NBDT: Neural-Backed Decision Trees

Abstract¶
금융, 의료 분야의 머신러닝은 정확도뿐만 아니라 납득이 가는 예측(justifiable predictions)이 필요할 때가 많다. 의사결정 나무와 딥러닝을 결합하는 시도는 많았으나, interpretability와 accuracy중 한쪽을 희생해야 하는 trade-off가 항상 있었다. 이 논문에서는 이 둘을 함께 향상하는 Neural-Backed Decision Trees(NBDTs)1를 제안한다. NBDTs는 네트워크의 마지막 linear classifier를 미분 가능한 의사결정 나무 시퀀스와 대체 손실(Surrogate Loss)로 대체한다. 이런 과정이 더 높은 레벨의 개념을 학습하고 불확실한 결정에 대한 의존도를 완화한다. 이로써 CIFAR, ImageNet 에서 높거나 비슷한 정확도를 달성했고, 한 번도 보지 못한 데이터에서 좋은 성능을 달성했다(최대 16% 향상). 그리고 제안한 surrogate loss가 2%의 정확도를 더 향상했다. 또한, 모델의 실수와 데이터 세트 디버깅을 도움으로써 신뢰성에서 향상을 도모했다.
1. Introduction¶
논문 참고
2. Related works¶
논문 참고
- Saliency maps
- Transfer to Explainable Models
- Hybrid Models
- Hierarchical Classification
3. Methods¶
Neural-Backed Decision Trees(NBDTs)는 네트워크의 마지막 linear 층을 의사결정 나무(Decision Trees)로 대체한다. 다른 전통적인 의사결정 나무와 달리, (Sec 3.1) 추론 시에는 path probabilities2를 사용해서 불확실한 중간 결정을 줄인다. 이를 통해, 학습된 모델의 가중치로부터 계층(hierarchy)을 만들어(Sec 3.2, 3.3) 과적합을 피한다. 그리고 훈련은 계층적 손실(Sec 3.4)을 사용해서 높은 레벨의 결정을 학습할 수 있게 한다.
3.1 Inference¶
네트워크의 뼈대는 마지막 linear 층을 제외한 네트워크로 유지하고, fully-connected 층을 유사 의사결정 나무(oblique decision tree, 이하 "유사 트리")로 실행한다. 하지만 전통적인 트리는 두 가지 문제점: (a) 초기 단계에서 한 번 잘못 분류하면 계속 틀린다는 점, (b) 정확도가 하락(최대 11%)이 되기 때문에 변형된 결정 규칙을 정한다(Fig 1, B).

-
유사 트리의 규칙 weights를 네트워크의 weights로 초기화
유사 트리는 각 노드에서 판별 평면(hyperplane) 으로 binary 결정만 내린다. 각 노드에는 weight 벡터 \(n_i\)와 연관 있는데, \(K\) 개의 클래스인 리프 노드(leaf nodes)는 fully-connected 층의 가중치 \(W \in \Bbb{R}^{D \times K}\) 의 행 벡터 \(n_i = w_k, \text{where } i = k \in [1, K]\) 로 초기화한다. 나머지 내부 노드들은( \(i = k \in [K+1, N]\) ) \(i\) 의 서브 트리에 속한 모든 노드들( \(k \in L(i)\) )의 평균으로 설정된다.
\[n_i = \sum_{k\in L(i)} \dfrac{w_k}{\vert L(i) \vert}\] -
노드의 확률 계산
자식 노드의 확률은 softmax inner products로 주어진다. 각 샘플 \(x\)와 노드 \(i\) 대해서 자식 노드 \(j\in C(i)\)의 확률은 다음과 같다.
\[p(j \vert i) = \text{softmax}(\langle \vec{n}_i, x \rangle )_{j \in C(i)}\] -
path probabilities로 리프 노드를 선택
Deng et al. 20123의 논문에서 영감을 받았다. 클래스가 \(k\)인 리프노드의 확률은 다음과 같다.
\[p(k) = \prod_{i \in P_k} p(C_k(i) \vert i)\]- 클래스 \(k\) 인 리프노드 루트로부터 시작된 패스 \(P_k\)
- \(p(C_k(i) \vert i)\)는 패스상 존재하는 각 노드 \(i \in P_k\)에서 다음 노드 패스 \(C_k(i) \in P_k \cup C(i)\)를 탐색(traverse)하는 확률이다.
Soft Inference 단계에서는 마지막 클래스 예측 \(\hat{k}\)는 다음과 같이 정해진다.
장점은 (a) 아키텍쳐가 변하지 않았기 때문에 평소처럼 fully-connected 층 혹은 유사 트리를 유연하게 선택할 수 있다. (b) 다른 트리계열 방법들과 달리, 초기 단계에서 충분한 불확실성이 많은 잘못된 Path에 진입하는 경우에서 회복할 수 있다.
3.2 Building Induced Hierarchies¶
기존의 전통적 의사결정 나무를 만드는 방식은 (a) 데이터 의존성이 강한(e.g. information gain) 방법 혹은 (b) WordNet과 같이 사람이 이미 만든 계층이 있다. 그러나 전자는 과적합의 문제가 있고, 후자는 유사성보다는 개념을 더 중요시한다. 예를 들어, WordNet에서 animal에 속하는 것 중 bird는 cat과 더 가깝고, plane과는 멀어야 한다. 그러나 sky에 존재하는 것으로 가면 bird는 cat과 멀고, plane과 가까워야 한다.
여기서 미리학습된 모델에서 가중치가 필요하다. 마지막 fully-connected layer의 가중치 매트릭스 \(W\)의 행 벡터 \(w_k : k \in [1, K]\)를 가지고 노말라이즈된 클래스 representations \(w_k / \Vert w_k \Vert_2\)을 agglomerative clustering4한다.
Sec 3.1에서 언급 했듯이, 각 리프 노드들의 가중치 \(w_k \in W\)와 리프 노드의 평균인 내부 노드의 가중치 \(n_i\) 로 Agglomerative clustering를 수행해서, Figure 2 처럼 각 노드들이 묶인다.
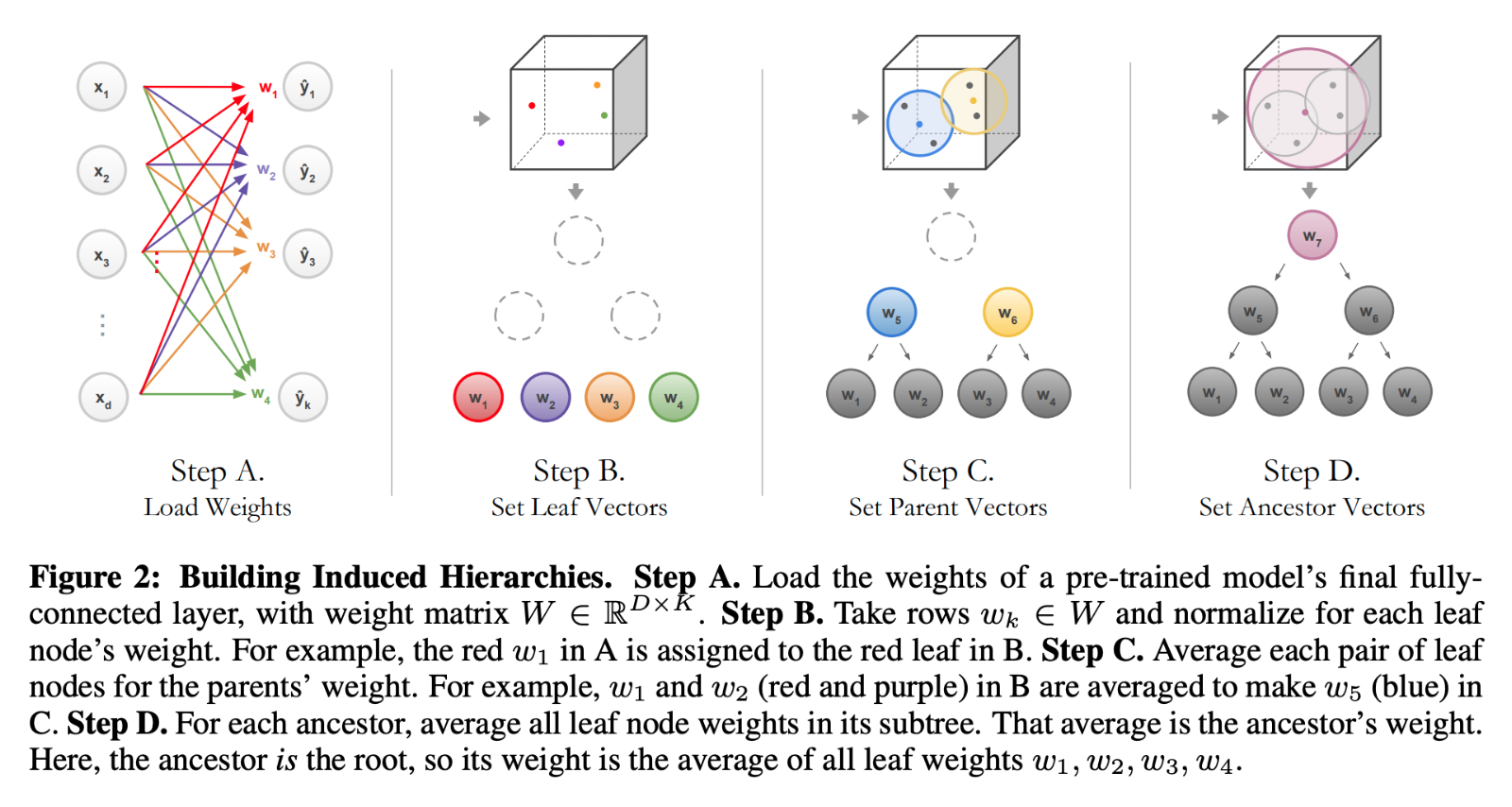
3.3 Labeling Decision Nodes with WordNet¶
WordNet은 영어 명사로 구성된 계층이다. 명사를 노드에 할당하기 위해서 서브 트리에서 가장 가까운 공통된 조상(ancestor)을 참고한다. 예를 들어, 개와 고양이 경우, WordNet에서 모든 조상을 찾는다. "Mammal", "Animal", "Living Thing"이 있는데, 제일 가까운 "Mammal"을 선택한다. 내부 노드도 이처럼 선택한다.
Example
예시, ancestors에서 carnivore(육식동물)이 가장 뒤에 가까운 공통요인이기 때문에 해당 단어를 parent node의 의미로 설정한다.
from nltk.corpus import wordnet
def find_common(l1, l2):
res = []
for x in l1:
if x in l2:
res.append(x)
return res
cat = wordnet.synsets('cat')[0]
dog = wordnet.synsets('dog')[0]
p_cats = cat.hypernym_paths()
p_dogs = dog.hypernym_paths()
all_res = []
while (len(p_cats) > 0) or (len(p_dogs) > 0):
if len(p_cats) > 0:
p_cat = p_cats.pop(0)
if len(p_dogs) > 0:
p_dog = p_dogs.pop(0)
res = find_common(p_cat, p_dog)
all_res.append(res)
for i, ps in enumerate(all_res):
print(f'Path {i}')
for j, x in enumerate(reversed(ps)):
print(x)
print()
# Path 0
# Synset('carnivore.n.01')
# Synset('placental.n.01')
# Synset('mammal.n.01')
# Synset('vertebrate.n.01')
# Synset('chordate.n.01')
# Synset('animal.n.01')
# Synset('organism.n.01')
# Synset('living_thing.n.01')
# Synset('whole.n.02')
# Synset('object.n.01')
# Synset('physical_entity.n.01')
# Synset('entity.n.01')
# Path 1
# Synset('animal.n.01')
# Synset('organism.n.01')
# Synset('living_thing.n.01')
# Synset('whole.n.02')
# Synset('object.n.01')
# Synset('physical_entity.n.01')
# Synset('entity.n.01')
3.4 Fine-Tuning with Tree Supervision Loss¶
Tree supervision Loss를 추가했는데, 이는 클래스 path probabilities의 Cross Entropy를 구한 것이다.
여기서 \(\beta_t\)와 \(w_t\)는 \(t\)번째 epoch에 따라 다른 가중치를 가진다.
Tree supervision Loss인 \(\mathcal{L}_{\text{soft}}\)는 미리 정의된 hierarchy가 필요하다. 저자들은 tree supervision loss가 초기에 리프 가중치가 무의미할 때 학습 속도를 저해시키는 것을 발견했다. 그래서 tree supervision loss를 조절하는 tree supervision weight인 \(w_t\)가 \(0\)부터 \(0.5\)까지 선형적으로 증가하게 했다. \(\beta_t \in [0, 1]\)의 경우 선형적으로 줄어들게 했다.
원래 모델의 정확도가 재현 불가능 할 때, 모델을 \(\mathcal{L}_{\text{soft}}\)와 함께 다시 훈련시켰다.
Hierarchical softmax5와 달리 path-probability cross-entropy loss인 \(\mathcal{L}_{\text{soft}}\)는 약간 불균형적으로 계층 초기의 결정 가중치를 높이는 경향이 있었다. 이는 높은 계층에서 더 정확한 결정을 끌어냈다. 이는 Table 6에서 unseen classes의 성능에서 최대 16%의 정확도 상승으로 나타난다.
4. Experiments¶
4.1 Results¶
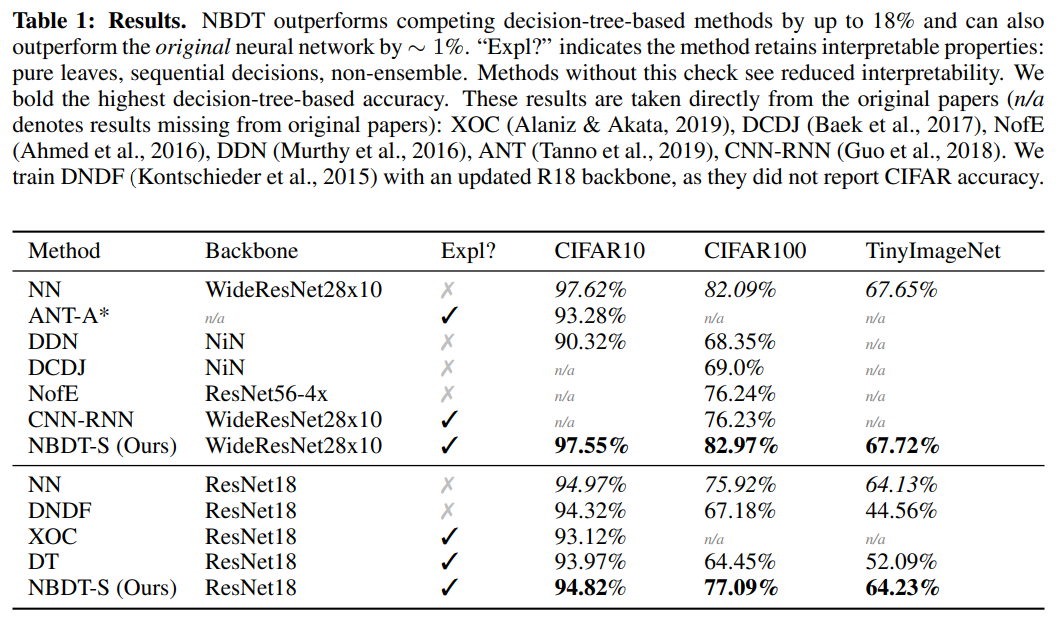
Small-scale Datasets에서 기존 모델보다 약 1%의 성능 향상이 있었으며, 설명 가능한 특성도 보존하고 있다.
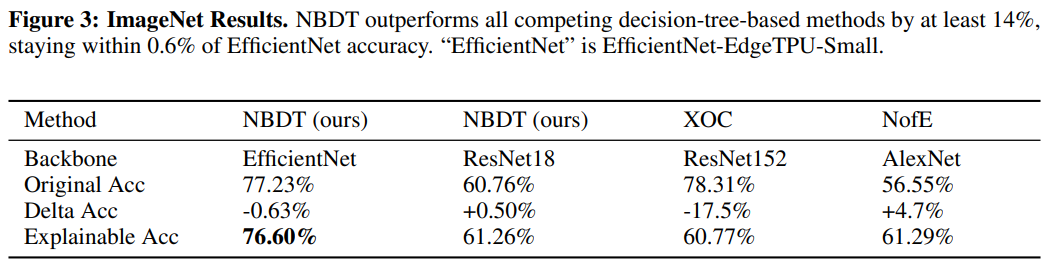
Large-scale Dataset의 Top-1 Accuracy에서 동일 Backbone을 가진 기존 SOTA와 비슷하거나 좋은 성능을 냈다. 다만 여기서 explainable accuracy가 무슨 것인지 나오지는 않아서 애매모호하다.
4.2 Analysis¶
높은 계층의 컨셉(e.g., Animal vs. Vehicle)에서 성능 향상이 있었다.
Comparison of Hierarchies¶
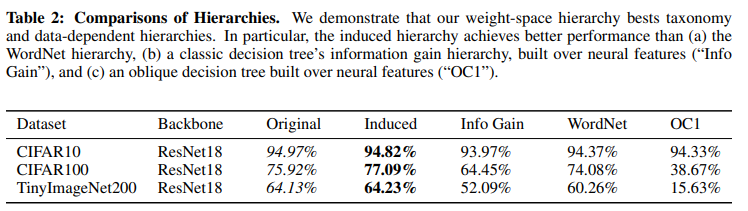
Tree를 어떤 방식으로 훈련 시켰는지 비교를 하자면, class weight로 Tree(Fig 1의 Soft)를 구성하는 것이 가장 좋은 성능을 보였다. OCI는 Fig 1의 Hard 방법, Info Gain은 고전적인 트리 그리고 WordNet은 사람이 구축한 계층 방법이다.
Comparison of Losses¶
Hierarchical softmax 보다 좋은 성능을 보였다.
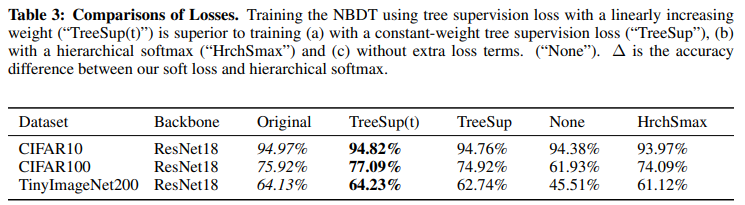
Hard Tree Supervision Loss 와 Soft Tree Supervision Loss의 차이
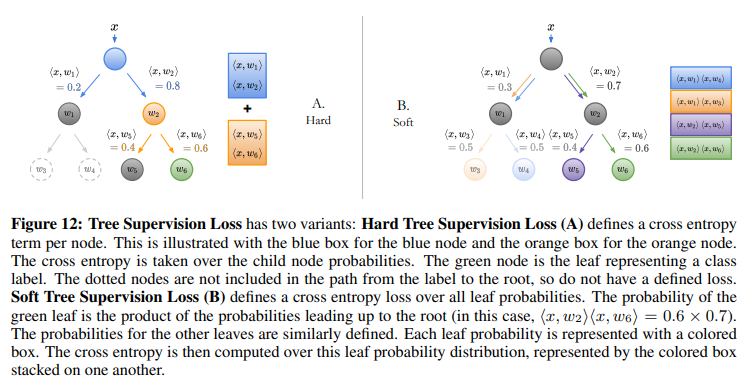
Original Neural Network¶
Tree supervision loss를 결합을 했을때 약간의 성능향상이 있었다.
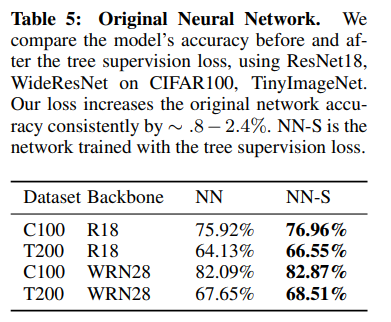
Zero-Shot Superclass Generalization¶
WordNet을 이용해 여러 개 클래스의 상위어(hypernym)로 Superclass를 정의했다. 그래서 unseen data가 내부 노드에서 잘 나뉘어 지는지 살펴보았다. 예를 들어, Turtle은 Animal vs. Vehicle 분기에서 Animal을 선택해야 한다.
비교를 위해 일반적인 신경망 네트워크는, 예측 레이블이 속한 superclass를 사용했다.
다만 노드의 비쥬얼 의미를 자세히 살펴볼 필요가 있다(Appendix B.2)
Induced hierarchy(Soft Tree)는 모델의 가중치를 사용하기 때문에, 중간 단계의 노드가 꼭 분리를 위한 특정 객체를 가르칠 필요가 없다. 즉, 아무 의미가 없을 수도 있다는 말이다. 게다가 WordNet을 사용했을 때, 예상치 못한 의미로 분리될 수가 있다. 이를 진단하기 위해 다음과 같이 4개의 스텝을 거친다.
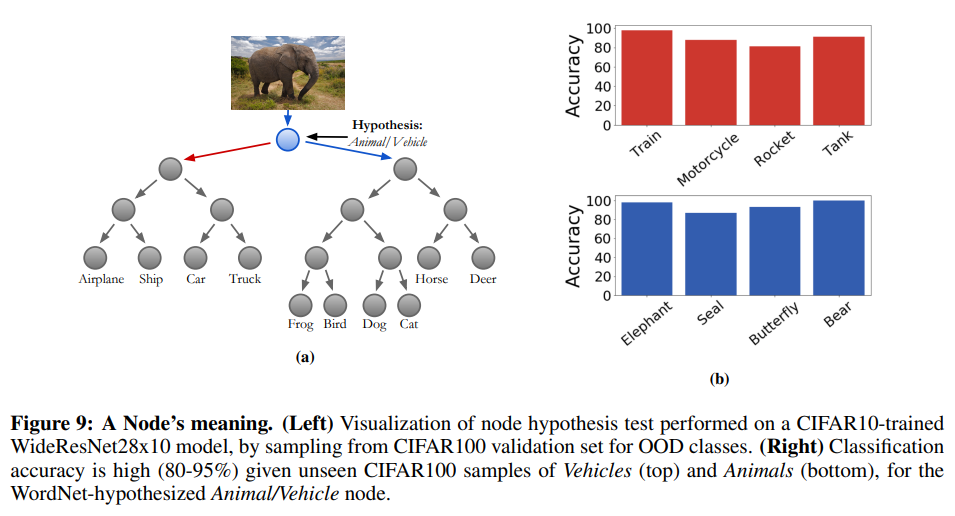
- 노드의 의미에 대한 가설을 세운다(e.g., Animal vs. Vehicle). 이 가설은 주어진 분류법에서 자동으로 계산되거나 각 자식 노드에 대해 자동으로 추론한다(Fig 9).
- 1단계에서 가정을 테스트하는 새로운 클래스로 데이터 세트를 수집한다. 수집한 데이터는 별도의 레이블에서 추출하기 때문에 OOD(Out-of-Distribution) 샘플이라고 한다.
- OOD 샘플을 노드로 전달하고, 각 샘플에 대해 선택된 자식 노드가 가설과 일치하는지 여부를 확인한다.
- 가설의 정확도는 올바른 자식 노드에 전달된 샘플의 비율이다. 정확도가 낮으면 다른 가설을 사용하여 반복한다.
Fig 9b에서 WordNet의 가설은 Animal(파랑) vs. Vehicle(빨강)이다. CIFAR100의 validation 세트로 OOD 샘플로 구성하여 CIFAR10데이터 세트를 사용해 훈련한 Tree를 테스트했다. 측정된 정확도는 가설과 Tree에서 분류된 superclass가 정확한지 검증 정확도라고 할 수 있다.
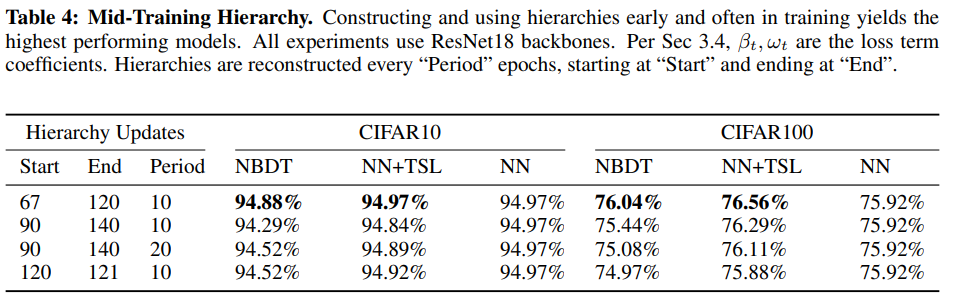
Mid-Training Hierarchy¶
미리 훈련된 가중치를 사용하지 않은 것을 비교했다.
5. Interpretability¶
복잡한 의사결정을 보다 작은 중간 단계의 의사결정으로 나눔으로써 Decision Tree는 인사이트를 제공한다. 그러나 중간 단계의 의사결정이 뉴럴 네트워크이기 때문에, 인사이트를 추출하기에 많은 어려움이 있다. 이를 해결하기 위해 Poursabzi-Sangdeh et al. (2018)6에서 제한 벤치마크와 interpretability 정의를 가져왔다.
인간이 예측의 유효성을 검증할 수 있는 경우 "해석 가능하다"라고 말할 수 있으며, 모델이 실수했을 때 인간이 이를 알 수가 있다. 해당 논문 저자의 컴퓨터 비전에 사용된 벤치마크를 가져왔고, 적용 결과 다음과 같다.
- Saliency 설명과 NBDT의 설명을 비교하면, 사람은 NBDT의 설명에서 더 정확하게 오분류를 찾아낼 수 있었다(Sec 5.1).
- NBDT의 엔트로피를 약간 수정해서 애매모호한 레이블을 탐지했다(Sec 5.2).
- 이미지 분류 문제에서 사람들은 NBDT의 예측을 더 선호했다(Sec 5.2 & 5.3).
이러한 분석 결과는 모델이 다음과 같은 특성을 보존하고 있다는 가정하에서 진행됐다.
- 개별적(discrete)이고 순차적인 결정: 하나의 path만 선택할 수 있다.
- 퓨어 노드(pure leaves): 하나의 path는 하나의 클래스만 선택할 수 있게 한다.
- 앙상블 예측이 아님: 예측과 원인의 귀착(attribution)이 서로 독립적이다.
모든 서베이 데이터는 CIFAR 10 데이터에 훈련된 ResNet18 모델을 사용했다.
5.1 Survey: Identifying Faulty Model Predictions¶
이 섹션에서는 Poursabzi-Sangdeh et al. (2018)6에서 언급한 다음 질문을 대답하려고 한다.
"How well can someone detect when the model has made a sizable mistake?"
모델이 상상한 실수를 저질렀을 때 사람은 얼마나 이를 잘 탐지할 수 있을까?
이 서베이에서는 사용자에게 2개의 정확히 분류된 이미지 그리고 1개의 틀리게 분류된 이미지가 주어진다. 사용자는 모델의 설명과 최종예측이 없는 상태에서 어떤 이미지가 잘 못 분류되었는지 예측해야 한다. Saliency maps의 경우 이미지가 맞든 틀리든 이미지에 대한 attribution을 표기하기 때문에 이 질문을 대답하기가 어렵다. 그러나 계층적(hierarchical) 방법은 합리적인 의사결정 시퀀스를 제공하기 때문에 이를 확인 할 수가 있다.
저자들은 각 설명기법에 대해 600개의 서베이 응답을 결과로 받았고, 유저들은 saliency maps와 클래스 확률을 줬을 때, 87개의 예측만이 정확하게 틀렸다는 것을 인지했다. 반면, 유저들에게 NBDT로 예측한 클래스와 자식 확률(예, Animal (90%) → Mammal (95%), 최종 리프 노드 예측은 주지 않는다)을 줬을 때, 237개의 이미지를 정확하게 틀렸다고 인지했다. 따라서 NBDT 방법이 모델이 일으킨 실수를 약 3배 더 잘 탐지할 수 있다.
비록 saliency maps보다 더 나은 결과를 보였지만, 아직도 363개의 예측에 대해서는 정확하게 판별하지 못했다. 약 37% NBDT의 에러는 최종 binary decision에서 나왔으며, 최종 결정을 유저들에게 제공하지 않았기에, leaf errors는 구별할 수가 없었다.
5.2 Survey: Explanation-Guided Image Classification¶
이 섹션에서는 Poursabzi-Sangdeh et al. (2018)6에서 언급한 다음 질문을 대답하려고 한다.
"To what extent do people follow a model’s predictions when it is beneficial to do so?"
사람들은 모델의 예측이 유익하다고 판단할때 이를 어느 정도까지 따를까?

첫 번째 서베이에서 유저들은 여러 블러 처리된 이미지(Fig 4)를 분류하게 된다. 600개의 이미지 중 163개만 맞춰서 저자들은 해당 과제가 어렵다는 것을 확인했다.
그다음 서베이로, 블러 처리된 이미지와 2개의 자료를 제공했다.
- 원래 뉴럴 네트워크의 예측 클래스와 saliency map
- NBDT 예측 클래스와 의사결정의 시퀀스(예, "Animal, Mammal, Cat")
두 모델이 다른 클래스를 예측된 데이터를 선정했다. 30%는 NBDT가 맞고, 원래 네트워크는 틀린 예제들이고, 또 다른 30%는 반대로 원래 네트워크가 맞고 NBDT가 틀렸다. 그리고 나머지 40%는 둘 다 틀린 예제들로 구성됐다. Fig 4처럼 이미지가 아주 많이 블러 처리됐기 때문에, 유저들은 모델에서 제공된 정보에 의존해 판별해야 했다.
정보를 줬을 때 유저들은 600개 중 255개(42.5%의 정확도)를 기록했다. 분석 결과 사람들은 NBDT의 설명된 예측을 더 신뢰했다. 600개 중 312개의 응답에서 NBDT의 예측을 더 신뢰했고, 167개는 기존 모델의 예측을, 그리고 119개의 응답은 모두 신뢰하지 않았다.
주의할 점은 비록 모델이 40%나 틀린 예측을 했음에도 불구하고 대부분의 유저가 대략 80% 정도 두 모델을 신뢰했다는 점이다. 이는 모델을 의존할 만큼 준비한 이미지가 충분히 흐렸다는 것을 증명해준다. 게다가 NBDT가 30%의 샘플만 맞췄음에도 불구하고, 52%의 응답자들은 NBDT 결정에 동의했는데(saliency maps는 28%), 이는 모델의 신뢰성에 향상을 의미한다.
5.3 Survey: Human-Diagnosed Level of Trust¶
NBDT의 예측 설명은 path를 순회(traverse)하는 것과 같다. 저자들은 참가자들에게 Figure 13처럼 믿을 만한 둘 중 하나의 전문가를 고르라고 했다(혹은 둘 다 안고를 수도 있음). 원래 모델과 NBDT 모델이 모두 같은 클래스를 예측한 데이터 샘플을 사용했다. 374개의 응답 중, 둘 중 어느 게 더 나았냐는 질문에는 65.9%가 NBDT의 설명을 더 선호했다. 잘못 분류된 샘플들에서 73.5%가 NBDT를 더 선호했다. 이는 사람은 NBDT를 더 선호한다는 이전의 서베이 결과들을 증명해주었다(Expert A. ResNet18, GradCAM / Expert B. NBDT).

5.4 Analysis: Identifying Faulty Dataset Labels¶

Fig 5처럼 모델의 퍼포먼스를 해치는 애매모호한 데이터들이 있다. 이런 데이터들을 찾아내기 위해서 NBDT의 결정 중 Entropy를 살펴보았다. 이는 원래 모델의 Entropy보다 애매모호함을 나타내기 위한 더 좋은 지표였다.
인사이트는 다음과 같다. 만약에 몇 가지 결정을 제외한 중간 결정 과정에서 높은 확실성을 가진다면, 그 결정들은 여러 동등하게 타당한 케이스 중에서 결정된 것이다. 따라서, 높은 "path entropy"를 가진 혹은 이질적인 entropy를 가진 샘플들을 애매모호한 레이블로 선정한다.

Fig 6에서 NBDT는 ImageNet의 애매모호한 레이블을 찾아낼 수 있다는 것을 보여준다. TinyImagenet200데이터로 훈련된 모델을 사용해서 가장 많은 혼돈을 유발하는 2개 클래스를 그렸다.
좌측에는 ResNet18를 실행 시켜 상위 2개의 클래스 엔트로피를 최대화하고 상위 2개의 클래스 엔트로피를 평균시킨 모든 클래스에서 엔트로피를 최소화한 샘플을 찾는다. 높은 불확실성을 가짐에도 불구하고, 절반의 클래스들이 "벌, 오렌지, 다리, 바나나, 리모컨"에서 생겼는데, 사람이 보았을 때 전혀 애매모호한 점이 없다.
우측에는 NBDT의 결과를 보여주는데, 각 노드 예측 분포의 엔트로피를 계산한다. 그리고 가장 큰 값과 가장 작은 값의 차이를 가지는 샘플을 선택한다. 그 결과, 절반의 이미지가 정말로 애매모호한 이미지들이 선택됐다. 이는 NBDT의 entropy가 더 많은 정보를 가지고 있다는 것을 보여준다.
느낀점¶
- 사람이 알기 쉬운 의사결정 나무를 Neural Network와 연결하려는 노력은 이전에 많았었는데, 이 논문은 뉴럴 넷을 따라 하는 shallow 모델 아니라 직접 뒷단에 연결한 다는 점에서 신선했음
- Vector Representation을 기반으로 트리를 만들어서 자칫 설명력이 부족할 뻔한 것을 WordNet을 사용하여 이를 보완함. 물론 WordNet에 없는 계층은 설명 못 한다는 점에서 아직 더 발전시켜야 함.
- 이 분야는 평가 방법이 어려운데, 특정 서베이를 이용하여 자신들의 모델이 왜 더 설명력이 좋고, 신뢰성이 높은지 수치화시킴
-
Probability Path: L25.4 The Probability of a Path ↩
-
Agglomerative clustering (1) Hierarchical clustering - Wikipedia (2) DMTM Lecture 12 Hierarchical clustering (3) [Python] Hierarchical clustering(계층적 군집분석) ↩