
If we think about blurring in Fourier space, it is equivalent to adding a scaled L2 penalty to the objective, penalizing each Fourier-component based on its frequency.
특정 연구(A. Øygard. 201515, A. Mordvintsev. 201616)에서는 시각화에서 특정 결과로 모으기 전에, 위에서 서술한 기술을 사용해 경사에서 높은 주파수를 제거하는 용도로 사용한다. 이는 약간 비슷하면서도 본질적으로 다른 면이 있는데 Preconditioning and Parameterization 파트에서 설명한다.
아래 그림에서 높은 패널티를 줄 수록 고주파 패턴이 사라지고 선명해지는 경향이 있다.
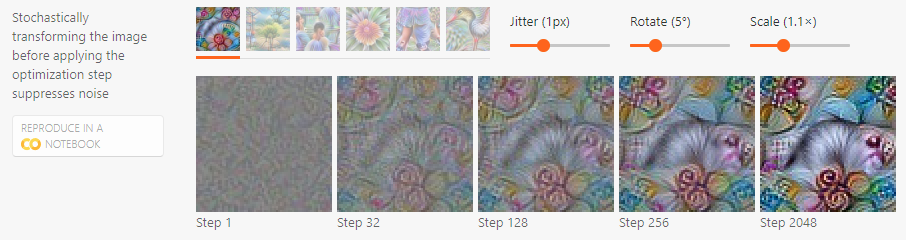
Transformation robustness¶
Transformation robustness는 약간의 변형이 있어도 계속 최적화 타겟을 활성화 시키는 예시을 찾는 것을 목표로 한다. Inceptionism: Going deeper into neural networks(Google Research Blog. 2015)17 에서 말하길 아주 작은 값이라도 이미지에서는 큰 효과를 가져온다. 특히, 높은 주파수가 결합된 일반적인 정규항에서 더 효과적이다(A. Øygard. 201515, A. Mordvintsev. 201616). 구체적으로 최적화 스텝을 진행하기 전에 확률적으로 이미지를 지터링(jitter), 회전(rotate) 또는 스케일링(scale) 한다.
Stochastically transforming the image:
Learned priors¶
이전에 이야기한 정규화항은 예제를 합리적으로 유지하기 위해 매우 간단하고 휴리스틱한 방법을 사용했다. 자연스럽데 다음 단계로 실제 데이터로부터 모델을 학습하고 이를 적용하는 것이다. 강력한 모델을 사용하면, 데이터 세트에서 검색하는 것과 비슷해진다. 이러한 접근법은 가장 사실적인 시각화를 제공하지만, 어떤 것이 모델로부터 시각화 되었고, 어떤 것이 사전 분포로부터 온것인지 모르는 단점이 있다.
잠재 공간(latent space)으로 부터 예시를 매핑하는 생성기(generator)를 학습하는 것이 하나의 방법이다. GAN, VAE와 같은 모델을 학습하고 잠재공간을 최적화 하는 방법이다(Nguyen et al. 201618). 다른 접근 법으로는 확률의 경사를 얻을 수 있는 사전 분포를 학습하는 것이다. 이를 이용하면 목적에 따라 사전 분포를 조건부로 최적화 할 수 있다(Nguyen et al. 201619, Google Research Blog. 201517). 하나는 특정 클래스의 확률값과 사전 분포를 최적화하고, 다른 하나는 특정 클래스를 조건부로 생성 모델에서 데이터를 복구하는 것이다. 마지막으로 Understanding Intra-Class Knowledge Inside CNN(Wei et al. 20154) 에서는 생성 모델의 사전 분포를 대략 추정한다. 적어도 칼러 분포에서, 출력 이미지 패치들과 근처 패치들의 거리에 패널티를 부여하는 방법을 사용하는데, 여기서 근처 패치들은 훈련 데이터에서 수집한 이미지 패치 데이터베이스에서 검색하는 방식이다.
Preconditioning and Parameterization¶
이전 섹션에서 특정 방법들은 고주파 패턴을 시각화 자체에서 줄이는게 아니라 경사에 적용한다고 했었다. 이러한 방법이 정규화항(regularizer)인지는 명확하지 않다. 높은 주파수를 억제하나, 경사에서 이를 계속 보낼 경우 높은 주파수의 형성을 허용하게 된다. 만약에 정규화항이 아니라면, 경사의 변화는 어떤 역할을 하는 것일까?
경사를 변화시키는 것은 꽤나 강력한 도구이며, optimization에서 "preconditioning"이라고 부르며, 같은 목적함수를 가장 가파른 경사로 최적화 하는데, 다른 파라미티 공간과 거리 조건 하에서 최적화를 한다고 생각할 수 있다. 경사를 얼마나 가파르게 변화하거나, 해당 방향으로 얼마나 빠르게 변화를 줘도, 최소가 되는 지점은 변함이 없다. local minima가 많아도, 경사를 수축/확장하면서 벗어날 수 있다. 따라서 적절한 preconditioning은 최적화 문제를 조금 더 쉽게 만들어 준다.
그러면 어떤 조건이 좋을까? 먼저 데이터와 연관을 줄이는 방향(decorrelated and whitened)으로 시도 해볼 수 있다. 이미지의 경우, 같은 에너지를 가지도록 주파를 스케일링하는 Fourier basis로 경사 하강법을 실행하는 것이다.
다음 그림을 보면 거리 조절 방법에 따라서 경사의 방향이 달라진다. \(L^2\) 정규화는 \(L^{\infty}\) 와 decorrelated space와 확연한 차이를 보인다.
Three directions of steepest descent under different notions of distance:

위에서 서술한 모든 방향들은 다 유효한 경사 방향이지만, 결과물을 보면 근본적으로 다르다. decorrelated space로 최적화시, 높은 주파수를 줄일 수 있으며, \(L^{\infty}\) 방법은 오히려 반대로 이를 증가시킨다.
decorrelated 경사 방향을 사용하면 꽤나 다른 시각화 결과를 얻을 수 있다. 이는 hyperparameter를 조절해야하기 때문에 공평한 비교가 힘들지만, 시각화 결과는 훨씬 더 좋으며, 더 빠르게 얻을 수 있다.
Combining the preconditioning and transformation robustness:
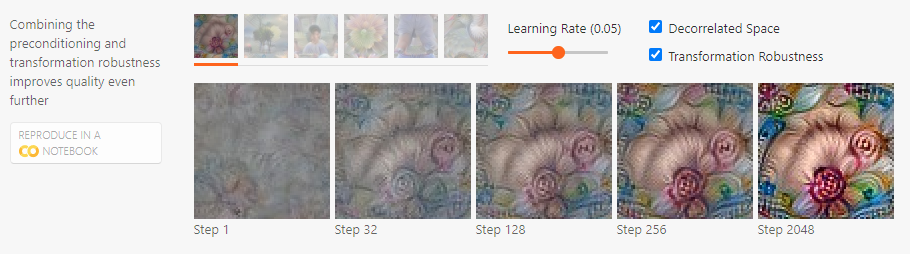
preconditioner가 단순 최적화를 가속 시키는 것인지? 즉, 같은 조건에 평범한 경사를 사용하여 오랜 시간 기다리면, preconditioner을 사용한 것과 같은 결과를 얻을지? 정규화를 함으로써 local minima를 피할 수 있는 것인지? 이는 아직 확실하게 말하기 어렵다. 한편으로 만약에 충분히 오랜 스텝동안 경사하강법을 진행한다면, 느리지만 결국에 수렴하게 된다. 또 다른 한편으로 정규화를 하지 않으면 preconditioner가 높은 주파스 패턴을 줄여준다.
Conclusion¶
뉴런 시각화는 지난 몇년 동안 많은 발전을 이뤘다. 우리는 강력한 시각화를 만들 수 있는 원칙적인 방법을 개발했다. 그리고 여러 가지 중요한 과제를 계획하고 해결 방법을 찾았습니다.
신경망을 해석가능하게 만들기 위해, 피처 시각화는 가장 유망하고 발전된 연구 방향 중 하나로 눈에 띈다. 피처 시각화 자체로는 완벽한 이해를 얻을 수 없다. 우리는 이를 다른 툴과 함께 사용하여, 인간이 시스템을 이해하기 위한 근본 요소중 하나로 보고있다.
피처 시각화에는 아직 많은 해야할 일이 남아 있다. 뉴런의 상호작용을 이해하기, 활성화된 신경망을 이애하기 위해 가장 의미가 유닛을 찾기, 그리고 피처를 다방면으로 살펴보는 문제들이 바로 앞으로 해결해야할 문제들이다.
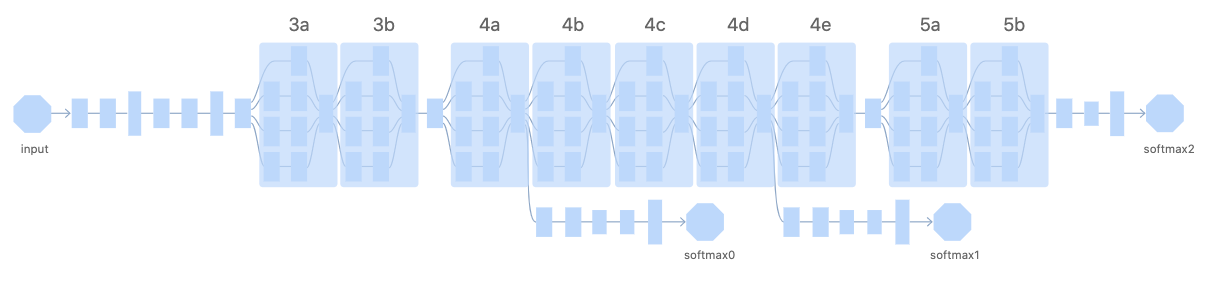
Appendix: Inception Module¶
Feature Visualization - Appendix
Inception 모델에 대한 Layer 번호 설명:
-
Understanding Intra-Class Knowledge Inside CNN(Wei et al. 2015) ↩↩
-
Multifaceted feature visualization: Uncovering the different types of features learned by each neuron in deep neural networks(Nguyen et al. 2016) ↩
-
Plug & play generative networks: Conditional iterative generation of images in latent space(Nguyen et al. 2017) ↩
-
Intriguing properties of neural networks(Szegedy et al. 2014) ↩
-
Network Dissection: Quantifying Interpretability of Deep Visual Representations(Zhou et al.) ↩
-
Intriguing properties of neural networks(Szegedy et al. 2014) ↩
-
Understanding deep image representations by inverting them(Mahendran, Vedaldi, 2014) ↩
-
Deep neural networks are easily fooled: High confidence predictions for unrecognizable images(Nguyen et al. 2014) ↩
-
Inceptionism: Going deeper into neural networks(Google Research Blog. 2015) ↩↩
-
Synthesizing the preferred inputs for neurons in neural networks via deep generator networks(Nguyen et al. 2016) ↩
-
Plug & play generative networks: Conditional iterative generation of images in latent space(Nguyen et al. 2016) ↩