Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
Introduction & Related Work and Existing Datasets¶
Semantic parsing(SP) 은 자연어 처리(NLP)에서 가장 중요한 문제 중 하나다. 자연어 문장의 의미를 이해하고, 이와 동시에 의미있고 실행 가능한 쿼리(논리적 형태, SQL 쿼리 혹은 Python 코드 등)에 매핑해야한다.
-
지금까지 연구된 다른 데이터 세트의 문제점: 너무 작거나 Task가 쉽게 구성되어 있음
ATIS, GeoQuery: 너무 작고, semantic "matching"에 가까움
- 같은 데이터베이스를 훈련과 테스트 세트에 사용
- 같은 타겟 문장이 훈련과 테스트 세트에 등장
WikiSQL(Zhong et al., 2017)
- 심플한 쿼리: 한 개의 칼럼에 대한
SELECT, 집계(AGGREGATION), 조건문(WHERE) 밖에 없음 - 하나의 테이블 밖에 없음
- 자주 쓰이는
JOIN,GROUP BY,ORDER BY등 부재
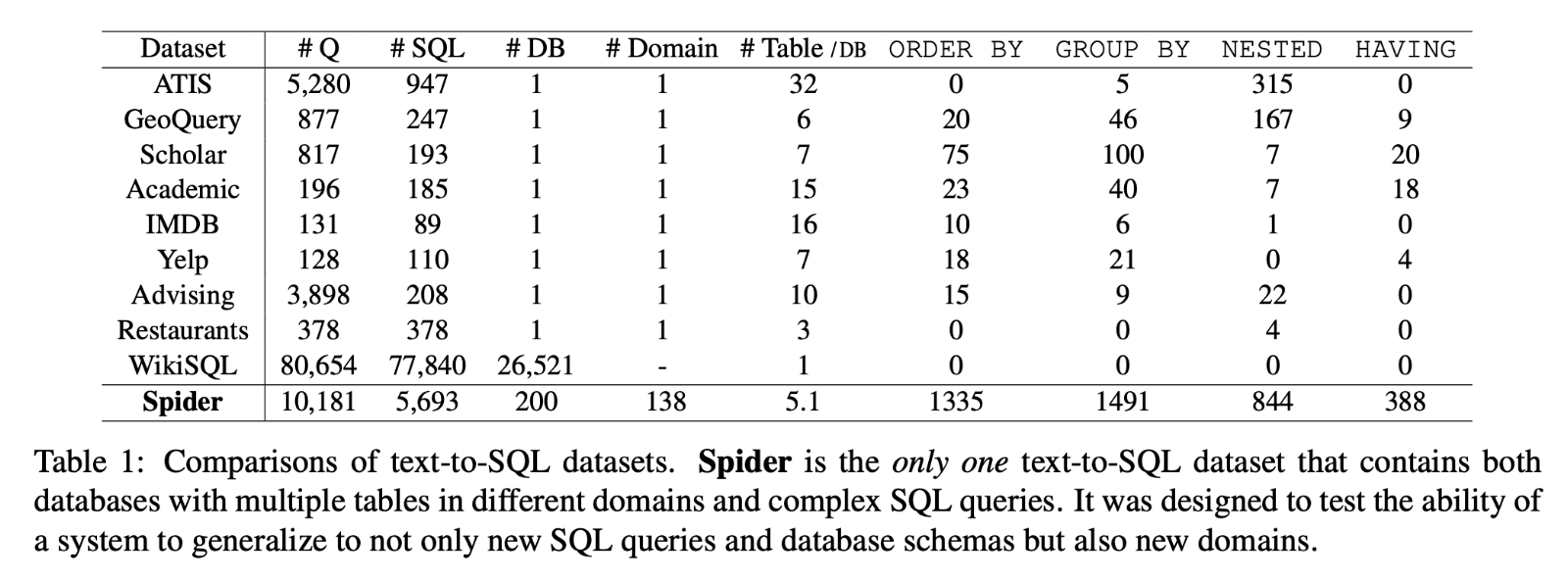
Comparisons of text-to-SQL datasets:
-
- 11개의 대학에서 같이 만들고, 대략 1,000시간 소요
- 특징: 200개의 데이터베이스, 10,181개의 자연어 질문, 5,693개의 난이도가 상이한 쿼리문
Corpus Construction¶
- Database Collection and Creation: 138개의 각기 다른 도메인을 가진 데이터베이스 수집
- 70개: 각기 다른 대학의 수업에서 사용된 복잡한 데이터베이스, SQL 온라인 튜토리얼 웹사이트, 온라인 csv파일, 교재 예시
- 40개: DatabaseAnswer http://www.databaseanswers.org/
- 90개: WikiSQL에 있는 500개의 다른 도메인에 있는 테이블들을 조합
- Question and SQL Annotation: SQL를 잘아는 컴퓨터 사이언스 학생들이 20-50개의 질문과 쿼리문 작성, 다양성 질문을 위해 템플릿 사용하지 않음
- SQL pattern coverage: SELECT, GROUP BY, HAVING, ORDER BY, LIMIT, JOIN, INTERSECT, EXCEPT, UNION, NOT IN, OR, AND, EXISTS, LIKE 등 요소와 nested 쿼리 포함
- SQL consistency: 같은 결과를 만드는 서로 다른 쿼리에 대해서 하나로 통일
-
Question clarity: 너무 애매모호 하거나 데이터베이스 밖의 지식을 요구하는 질문을 만들지 않음
- 애매모호한 질문: 부족한 정보로 인해 어떤 칼럼을 말하는지 혹은 어떤 조건인지 유추할 수 없는 경우
- 예를 들어, "What is the most popular class at University X?"의 경우, "popular" 이라는 단어의 정의가 불문명하다. 인기 있는 강의가 강의 평가가 높은 것을 뜻하는지 아니면 듣고 있는 학생수를 뜻하는지 모른다.
- 대신에, "What is the name of the class which the largest number of students are taking at University X?" 이라고 물어보면 "popular"는 학생수를 뜻하고, "student_enrollment"이라는 칼럼을 조건문으로 줘서 질문에 대답할 수 있게 된다.
- 이러한 문제를 multi-turn interactions 으로 해결할 필요성능 느낌(https://yale-lily.github.io/cosql)
-
데이터베이스 밖의 지식: 인간의 상식 같은 데이터베이스 밖에서 주어진 지식에 관련된 질문을 하지 않음
-
예를 들어, "Display the employee id for the employees who report to John"의 질문을 쿼리로 바꾸면 다음과 같다.
SELECT employee_id FROM employees WHERE manager_id = ( SELECT employee_id FROM employees WHERE first_name = 'John' )사람은 "X reports to Y"구문에서 "John"이 "employee manager"라는 상식을 유추할 수 있지만, 이는 데이터베이스로부터 알 수 없는 사실이다. 따라서 이러한 질문은 제외했다.
-
-
Annotation Tool: sqlite_web(https://github.com/coleifer/sqlite-web)
- SQL Review: 레이블을 만들었으면 다른 사람이 이를 검증, 중복된 쿼리문은 프로토콜에 따라 하나로 통일
- Question Review and Paraphrase: 레이블이 리뷰된 후, 질문이 문법적으로 문제가 없는지 확인, SQL과 대응하는지 확인, 마지막으로 paraphrased 된 질문을 추가해 다양성을 확보
- Final Review: 다른 경험이 많은 리뷰어들이 최종 리뷰, SQL 스크립트도 돌려서 annotation에 문제가 없는지 확인
- 애매모호한 질문: 부족한 정보로 인해 어떤 칼럼을 말하는지 혹은 어떤 조건인지 유추할 수 없는 경우
Dataset Statistics and Comparison¶
Introduction의 테이블 참고
Task Definition & Evaluation Metrics¶
- 쿼리문 생성에 관해서 모델 퍼포먼스 평가를 크게 하지 않음, SQL 구조와 칼럼 예측을 조금 더 중점적으로 봄
- 이전에도 말한 데이터베이스 외적 지식을 요구하는 질문은 제외(상식이나 일반 산술), 예를 들어 나이 계산
- Semantic Evaluation for Text-to-SQL with Distilled Test Suites 에서 나온 방법으로 2020.05.02부터 평가하기로 함
- Evalutation
- Component Matching: F1 score, 일부 순서에 상관없이 구문만 잘 맞추면 됨, 값을 맞출 필요는 없음
- e.g.
SELECT avg(col1), max(col2), min(col1)=SELECT avg(col1), min(col1), max(col2)
- e.g.
- Exact Matching: 정확한 일치도
- Execution Accuracy: 값의 정확한 일치, 위 두 평가 방법에서는 값을 일치 안해도 됨
- Component Matching: F1 score, 일부 순서에 상관없이 구문만 잘 맞추면 됨, 값을 맞출 필요는 없음
- SQL Hardness Criteria: 난이도를 SQL 구문, 선택문, 조건문 개수에 따라서 나눔
Methods & Experimental Results and Discussion¶
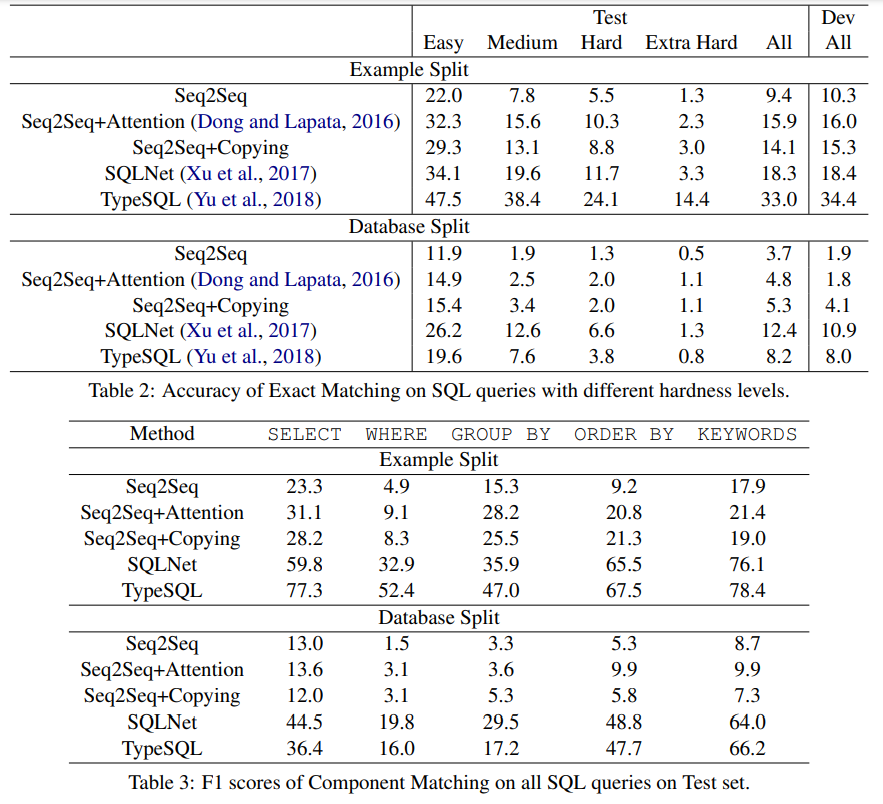
- 기존의 데이터세트에서 좋은 평가를 받은 방법들로 실험을 진행
- 재밌는 부분은 Example split와 Database split 방법으로 나눴고, 대부분 모델들이 후자에서 안 좋은 평가를 기록함, 즉, 훈련 세트에서 학습한 데이터베이스가 테스트에도 있을 경우, 퍼포먼스에 영향을 미쳤다고 볼 수 있음
- Example split: question을 기반으로 train, test 나눔
- Database split: database 기반으로 train, test 나눔